 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Distributed Representations to Disambiguate Biomedical and Clinical Concepts
Aug 19, 2016
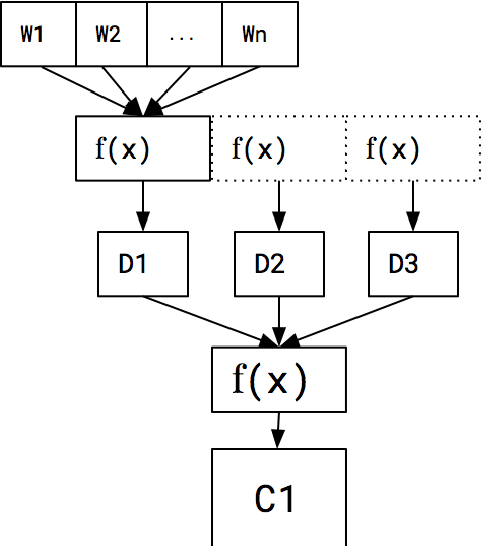

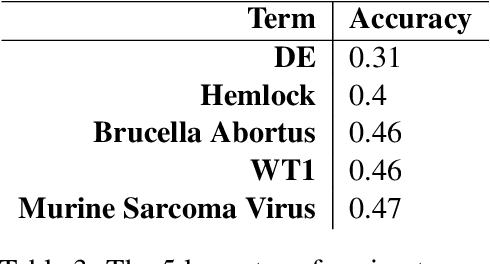
In this paper, we report a knowledge-based method for Word Sense Disambiguation in the domains of biomedical and clinical text. We combine word representations created on large corpora with a small number of definitions from the UMLS to create concept representations, which we then compare to representations of the context of ambiguous terms. Using no relational information, we obtain comparable performance to previous approaches on the MSH-WSD dataset, which is a well-known dataset in the biomedical domain. Additionally, our method is fast and easy to set up and extend to other domains. Supplementary materials, including source code, can be found at https: //github.com/clips/yarn
* 6 pages, 1 figure, presented at the 15th Workshop on Biomedical Natural Language Processing, Berlin 2016
Bilingual Learning of Multi-sense Embeddings with Discrete Autoencoders
Mar 30, 2016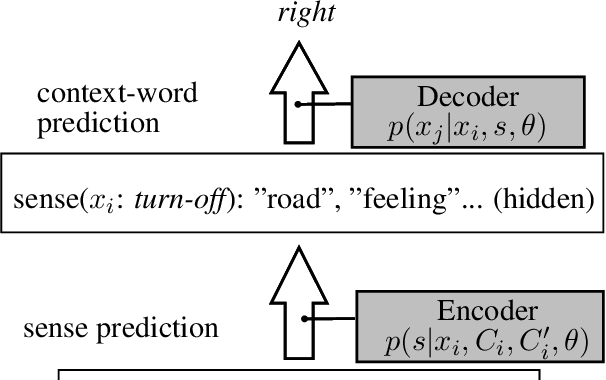
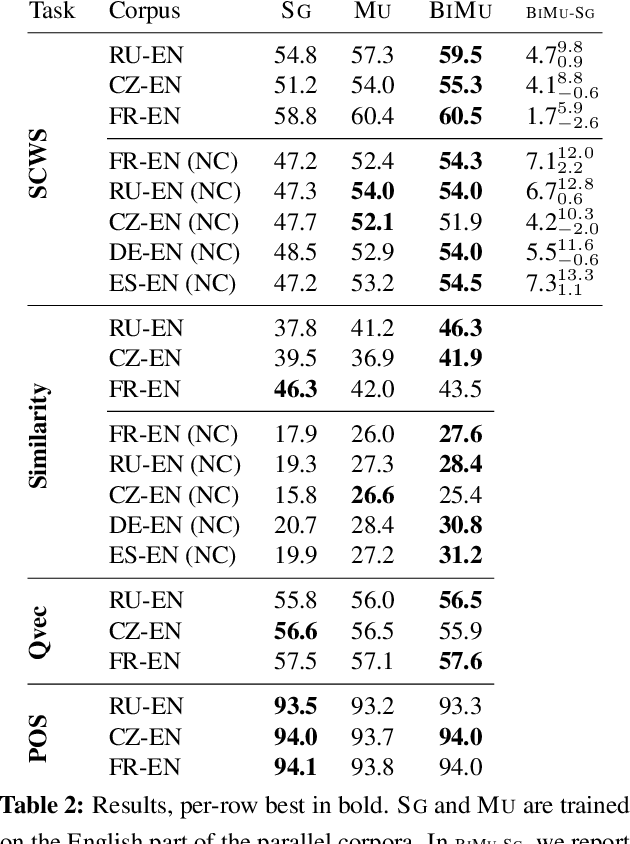
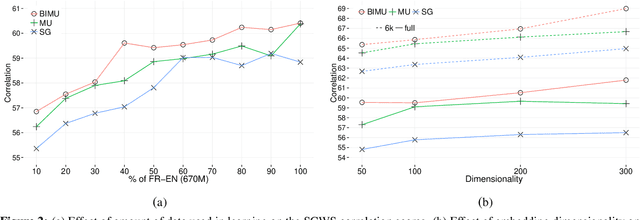
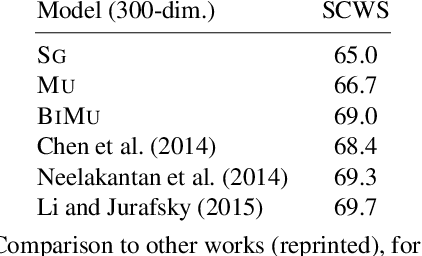
We present an approach to learning multi-sense word embeddings relying both on monolingual and bilingual information. Our model consists of an encoder, which uses monolingual and bilingual context (i.e. a parallel sentence) to choose a sense for a given word, and a decoder which predicts context words based on the chosen sense. The two components are estimated jointly. We observe that the word representations induced from bilingual data outperform the monolingual counterparts across a range of evaluation tasks, even though crosslingual information is not available at test time.
