 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Quantile Regression by Optimal Decision Trees
Apr 22, 2026The field of machine learning is subject to an increasing interest in models that are not only accurate but also interpretable and robust, thus allowing their end users to understand and trust AI systems. This paper presents a novel method for learning a set of optimal quantile regression trees. The advantages of this method are that (1) it provides predictions about the complete conditional distribution of a target variable without prior assumptions on this distribution; (2) it provides predictions that are interpretable; (3) it learns a set of optimal quantile regression trees without compromising algorithmic efficiency compared to learning a single tree.
Anytime Optimal Decision Tree Learning with Continuous Features
Jan 21, 2026In recent years, significant progress has been made on algorithms for learning optimal decision trees, primarily in the context of binary features. Extending these methods to continuous features remains substantially more challenging due to the large number of potential splits for each feature. Recently, an elegant exact algorithm was proposed for learning optimal decision trees with continuous features; however, the rapidly increasing computational time limits its practical applicability to shallow depths (typically 3 or 4). It relies on a depth-first search optimization strategy that fully optimizes the left subtree of each split before exploring the corresponding right subtree. While effective in finding optimal solutions given sufficient time, this strategy can lead to poor anytime behavior: when interrupted early, the best-found tree is often highly unbalanced and suboptimal. In such cases, purely greedy methods such as C4.5 may, paradoxically, yield better solutions. To address this limitation, we propose an anytime, yet complete approach leveraging limited discrepancy search, distributing the computational effort more evenly across the entire tree structure, and thus ensuring that a high-quality decision tree is available at any interruption point. Experimental results show that our approach outperforms the existing one in terms of anytime performance.
TAGAL: Tabular Data Generation using Agentic LLM Methods
Sep 04, 2025The generation of data is a common approach to improve the performance of machine learning tasks, among which is the training of models for classification. In this paper, we present TAGAL, a collection of methods able to generate synthetic tabular data using an agentic workflow. The methods leverage Large Language Models (LLMs) for an automatic and iterative process that uses feedback to improve the generated data without any further LLM training. The use of LLMs also allows for the addition of external knowledge in the generation process. We evaluate TAGAL across diverse datasets and different aspects of quality for the generated data. We look at the utility of downstream ML models, both by training classifiers on synthetic data only and by combining real and synthetic data. Moreover, we compare the similarities between the real and the generated data. We show that TAGAL is able to perform on par with state-of-the-art approaches that require LLM training and generally outperforms other training-free approaches. These findings highlight the potential of agentic workflow and open new directions for LLM-based data generation methods.
A Generic Complete Anytime Beam Search for Optimal Decision Tree
Aug 08, 2025Finding an optimal decision tree that minimizes classification error is known to be NP-hard. While exact algorithms based on MILP, CP, SAT, or dynamic programming guarantee optimality, they often suffer from poor anytime behavior -- meaning they struggle to find high-quality decision trees quickly when the search is stopped before completion -- due to unbalanced search space exploration. To address this, several anytime extensions of exact methods have been proposed, such as LDS-DL8.5, Top-k-DL8.5, and Blossom, but they have not been systematically compared, making it difficult to assess their relative effectiveness. In this paper, we propose CA-DL8.5, a generic, complete, and anytime beam search algorithm that extends the DL8.5 framework and unifies some existing anytime strategies. In particular, CA-DL8.5 generalizes previous approaches LDS-DL8.5 and Top-k-DL8.5, by allowing the integration of various heuristics and relaxation mechanisms through a modular design. The algorithm reuses DL8.5's efficient branch-and-bound pruning and trie-based caching, combined with a restart-based beam search that gradually relaxes pruning criteria to improve solution quality over time. Our contributions are twofold: (1) We introduce this new generic framework for exact and anytime decision tree learning, enabling the incorporation of diverse heuristics and search strategies; (2) We conduct a rigorous empirical comparison of several instantiations of CA-DL8.5 -- based on Purity, Gain, Discrepancy, and Top-k heuristics -- using an anytime evaluation metric called the primal gap integral. Experimental results on standard classification benchmarks show that CA-DL8.5 using LDS (limited discrepancy) consistently provides the best anytime performance, outperforming both other CA-DL8.5 variants and the Blossom algorithm while maintaining completeness and optimality guarantees.
