 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLate Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition
Aug 19, 2020


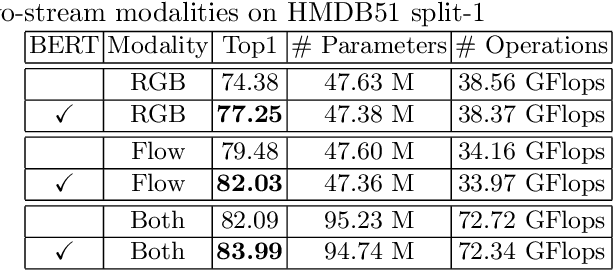
In this work, we combine 3D convolution with late temporal modeling for action recognition. For this aim, we replace the conventional Temporal Global Average Pooling (TGAP) layer at the end of 3D convolutional architecture with the Bidirectional Encoder Representations from Transformers (BERT) layer in order to better utilize the temporal information with BERT's attention mechanism. We show that this replacement improves the performances of many popular 3D convolution architectures for action recognition, including ResNeXt, I3D, SlowFast and R(2+1)D. Moreover, we provide the-state-of-the-art results on both HMDB51 and UCF101 datasets with 85.10% and 98.69% top-1 accuracy, respectively. The code is publicly available.
Mind Your Manners! A Dataset and A Continual Learning Approach for Assessing Social Appropriateness of Robot Actions
Jul 24, 2020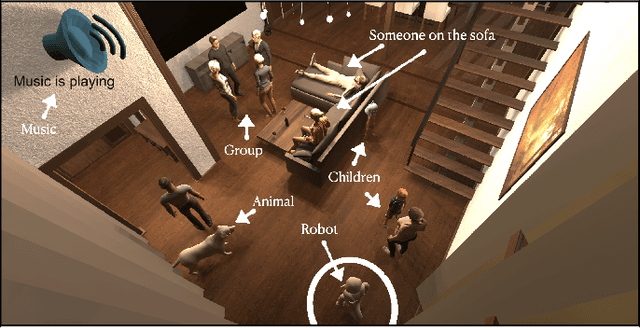
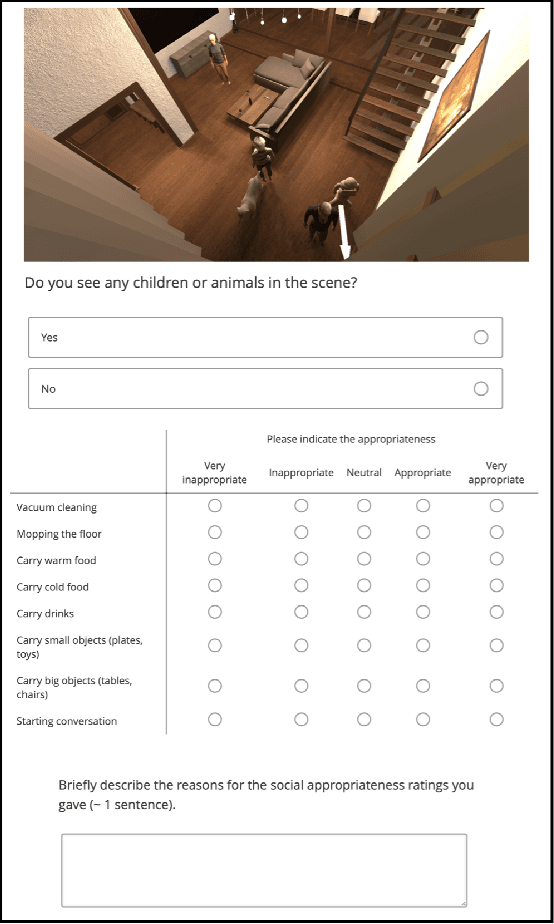
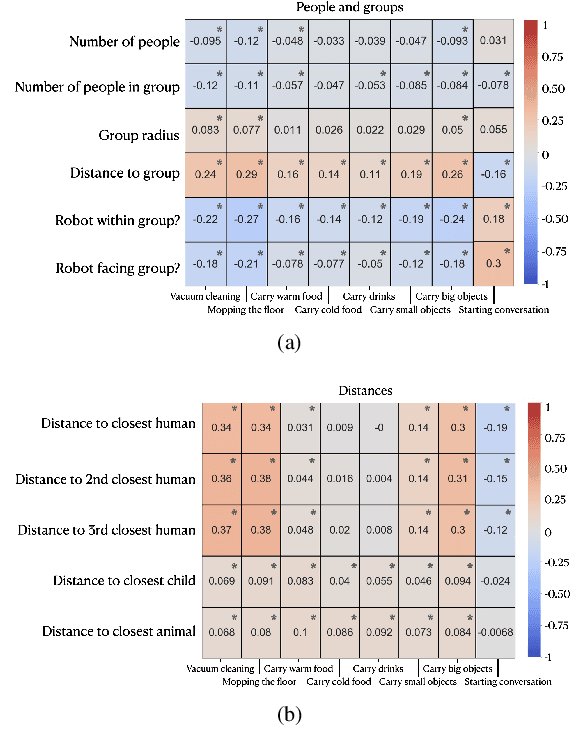
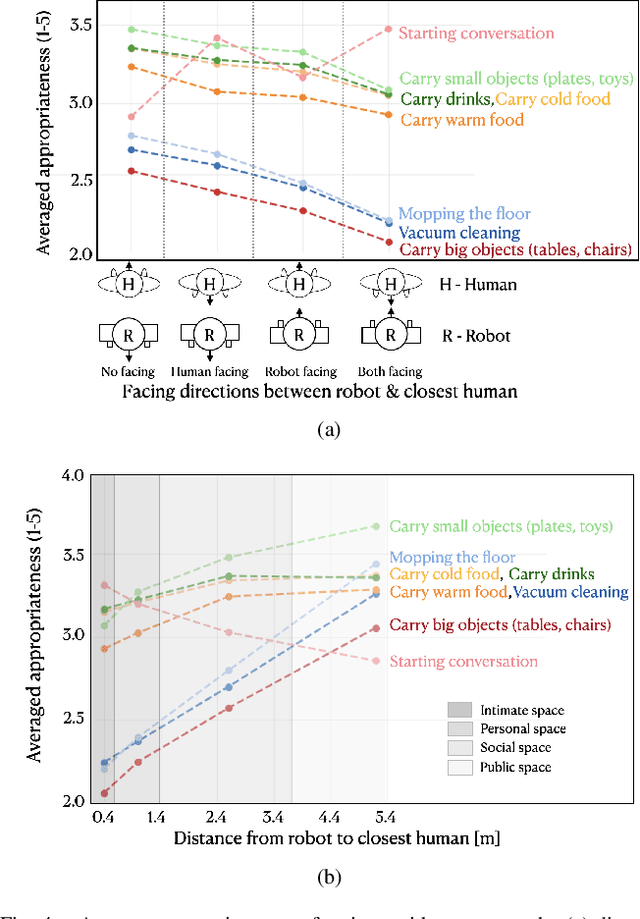
To date, endowing robots with an ability to assess social appropriateness of their actions has not been possible. This has been mainly due to (i) the lack of relevant and labelled data, and (ii) the lack of formulations of this as a lifelong learning problem. In this paper, we address these two issues. We first introduce the Socially Appropriate Domestic Robot Actions dataset (MANNERS-DB), which contains appropriateness labels of robot actions annotated by humans. To be able to control but vary the configurations of the scenes and the social settings, MANNERS-DB has been created utilising a simulation environment by uniformly sampling relevant contextual attributes. Secondly, we train and evaluate a baseline Bayesian Neural Network (BNN) that estimates social appropriateness