Word Representations, Tree Models and Syntactic Functions
Feb 05, 2016
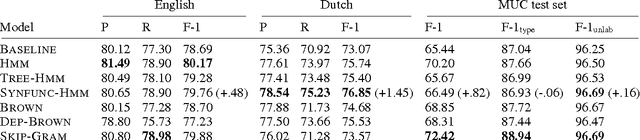
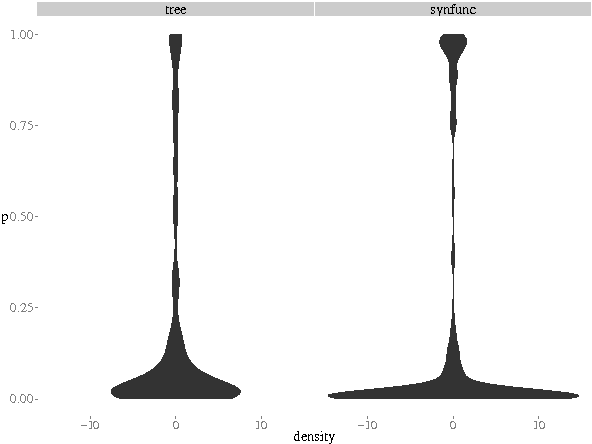
Word representations induced from models with discrete latent variables (e.g.\ HMMs) have been shown to be beneficial in many NLP applications. In this work, we exploit labeled syntactic dependency trees and formalize the induction problem as unsupervised learning of tree-structured hidden Markov models. Syntactic functions are used as additional observed variables in the model, influencing both transition and emission components. Such syntactic information can potentially lead to capturing more fine-grain and functional distinctions between words, which, in turn, may be desirable in many NLP applications. We evaluate the word representations on two tasks -- named entity recognition and semantic frame identification. We observe improvements from exploiting syntactic function information in both cases, and the results rivaling