Impact of weather factors on migration intention using machine learning algorithms
Dec 04, 2020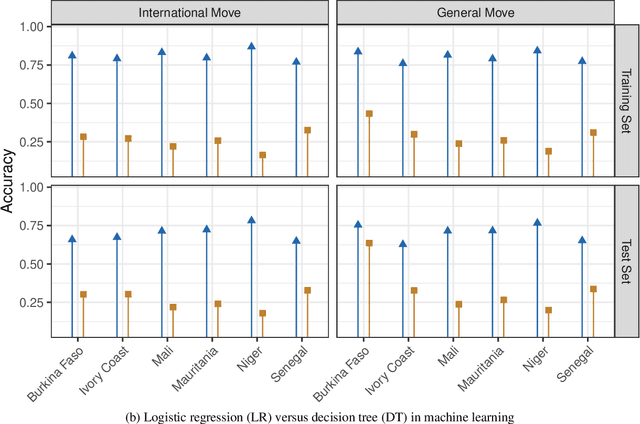
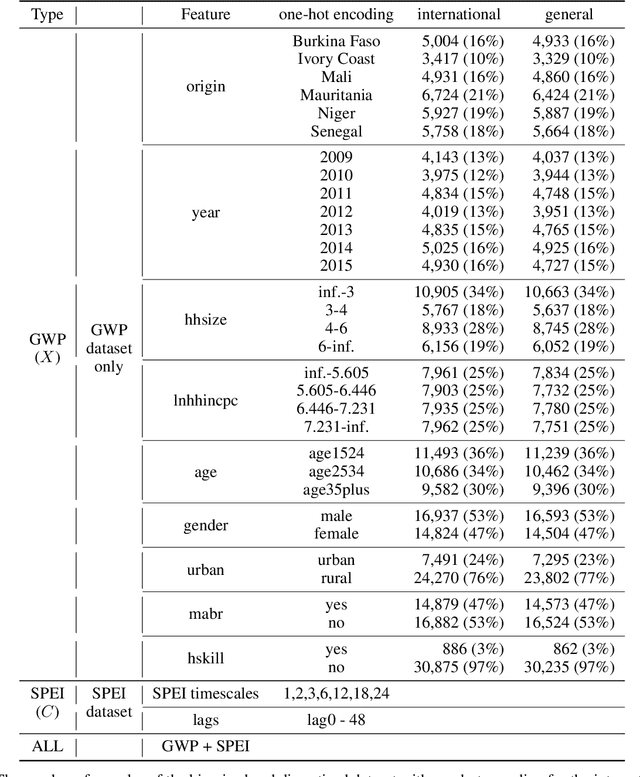
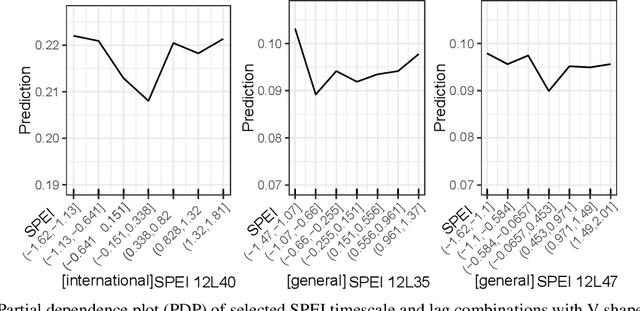

A growing attention in the empirical literature has been paid to the incidence of climate shocks and change in migration decisions. Previous literature leads to different results and uses a multitude of traditional empirical approaches. This paper proposes a tree-based Machine Learning (ML) approach to analyze the role of the weather shocks towards an individual's intention to migrate in the six agriculture-dependent-economy countries such as Burkina Faso, Ivory Coast, Mali, Mauritania, Niger, and Senegal. We perform several tree-based algorithms (e.g., XGB, Random Forest) using the train-validation-test workflow to build robust and noise-resistant approaches. Then we determine the important features showing in which direction they are influencing the migration intention. This ML-based estimation accounts for features such as weather shocks captured by the Standardized Precipitation-Evapotranspiration Index (SPEI) for different timescales and various socioeconomic features/covariates. We find that (i) weather features improve the prediction performance although socioeconomic characteristics have more influence on migration intentions, (ii) country-specific model is necessary, and (iii) international move is influenced more by the longer timescales of SPEIs while general move (which includes internal move) by that of shorter timescales.