of actions in the MANNERS-DB. Finally, we formulate learning social appropriateness of actions as a continual learning problem using the uncertainty of the BNN parameters. The experimental results show that the social appropriateness of robot actions can be predicted with a satisfactory level of precision. Our work takes robots one step closer to a human-like understanding of (social) appropriateness of actions, with respect to the social context they operate in. To facilitate reproducibility and further progress in this area, the MANNERS-DB, the trained models and the relevant code will be made publicly available.
ALET : A Dataset, a Baseline and a Usecase for Tool Detection in the Wild
Oct 25, 2019
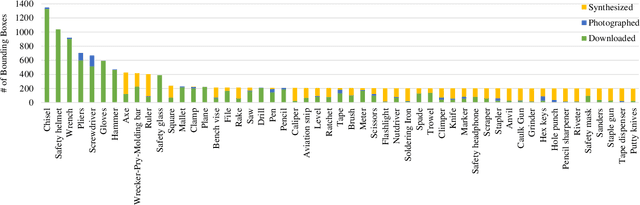

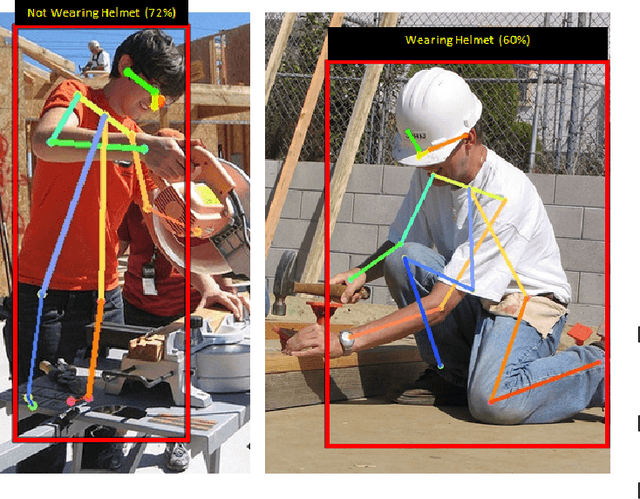
Robots collaborating with humans in realistic environments will need to be able to detect the tools that can be used and manipulated. However, there is no available dataset or study that addresses this challenge in real settings. In this paper, we fill this gap by providing an extensive dataset (METU-ALET) for detecting farming, gardening, office, stonemasonry, vehicle, woodworking and workshop tools. The scenes correspond to sophisticated environments with or without humans using the tools. The scenes we consider introduce several challenges for object detection, including the small scale of the tools, their articulated nature, occlusion, inter-class invariance, etc. Moreover, we train and compare several state of the art deep object detectors (including Faster R-CNN, YOLO and RetinaNet) on our dataset. We observe that the detectors have difficulty in detecting especially small-scale tools or tools that are visually similar to parts of other tools. This in turn supports the importance of our dataset and paper. With the dataset, the code and the trained models, our work provides a basis for further research into tools and their use in robotics applications.
