 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes AI Applications Acceptable or Unacceptable? A Predictive Moral Framework
Aug 26, 2025As artificial intelligence rapidly transforms society, developers and policymakers struggle to anticipate which applications will face public moral resistance. We propose that these judgments are not idiosyncratic but systematic and predictable. In a large, preregistered study (N = 587, U.S. representative sample), we used a comprehensive taxonomy of 100 AI applications spanning personal and organizational contexts-including both functional uses and the moral treatment of AI itself. In participants' collective judgment, applications ranged from highly unacceptable to fully acceptable. We found this variation was strongly predictable: five core moral qualities-perceived risk, benefit, dishonesty, unnaturalness, and reduced accountability-collectively explained over 90% of the variance in acceptability ratings. The framework demonstrated strong predictive power across all domains and successfully predicted individual-level judgments for held-out applications. These findings reveal that a structured moral psychology underlies public evaluation of new technologies, offering a powerful tool for anticipating public resistance and guiding responsible innovation in AI.
AI Models Exceed Individual Human Accuracy in Predicting Everyday Social Norms
Aug 26, 2025A fundamental question in cognitive science concerns how social norms are acquired and represented. While humans typically learn norms through embodied social experience, we investigated whether large language models can achieve sophisticated norm understanding through statistical learning alone. Across two studies, we systematically evaluated multiple AI systems' ability to predict human social appropriateness judgments for 555 everyday scenarios by examining how closely they predicted the average judgment compared to each human participant. In Study 1, GPT-4.5's accuracy in predicting the collective judgment on a continuous scale exceeded that of every human participant (100th percentile). Study 2 replicated this, with Gemini 2.5 Pro outperforming 98.7% of humans, GPT-5 97.8%, and Claude Sonnet 4 96.0%. Despite this predictive power, all models showed systematic, correlated errors. These findings demonstrate that sophisticated models of social cognition can emerge from statistical learning over linguistic data alone, challenging strong versions of theories emphasizing the exclusive necessity of embodied experience for cultural competence. The systematic nature of AI limitations across different architectures indicates potential boundaries of pattern-based social understanding, while the models' ability to outperform nearly all individual humans in this predictive task suggests that language serves as a remarkably rich repository for cultural knowledge transmission.
Generative Adversarial Networks for Image-to-Image Translation on Multi-Contrast MR Images - A Comparison of CycleGAN and UNIT
Jun 20, 2018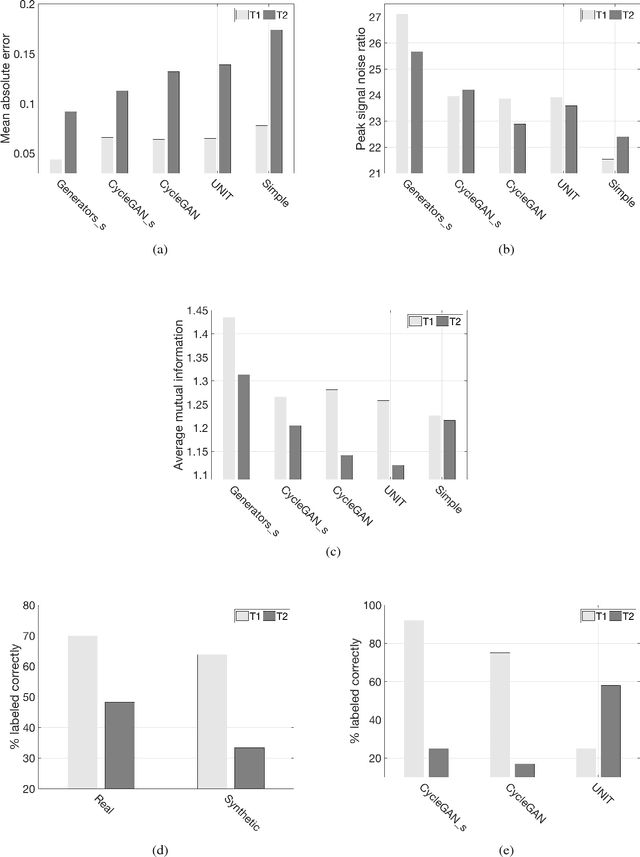
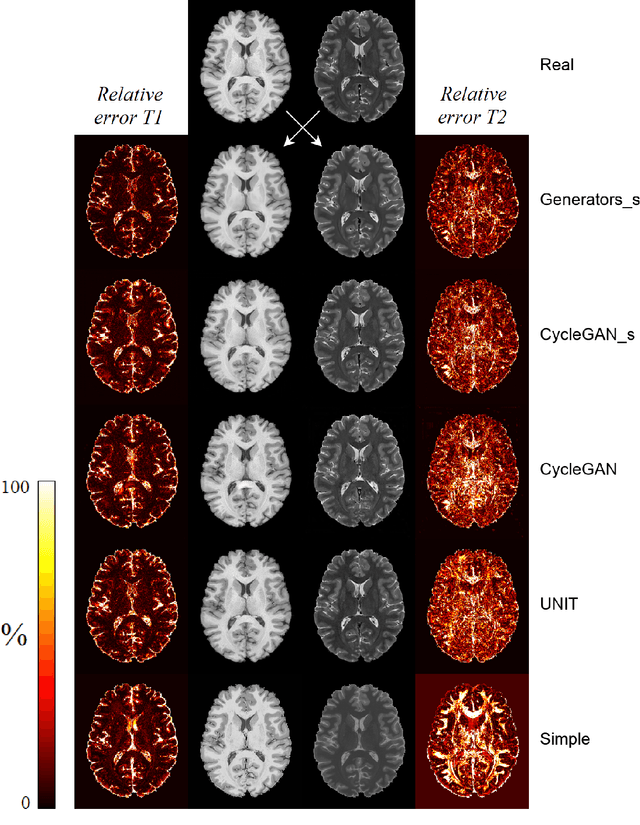
In medical imaging, a general problem is that it is costly and time consuming to collect high quality data from healthy and diseased subjects. Generative adversarial networks (GANs) is a deep learning method that has been developed for synthesizing data. GANs can thereby be used to generate more realistic training data, to improve classification performance of machine learning algorithms. Another application of GANs is image-to-image translations, e.g. generating magnetic resonance (MR) images from computed tomography (CT) images, which can be used to obtain multimodal datasets from a single modality. Here, we evaluate two unsupervised GAN models (CycleGAN and UNIT) for image-to-image translation of T1- and T2-weighted MR images, by comparing generated synthetic MR images to ground truth images. We also evaluate two supervised models; a modification of CycleGAN and a pure generator model. A small perceptual study was also performed to evaluate how visually realistic the synthesized images are. It is shown that the implemented GAN models can synthesize visually realistic MR images (incorrectly labeled as real by a human). It is also shown that models producing more visually realistic synthetic images not necessarily have better quantitative error measurements, when compared to ground truth data. Code is available at https://github.com/simontomaskarlsson/GAN-MRI