Using an interpretable Machine Learning approach to study the drivers of International Migration
Jun 05, 2020
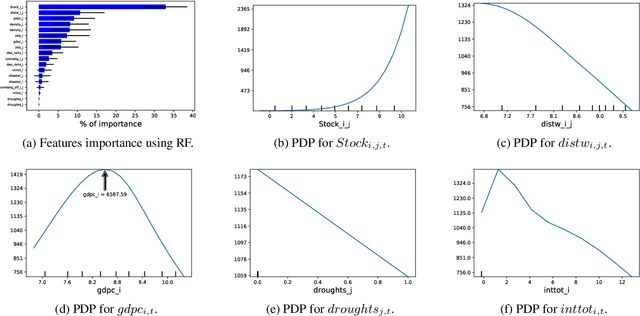
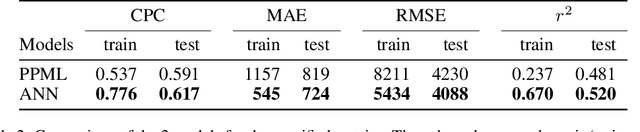
Globally increasing migration pressures call for new modelling approaches in order to design effective policies. It is important to have not only efficient models to predict migration flows but also to understand how specific parameters influence these flows. In this paper, we propose an artificial neural network (ANN) to model international migration. Moreover, we use a technique for interpreting machine learning models, namely Partial Dependence Plots (PDP), to show that one can well study the effects of drivers behind international migration. We train and evaluate the model on a dataset containing annual international bilateral migration from $1960$ to $2010$ from $175$ origin countries to $33$ mainly OECD destinations, along with the main determinants as identified in the migration literature. The experiments carried out confirm that: 1) the ANN model is more efficient w.r.t. a traditional model, and 2) using PDP we are able to gain additional insights on the specific effects of the migration drivers. This approach provides much more information than only using the feature importance information used in previous works.
Stochastic Constraint Optimization using Propagation on Ordered Binary Decision Diagrams
Jul 03, 2018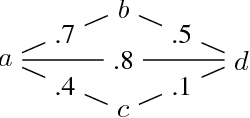
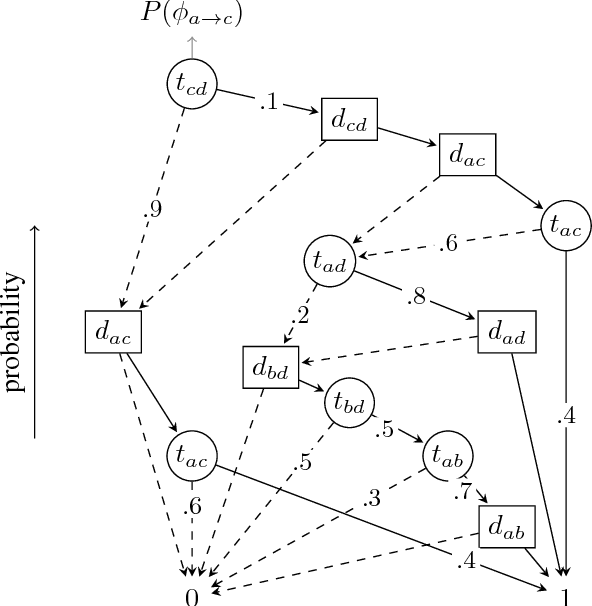
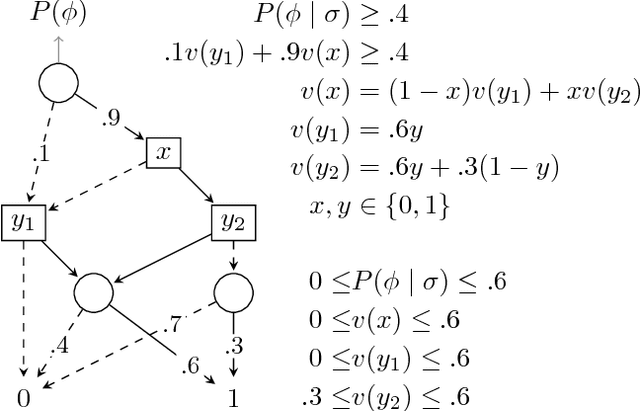
A number of problems in relational Artificial Intelligence can be viewed as Stochastic Constraint Optimization Problems (SCOPs). These are constraint optimization problems that involve objectives or constraints with a stochastic component. Building on the recently proposed language SC-ProbLog for modeling SCOPs, we propose a new method for solving these problems. Earlier methods used Probabilistic Logic Programming (PLP) techniques to create Ordered Binary Decision Diagrams (OBDDs), which were decomposed into smaller constraints in order to exploit existing constraint programming (CP) solvers. We argue that this approach has as drawback that a decomposed representation of an OBDD does not guarantee domain consistency during search, and hence limits