Generating Positive Bounding Boxes for Balanced Training of Object Detectors
Sep 21, 2019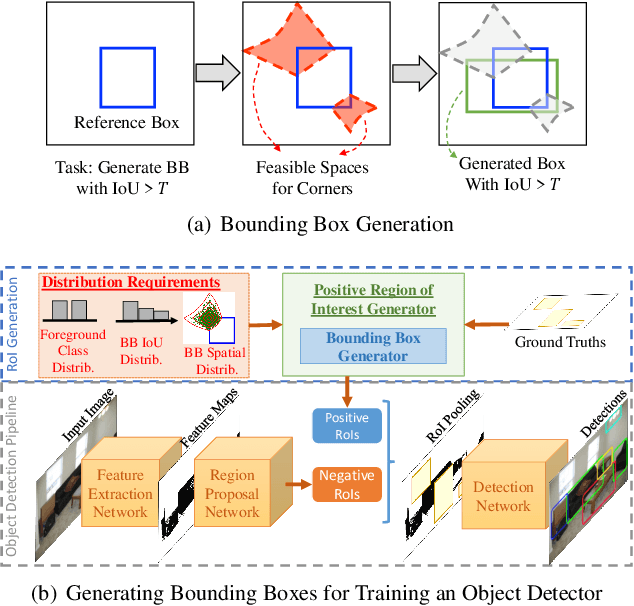
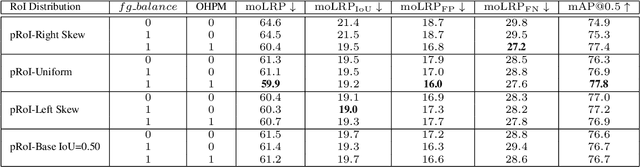
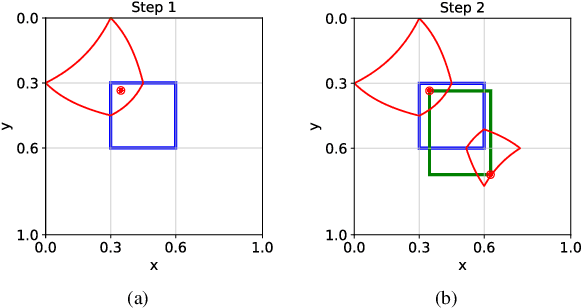

Two-stage deep object detectors generate a set of regions-of-interest (RoI) in the first stage, then, in the second stage, identify objects among the proposed RoIs that sufficiently overlap with a ground truth (GT) box. The second stage is known to suffer from a bias towards RoIs that have low intersection-over-union (IoU) with the associated GT boxes. To address this issue, we first propose a sampling method to generate bounding boxes (BB) that overlap with a given reference box more than a given IoU threshold. Then, we use this BB generation method to develop a positive RoI (pRoI) generator that produces RoIs following any desired spatial or IoU distribution, for the second-stage. We show that our pRoI generator is able to simulate other sampling methods for positive examples such as hard example mining and prime sampling. Using our generator as an analysis tool, we show that (i) IoU imbalance has an adverse effect on performance, (ii) hard positive example mining improves the performance only for certain input IoU distributions, and (iii) the imbalance among the foreground classes has an adverse effect on performance and that it can be alleviated at the batch level. Finally, we train Faster R-CNN using our pRoI generator and, compared to conventional training, obtain better or on-par performance for low IoUs and significant improvements for higher IoUs (e.g. for $IoU=0.8$, $\mathrm{mAP@0.8}$ improves by $10.9\%$). The code will be made publicly available.