those of state-of-the-art representation learning methods. Additionally, we revisit the relationship between sequential and unlabeled-tree models and find that the advantage of the latter is not self-evident.
An investigation into language complexity of World-of-Warcraft game-external texts
Feb 07, 2015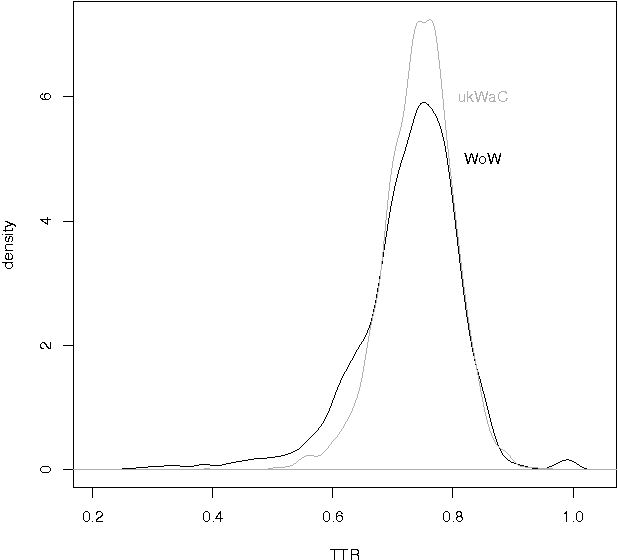
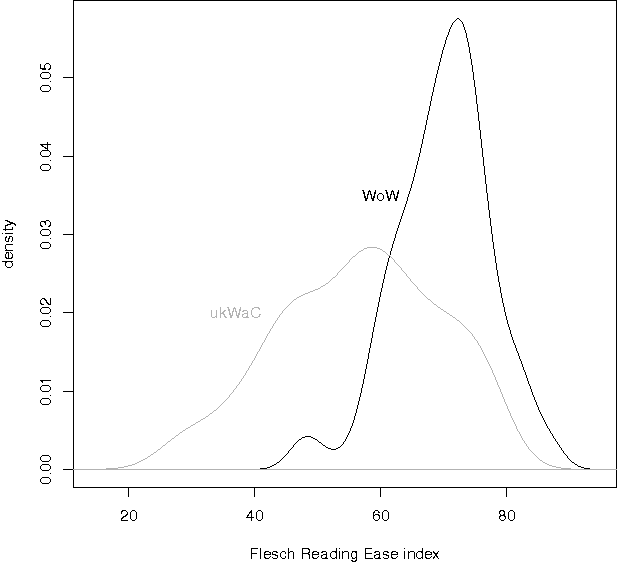
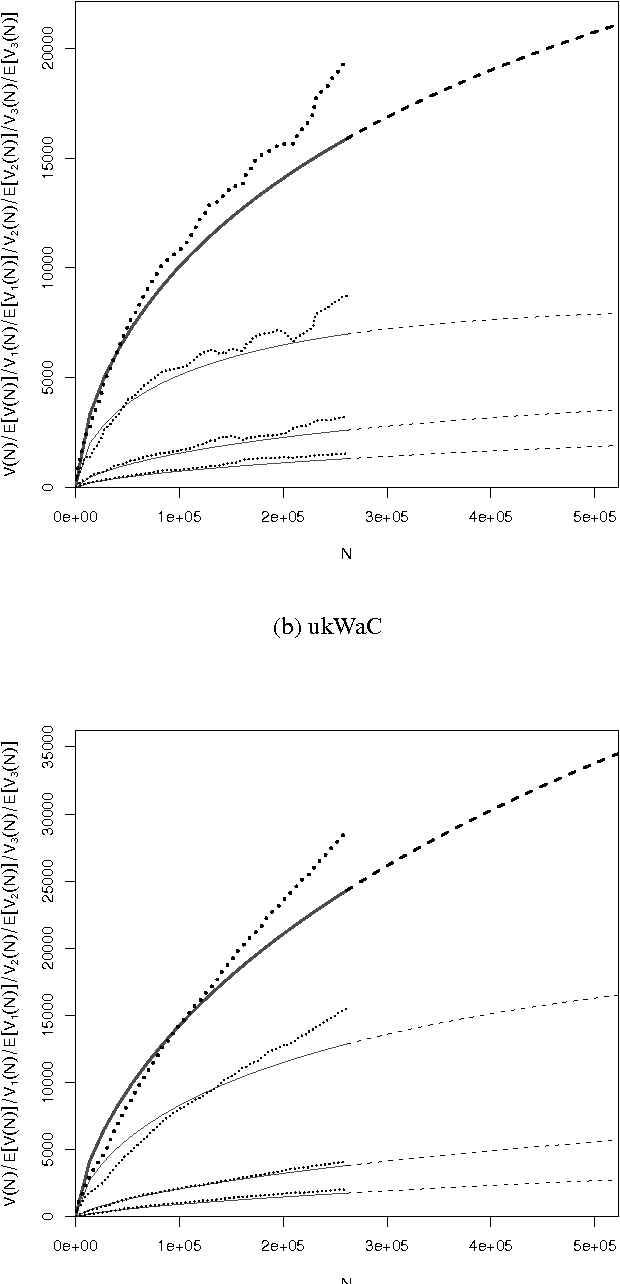
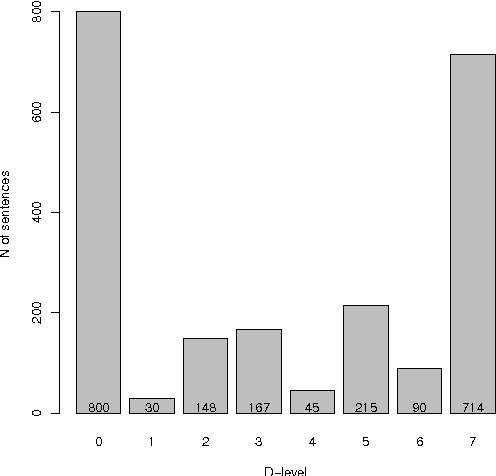
We present a language complexity analysis of World of Warcraft (WoW) community texts, which we compare to texts from a general corpus of web English. Results from several complexity types are presented, including lexical diversity, density, readability and syntactic complexity. The language of WoW texts is found to be comparable to the general corpus on some complexity measures, yet more specialized on other measures. Our findings can be used by educators willing to include game-related activities into school curricula.