 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Direct-Connect Topologies for Collective Communications
Feb 07, 2022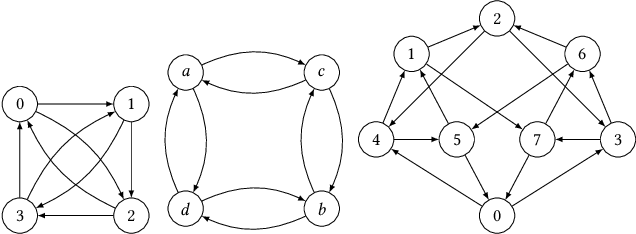
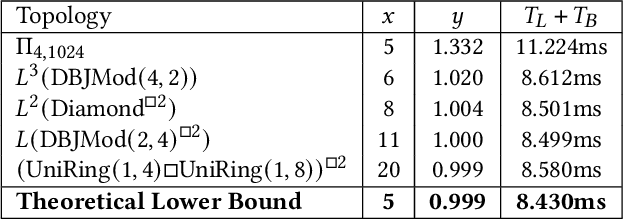
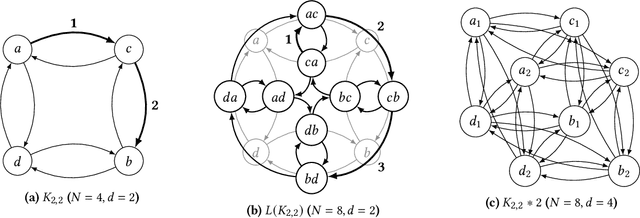
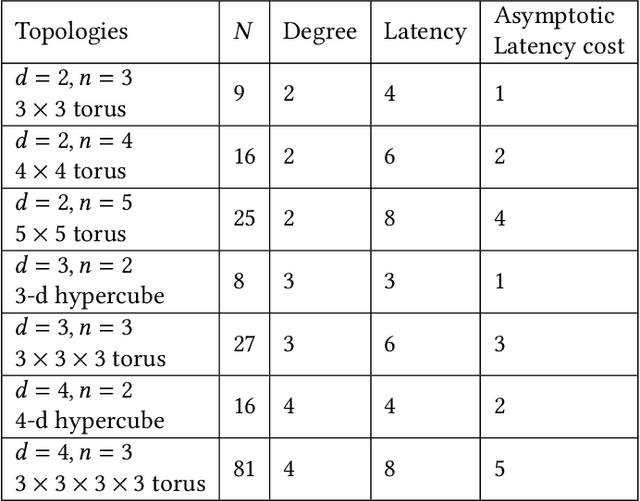
We consider the problem of distilling optimal network topologies for collective communications. We provide an algorithmic framework for constructing direct-connect topologies optimized for the latency-bandwidth tradeoff given a collective communication workload. Our algorithmic framework allows us to start from small base topologies and associated communication schedules and use a set of techniques that can be iteratively applied to derive much larger topologies and associated schedules. Our approach allows us to synthesize many different topologies and schedules for a given cluster size and degree constraint, and then identify the optimal topology for a given workload. We provide an analytical-model-based evaluation of the derived topologies and results on a small-scale optical testbed that uses patch panels for configuring a topology for the duration of an application's execution. We show that the derived topologies and schedules provide significant performance benefits over existing collective communications implementations.
Sparse Diffusion-Convolutional Neural Networks
Oct 26, 2017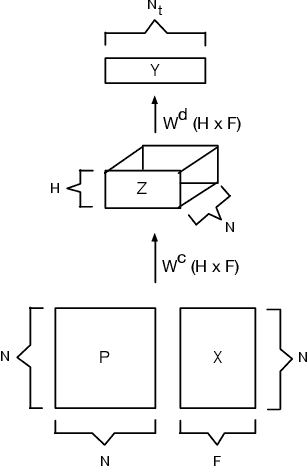
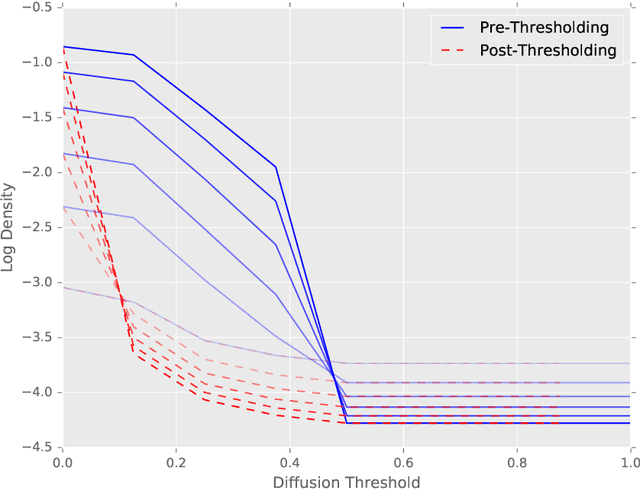
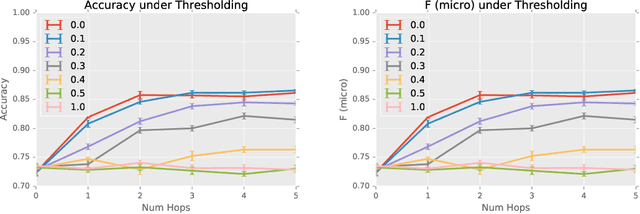
The predictive power and overall computational efficiency of Diffusion-convolutional neural networks make them an attractive choice for node classification tasks. However, a naive dense-tensor-based implementation of DCNNs leads to $\mathcal{O}(N^2)$ memory complexity which is prohibitive for large graphs. In this paper, we introduce a simple method for thresholding input graphs that provably reduces memory requirements of DCNNs to O(N) (i.e. linear in the number of nodes in the input) without significantly affecting predictive performance.