Imbalance Problems in Object Detection: A Review
Aug 31, 2019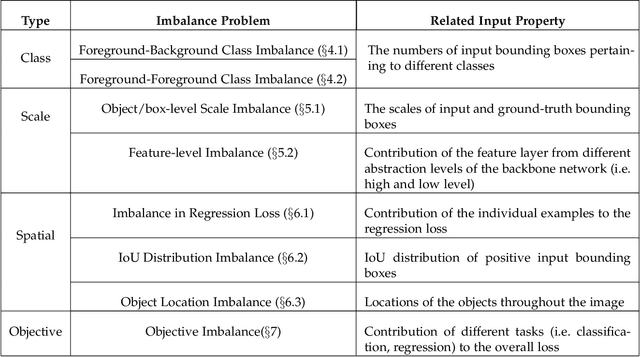
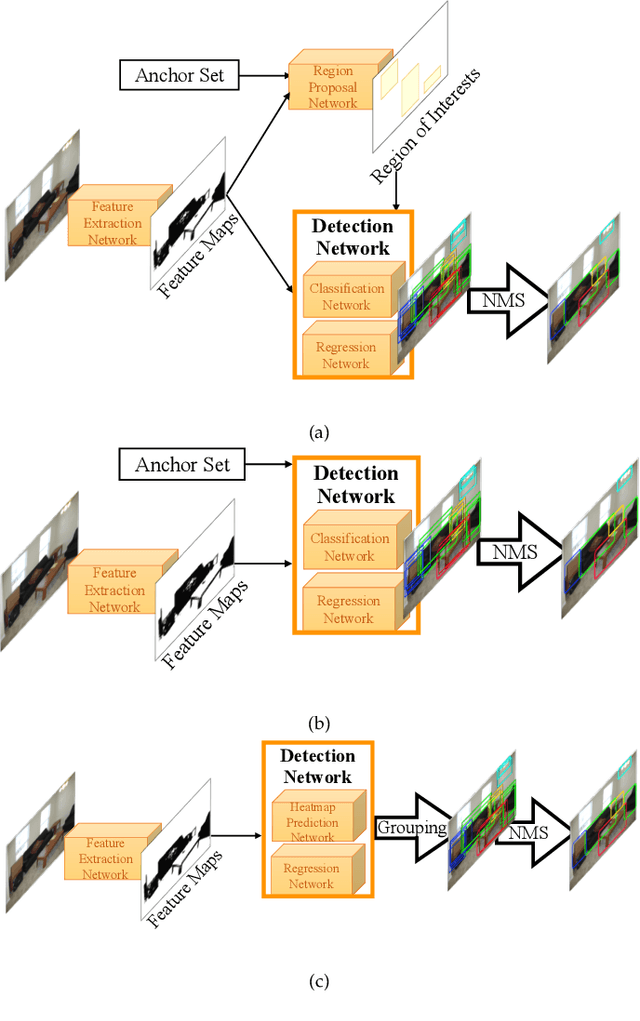
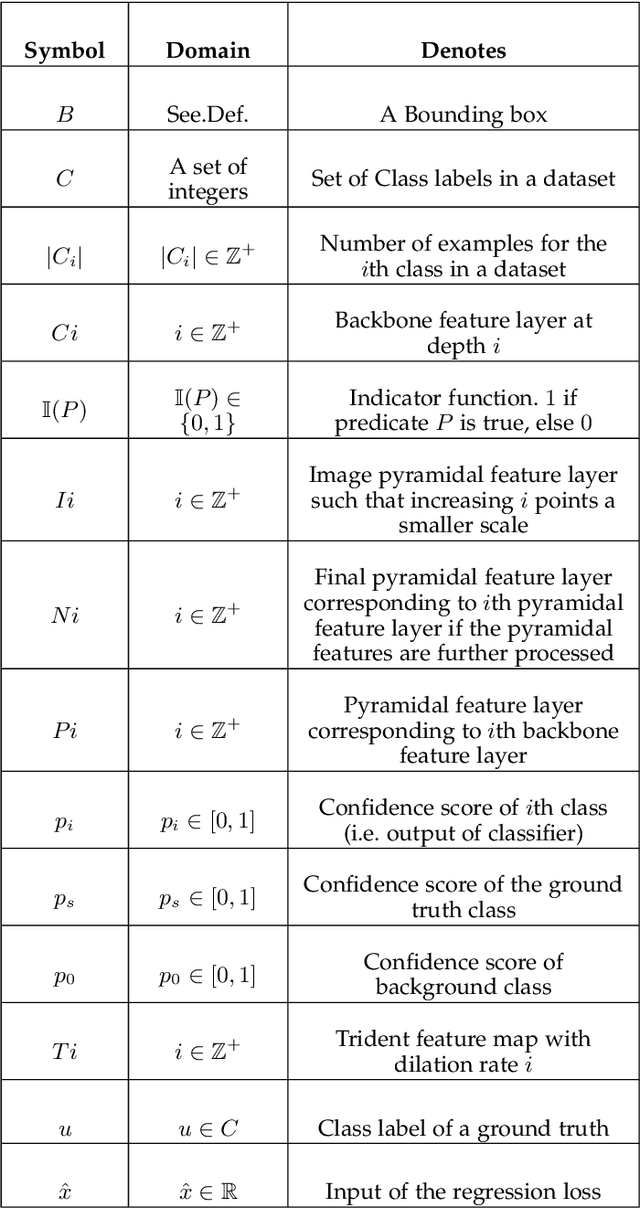
In this paper, we present a comprehensive review of the imbalance problems in object detection. To analyze the problems in a systematic manner, we introduce two taxonomies; one for the problems and the other for the proposed solutions. Following the taxonomy for the problems, we discuss each problem in depth and present a unifying yet critical perspective on the solutions in the literature. In addition, we identify major open issues regarding the existing imbalance problems as well as imbalance problems that have not been discussed before. Moreover, in order to keep our review up to date, we provide an accompanying webpage which categorizes papers addressing imbalance problems, according to our problem-based taxonomy. Researchers can track newer studies on this webpage available at: https://github.com/kemaloksuz/ObjectDetectionImbalance .
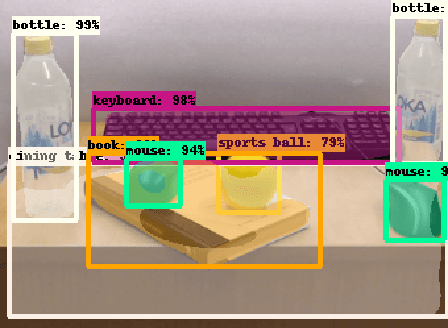