the efficiency of the solver. For the specific case of monotonic distributions, we suggest an alternative method for using CP in SCOP, based on the development of a new propagator; we show that this propagator is linear in the size of the OBDD, and has the potential to be more efficient than the decomposition method, as it maintains domain consistency.
The Inductive Constraint Programming Loop
Oct 12, 2015
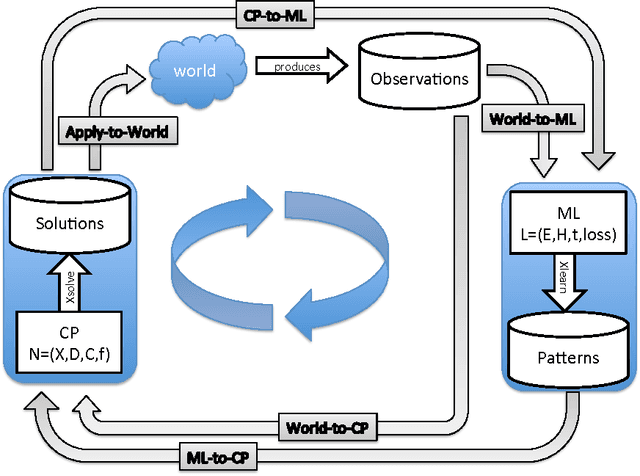


Constraint programming is used for a variety of real-world optimisation problems, such as planning, scheduling and resource allocation problems. At the same time, one continuously gathers vast amounts of data about these problems. Current constraint programming software does not exploit such data to update schedules, resources and plans. We propose a new framework, that we call the Inductive Constraint Programming loop. In this approach data is gathered and analyzed systematically, in order to dynamically revise and adapt constraints and optimization criteria. Inductive Constraint Programming aims at bridging the gap between the areas of data mining and machine learning on the one hand, and constraint programming on the other hand.
Pattern-Based Classification: A Unifying Perspective
Nov 26, 2011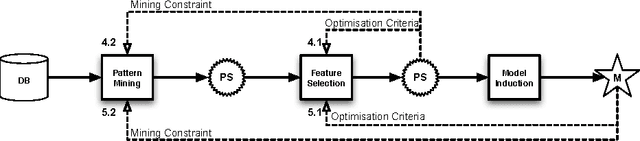
The use of patterns in predictive models is a topic that has received a lot of attention in recent years. Pattern mining can help to obtain models for structured domains, such as graphs and sequences, and has been proposed as a means to obtain more accurate and more interpretable models. Despite the large amount of publications devoted to this topic, we believe however that an overview of what has been accomplished in this area is missing. This paper presents our perspective on this evolving area. We identify the principles of pattern mining that are important when mining patterns for models and provide an overview of pattern-based classification methods. We categorize these methods along the following dimensions: (1) whether they post-process a pre-computed set of patterns or iteratively execute pattern mining algorithms; (2) whether they select patterns model-independently or whether the pattern selection is guided by a model. We summarize the results that have been obtained for each of these methods.