 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards understanding deep learning with the natural clustering prior
Mar 15, 2022

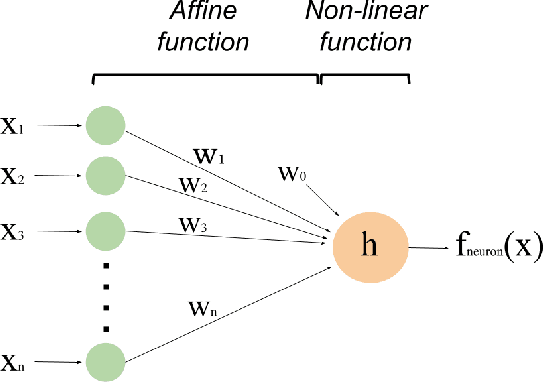
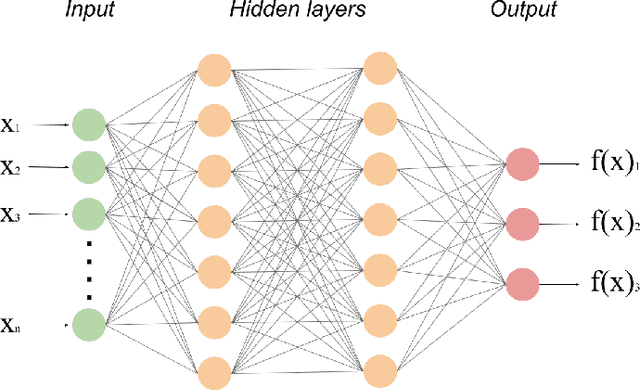
The prior knowledge (a.k.a. priors) integrated into the design of a machine learning system strongly influences its generalization abilities. In the specific context of deep learning, some of these priors are poorly understood as they implicitly emerge from the successful heuristics and tentative approximations of biological brains involved in deep learning design. Through the lens of supervised image classification problems, this thesis investigates the implicit integration of a natural clustering prior composed of three statements: (i) natural images exhibit a rich clustered structure, (ii) image classes are composed of multiple clusters and (iii) each cluster contains examples from a single class. The decomposition of classes into multiple clusters implies that supervised deep learning systems could benefit from unsupervised clustering to define appropriate decision boundaries. Hence, this thesis attempts to identify implicit clustering abilities, mechanisms and hyperparameters in deep learning systems and evaluate their relevance for explaining the generalization abilities of these systems. We do so through an extensive empirical study of the training dynamics as well as the neuron- and layer-level representations of deep neural networks. The resulting collection of experiments provides preliminary evidence for the relevance of the natural clustering prior for understanding deep learning.
On layer-level control of DNN training and its impact on generalization
Jun 05, 2018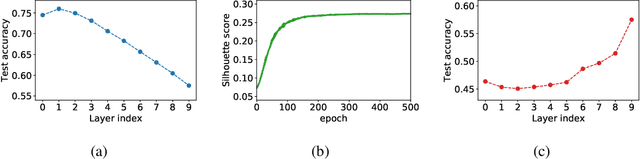
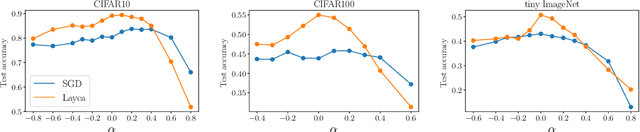
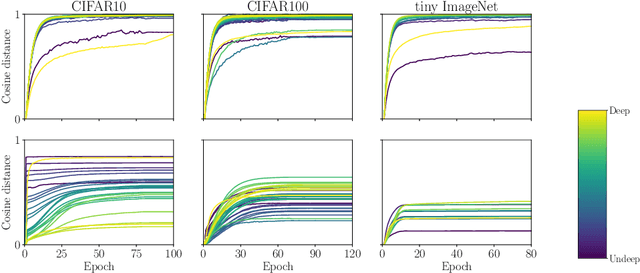
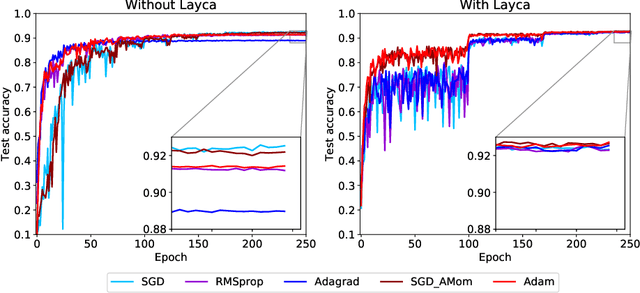
The generalization ability of a neural network depends on the optimization procedure used for training it. For practitioners and theoreticians, it is essential to identify which properties of the optimization procedure influence generalization. In this paper, we observe that prioritizing the training of distinct layers in a network significantly impacts its generalization ability, sometimes causing differences of up to 30% in test accuracy. In order to better monitor and control such prioritization, we propose to define layer-level training speed as the rotation rate of the layer's weight vector (denoted by layer rotation rate hereafter), and develop Layca, an optimization algorithm that enables direct control over it through each layer's learning rate parameter, without being affected by gradient propagation phenomena (e.g. vanishing gradients). We show that controlling layer rotation rates enables Layca to significantly outperform SGD with the same amount of learning rate tuning on three different tasks (up to 10% test error improvement). Furthermore, we provide experiments that suggest that several intriguing observations related to the training of deep models, i.e. the presence of plateaus in learning curves, the impact of weight decay, and the bad generalization properties of adaptive gradient methods, are all due to specific configurations of layer rotation rates. Overall, our work reveals that layer rotation rates are an important factor for generalization, and that monitoring it should be a key component of any deep learning experiment.