Searching for Ambiguous Objects in Videos using Relational Referring Expressions
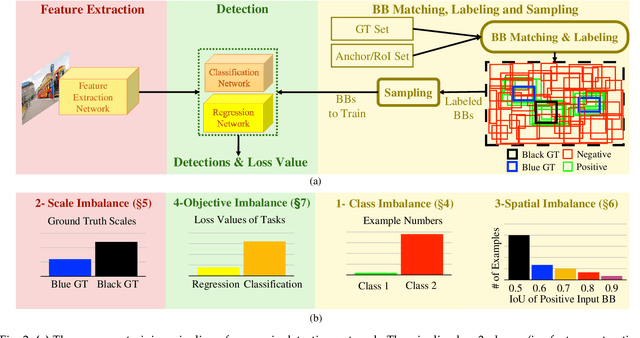
Aug 20, 2019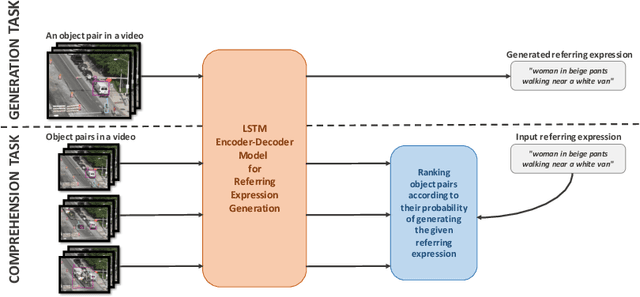

Humans frequently use referring (identifying) expressions to refer to objects. Especially in ambiguous settings, humans prefer expressions (called relational referring expressions) that describe an object with respect to a distinguishing, unique object. Unlike studies on video object search using referring expressions, in this paper, our focus is on (i) relational referring expressions in highly ambiguous settings, and (ii) methods that can both generate and comprehend a referring expression. For this goal, we first introduce a new dataset for video object search with referring expressions that includes numerous copies of the objects, making it difficult to use non-relational expressions. Moreover, we train two baseline deep networks on this dataset, which show promising results. Finally, we propose a deep attention network that significantly outperforms the baselines on our dataset. The dataset and the codes are available at https://github.com/hazananayurt/viref.
