 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrganizing a Society of Language Models: Structures and Mechanisms for Enhanced Collective Intelligence
May 06, 2024Recent developments in Large Language Models (LLMs) have significantly expanded their applications across various domains. However, the effectiveness of LLMs is often constrained when operating individually in complex environments. This paper introduces a transformative approach by organizing LLMs into community-based structures, aimed at enhancing their collective intelligence and problem-solving capabilities. We investigate different organizational models-hierarchical, flat, dynamic, and federated-each presenting unique benefits and challenges for collaborative AI systems. Within these structured communities, LLMs are designed to specialize in distinct cognitive tasks, employ advanced interaction mechanisms such as direct communication, voting systems, and market-based approaches, and dynamically adjust their governance structures to meet changing demands. The implementation of such communities holds substantial promise for improve problem-solving capabilities in AI, prompting an in-depth examination of their ethical considerations, management strategies, and scalability potential. This position paper seeks to lay the groundwork for future research, advocating a paradigm shift from isolated to synergistic operational frameworks in AI research and application.
SNeL: A Structured Neuro-Symbolic Language for Entity-Based Multimodal Scene Understanding
Jun 09, 2023In the evolving landscape of artificial intelligence, multimodal and Neuro-Symbolic paradigms stand at the forefront, with a particular emphasis on the identification and interaction with entities and their relations across diverse modalities. Addressing the need for complex querying and interaction in this context, we introduce SNeL (Structured Neuro-symbolic Language), a versatile query language designed to facilitate nuanced interactions with neural networks processing multimodal data. SNeL's expressive interface enables the construction of intricate queries, supporting logical and arithmetic operators, comparators, nesting, and more. This allows users to target specific entities, specify their properties, and limit results, thereby efficiently extracting information from a scene. By aligning high-level symbolic reasoning with low-level neural processing, SNeL effectively bridges the Neuro-Symbolic divide. The language's versatility extends to a variety of data types, including images, audio, and text, making it a powerful tool for multimodal scene understanding. Our evaluations demonstrate SNeL's potential to reshape the way we interact with complex neural networks, underscoring its efficacy in driving targeted information extraction and facilitating a deeper understanding of the rich semantics encapsulated in multimodal AI models.
End-to-end Semantic Object Detection with Cross-Modal Alignment
Feb 10, 2023Traditional semantic image search methods aim to retrieve images that match the meaning of the text query. However, these methods typically search for objects on the whole image, without considering the localization of objects within the image. This paper presents an extension of existing object detection models for semantic image search that considers the semantic alignment between object proposals and text queries, with a focus on searching for objects within images. The proposed model uses a single feature extractor, a pre-trained Convolutional Neural Network, and a transformer encoder to encode the text query. Proposal-text alignment is performed using contrastive learning, producing a score for each proposal that reflects its semantic alignment with the text query. The Region Proposal Network (RPN) is used to generate object proposals, and the end-to-end training process allows for an efficient and effective solution for semantic image search. The proposed model was trained end-to-end, providing a promising solution for semantic image search that retrieves images that match the meaning of the text query and generates semantically relevant object proposals.
A Transformer-Based Contrastive Learning Approach for Few-Shot Sign Language Recognition
Apr 05, 2022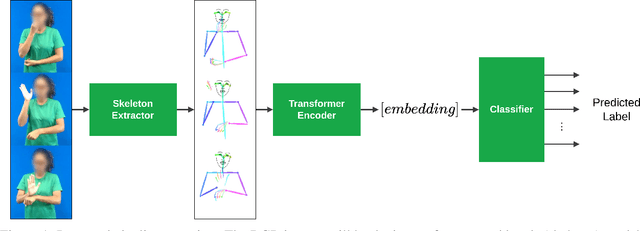
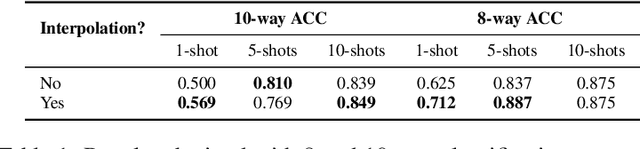
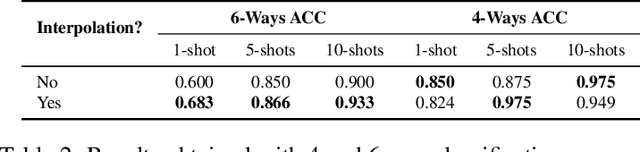
Sign language recognition from sequences of monocular images or 2D poses is a challenging field, not only due to the difficulty to infer 3D information from 2D data, but also due to the temporal relationship between the sequences of information. Additionally, the wide variety of signs and the constant need to add new ones on production environments makes it infeasible to use traditional classification techniques. We propose a novel Contrastive Transformer-based model, which demonstrate to learn rich representations from body key points sequences, allowing better comparison between vector embedding. This allows us to apply these techniques to perform one-shot or few-shot tasks, such as classification and translation. The experiments showed that the model could generalize well and achieved competitive results for sign classes never seen in the training process.