 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 1000-hour EEG-EMG-audio dataset of Japanese speech production
May 31, 2026We present a multimodal dataset of 1020 hours of simultaneously recorded scalp electroencephalography (EEG), facial electromyography (EMG), and speech audio from three healthy native Japanese speakers during open-vocabulary overt speech. Recordings were acquired with three EEG systems-an ultra-high-density system (g.Pangolin) and two cap-type systems (g.SCARABEO and eegosports), spanning 62-128 channels-across many sessions over several months. Each session provides time-synchronized EEG, facial EMG, and audio, together with speech-event annotations and transcriptions. Although collected with speech decoding as a primary motivation, the dataset also supports work on multimodal signal processing, artifact modeling, longitudinal and cross-device adaptation, and EEG representation learning. Technical validation included power spectral density and event-related potential analyses across participants, devices, and tasks, which showed the expected 1/f spectral profile, task-related alpha-band attenuation, and time-locked evoked responses. The dataset is released in Brain Imaging Data Structure (BIDS) format via OpenNeuro under a CC0 waiver to support both speech-related and broader EEG research.
Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data
Jul 10, 2024



Brain-computer interfaces (BCIs) hold great potential for aiding individuals with speech impairments. Utilizing electroencephalography (EEG) to decode speech is particularly promising due to its non-invasive nature. However, recordings are typically short, and the high variability in EEG data has led researchers to focus on classification tasks with a few dozen classes. To assess its practical applicability for speech neuroprostheses, we investigate the relationship between the size of EEG data and decoding accuracy in the open vocabulary setting. We collected extensive EEG data from a single participant (175 hours) and conducted zero-shot speech segment classification using self-supervised representation learning. The model trained on the entire dataset achieved a top-1 accuracy of 48\% and a top-10 accuracy of 76\%, while mitigating the effects of myopotential artifacts. Conversely, when the data was limited to the typical amount used in practice ($\sim$10 hours), the top-1 accuracy dropped to 2.5\%, revealing a significant scaling effect. Additionally, as the amount of training data increased, the EEG latent representation progressively exhibited clearer temporal structures of spoken phrases. This indicates that the decoder can recognize speech segments in a data-driven manner without explicit measurements of word recognition. This research marks a significant step towards the practical realization of EEG-based speech BCIs.
On the link between conscious function and general intelligence in humans and machines
Mar 24, 2022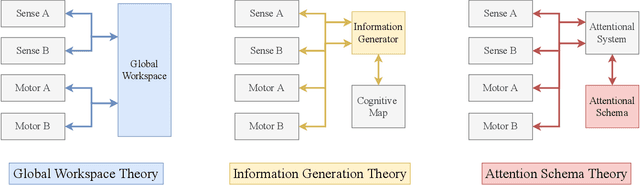
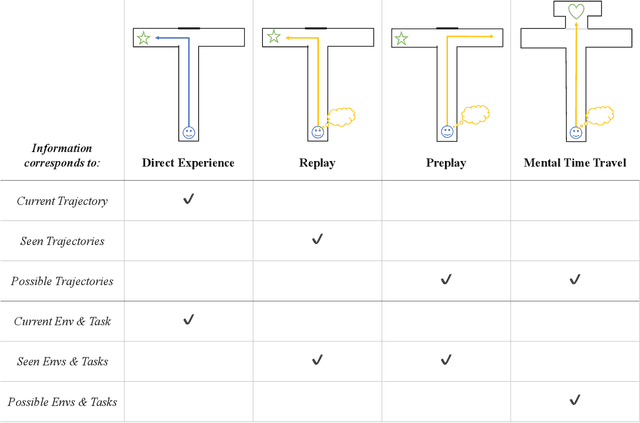
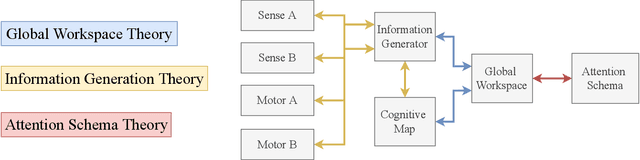
In popular media, there is often a connection drawn between the advent of awareness in artificial agents and those same agents simultaneously achieving human or superhuman level intelligence. In this work, we explore the validity and potential application of this seemingly intuitive link between consciousness and intelligence. We do so by examining the cognitive abilities associated with three contemporary theories of conscious function: Global Workspace Theory (GWT), Information Generation Theory (IGT), and Attention Schema Theory (AST). We find that all three theories specifically relate conscious function to some aspect of domain-general intelligence in humans. With this insight, we turn to the field of Artificial Intelligence (AI) and find that, while still far from demonstrating general intelligence, many state-of-the-art deep learning methods have begun to incorporate key aspects of each of the three functional theories. Given this apparent trend, we use the motivating example of mental time travel in humans to propose ways in which insights from each of the three theories may be combined into a unified model. We believe that doing so can enable the development of artificial agents which are not only more generally intelligent but are also consistent with multiple current theories of conscious function.