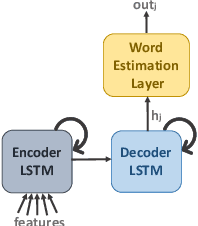
Learning to Generate Unambiguous Spatial Referring Expressions for Real-World Environments
Apr 15, 2019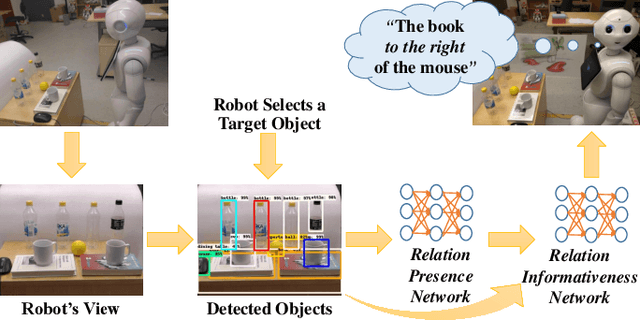


Referring to objects in a natural and unambiguous manner is crucial for effective human-robot interaction. Previous research on learning-based referring expressions has focused primarily on comprehension tasks, while generating referring expressions is still mostly limited to rule-based methods. In this work, we propose a two-stage approach that relies on deep learning for estimating spatial relations to describe an object naturally and unambiguously with a referring expression. We evaluate our method in ambiguous environments (e.g., environments that include very similar objects with similar relationships) relative to a state-of-the-art algorithm. We show that our method generates referring expressions that people find to be more accurate ($\sim$30% better) and would prefer to use ($\sim$32% more often).
COSMO: Contextualized Scene Modeling with Boltzmann Machines
Dec 19, 2018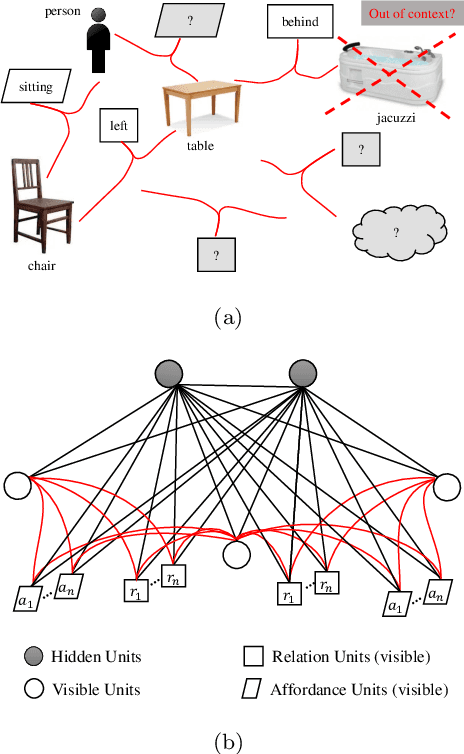
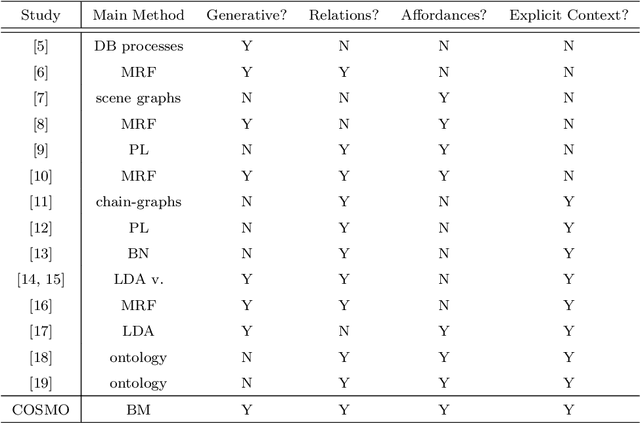
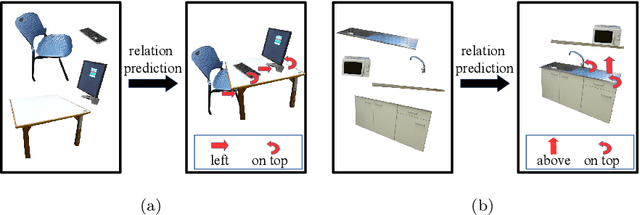
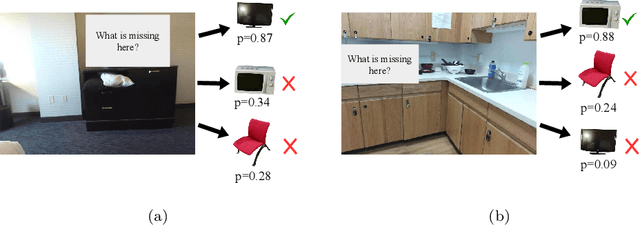
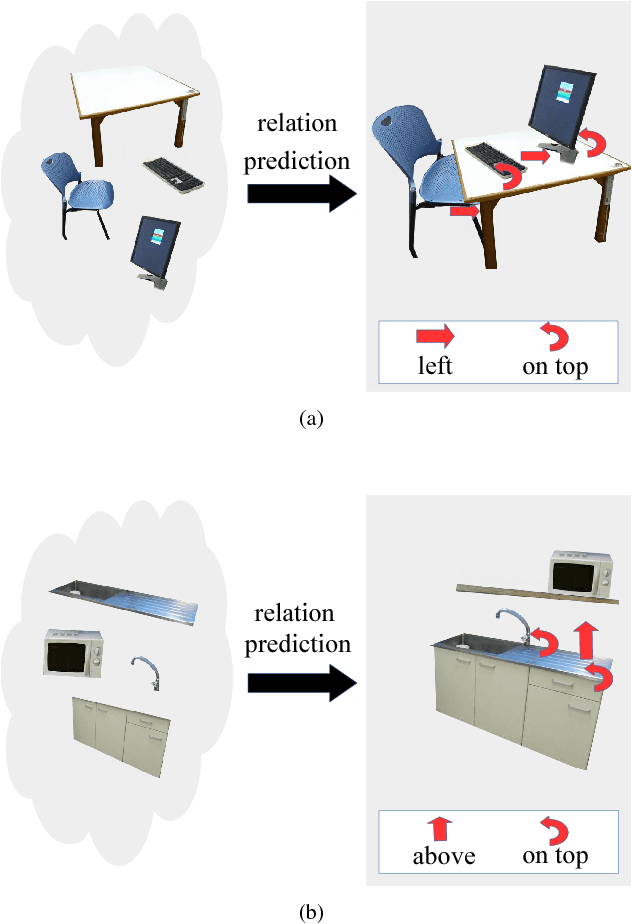
Scene modeling is very crucial for robots that need to perceive, reason about and manipulate the objects in their environments. In this paper, we adapt and extend Boltzmann Machines (BMs) for contextualized scene modeling. Although there are many models on the subject, ours is the first to bring together objects, relations, and affordances in a highly-capable generative model. For this end, we introduce a hybrid version of BMs where relations and affordances are introduced with shared, tri-way connections into the model. Moreover, we contribute a dataset for relation estimation and modeling studies. We evaluate our method in comparison with several baselines on object estimation, out-of-context object detection, relation estimation, and affordance estimation tasks. Moreover, to illustrate the generative capability of the model, we show several example scenes that the model is able to generate.
What is in the scene? A Hybrid Deep Boltzmann Machine For Contextualized Scene Modeling
Aug 20, 2018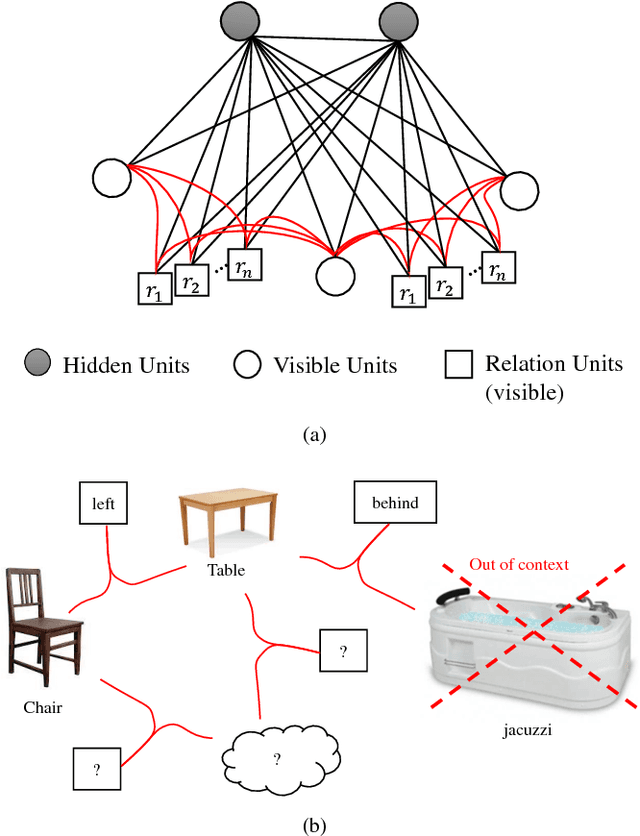
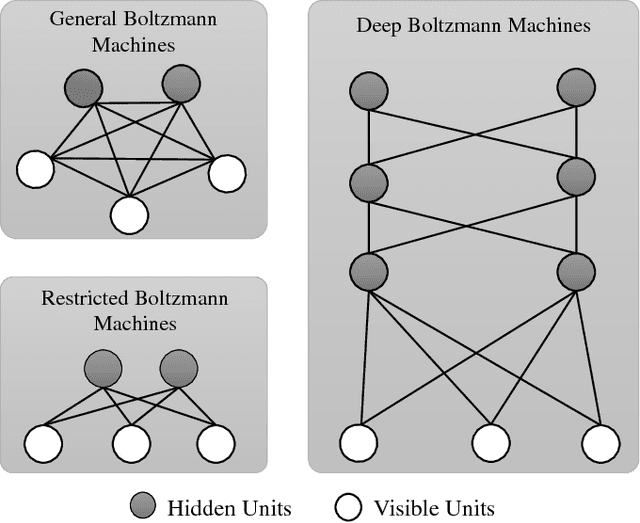

Scene models allow robots to reason about what is in the scene, what else should be in it, and what should not be in it. In this paper, we propose a hybrid Boltzmann Machine (BM) for scene modeling where relations between objects are integrated. To be able to do that, we extend BM to include tri-way edges between visible (object) nodes and make the network to share the relations across different objects. We evaluate our method against several baseline models (Deep Boltzmann Machines, and Restricted Boltzmann Machines) on a scene classification dataset, and show that it performs better in several scene reasoning tasks.
CINet: A Learning Based Approach to Incremental Context Modeling in Robots
Jul 29, 2018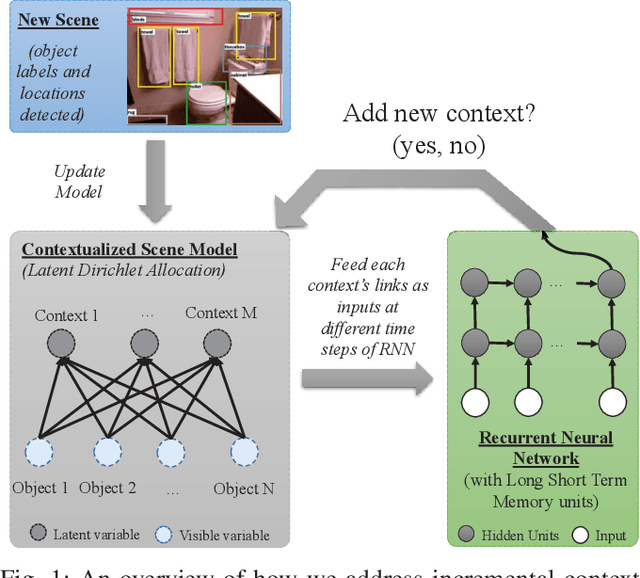

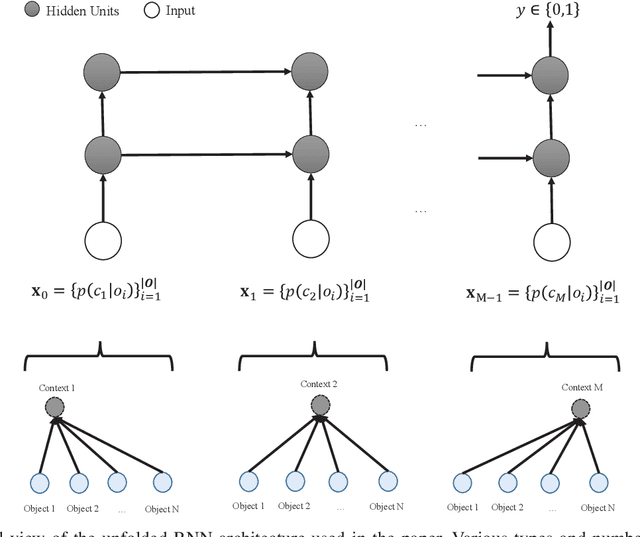
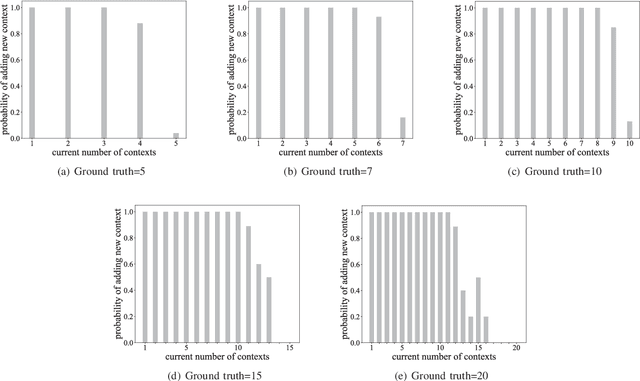
There have been several attempts at modeling context in robots. However, either these attempts assume a fixed number of contexts or use a rule-based approach to determine when to increment the number of contexts. In this paper, we pose the task of when to increment as a learning problem, which we solve using a Recurrent Neural Network. We show that the network successfully (with 98\% testing accuracy) learns to predict when to increment, and demonstrate, in a scene modeling problem (where the correct number of contexts is not known), that the robot increments the number of contexts in an expected manner (i.e., the entropy of the system is reduced). We also present how the incremental model can be used for various scene reasoning tasks.