 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Agentic Theorem Prover Works: A Statistical Provability Theory of Mathematical Reasoning Models
Feb 12, 2026Agentic theorem provers -- pipelines that couple a mathematical reasoning model with library retrieval, subgoal-decomposition/search planner, and a proof assistant verifier -- have recently achieved striking empirical success, yet it remains unclear which components drive performance and why such systems work at all despite classical hardness of proof search. We propose a distributional viewpoint and introduce \textbf{statistical provability}, defined as the finite-horizon success probability of reaching a verified proof, averaged over an instance distribution, and formalize modern theorem-proving pipelines as time-bounded MDPs. Exploiting Bellman structure, we prove existence of optimal policies under mild regularity, derive provability certificates via sub-/super-solution inequalities, and bound the performance gap of score-guided planning (greedy/top-\(k\)/beam/rollouts) in terms of approximation error, sequential statistical complexity, representation geometry (metric entropy/doubling structure), and action-gap margin tails. Together, our theory provides a principled, component-sensitive explanation of when and why agentic theorem provers succeed on biased real-world problem distributions, while clarifying limitations in worst-case or adversarial regimes.
Don't Eliminate Cut: Exponential Separations in LLM-Based Theorem Proving
Feb 11, 2026We develop a theoretical analysis of LLM-guided formal theorem proving in interactive proof assistants (e.g., Lean) by modeling tactic proposal as a stochastic policy in a finite-horizon deterministic MDP. To capture modern representation learning, we treat the state and action spaces as general compact metric spaces and assume Lipschitz policies. To explain the gap between worst-case hardness and empirical success, we introduce problem distributions generated by a reference policy $q$, including a latent-variable model in which proofs exhibit reusable cut/lemma/sketch structure represented by a proof DAG. Under a top-$k$ search protocol and Tsybakov-type margin conditions, we derive lower bounds on finite-horizon success probability that decompose into search and learning terms, with learning controlled by sequential Rademacher/covering complexity. Our main separation result shows that when cut elimination expands a DAG of depth $D$ into a cut-free tree of size $Ω(Λ^D)$ while the cut-aware hierarchical process has size $O(λ^D)$ with $λ\llΛ$, a flat (cut-free) learner provably requires exponentially more data than a cut-aware hierarchical learner. This provides a principled justification for subgoal decomposition in recent agentic theorem provers.
Block Coordinate Descent for Neural Networks Provably Finds Global Minima
Oct 26, 2025In this paper, we consider a block coordinate descent (BCD) algorithm for training deep neural networks and provide a new global convergence guarantee under strictly monotonically increasing activation functions. While existing works demonstrate convergence to stationary points for BCD in neural networks, our contribution is the first to prove convergence to global minima, ensuring arbitrarily small loss. We show that the loss with respect to the output layer decreases exponentially while the loss with respect to the hidden layers remains well-controlled. Additionally, we derive generalization bounds using the Rademacher complexity framework, demonstrating that BCD not only achieves strong optimization guarantees but also provides favorable generalization performance. Moreover, we propose a modified BCD algorithm with skip connections and non-negative projection, extending our convergence guarantees to ReLU activation, which are not strictly monotonic. Empirical experiments confirm our theoretical findings, showing that the BCD algorithm achieves a small loss for strictly monotonic and ReLU activations.
Diffusion Models are Minimax Optimal Distribution Estimators
Mar 03, 2023While efficient distribution learning is no doubt behind the groundbreaking success of diffusion modeling, its theoretical guarantees are quite limited. In this paper, we provide the first rigorous analysis on approximation and generalization abilities of diffusion modeling for well-known function spaces. The highlight of this paper is that when the true density function belongs to the Besov space and the empirical score matching loss is properly minimized, the generated data distribution achieves the nearly minimax optimal estimation rates in the total variation distance and in the Wasserstein distance of order one. Furthermore, we extend our theory to demonstrate how diffusion models adapt to low-dimensional data distributions. We expect these results advance theoretical understandings of diffusion modeling and its ability to generate verisimilar outputs.
Excess Risk of Two-Layer ReLU Neural Networks in Teacher-Student Settings and its Superiority to Kernel Methods
Jun 06, 2022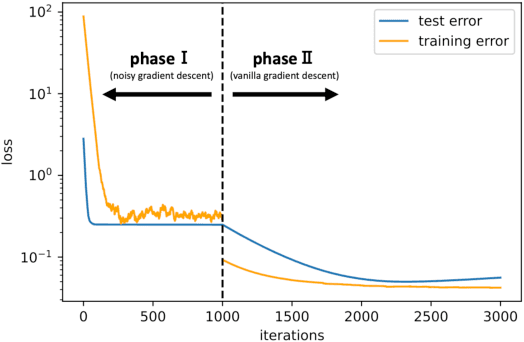
While deep learning has outperformed other methods for various tasks, theoretical frameworks that explain its reason have not been fully established. To address this issue, we investigate the excess risk of two-layer ReLU neural networks in a teacher-student regression model, in which a student network learns an unknown teacher network through its outputs. Especially, we consider the student network that has the same width as the teacher network and is trained in two phases: first by noisy gradient descent and then by the vanilla gradient descent. Our result shows that the student network provably reaches a near-global optimal solution and outperforms any kernel methods estimator (more generally, linear estimators), including neural tangent kernel approach, random feature model, and other kernel methods, in a sense of the minimax optimal rate. The key concept inducing this superiority is the non-convexity of the neural network models. Even though the loss landscape is highly non-convex, the student network adaptively learns the teacher neurons.
On Learnability via Gradient Method for Two-Layer ReLU Neural Networks in Teacher-Student Setting
Jun 29, 2021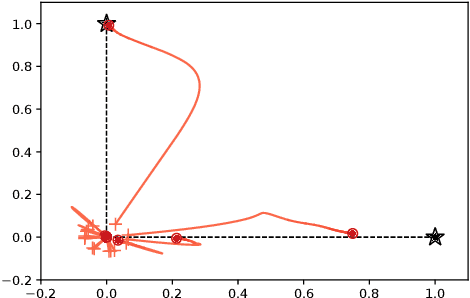
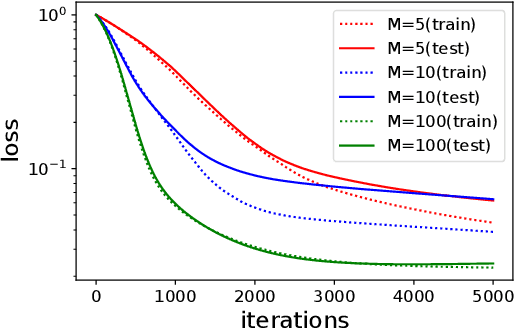
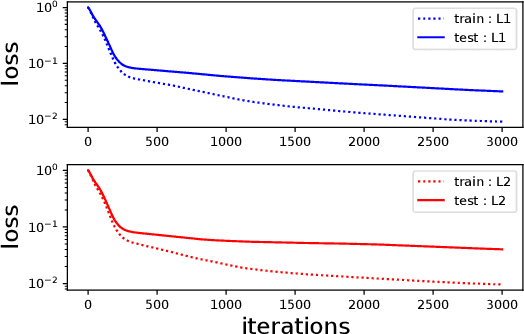
Deep learning empirically achieves high performance in many applications, but its training dynamics has not been fully understood theoretically. In this paper, we explore theoretical analysis on training two-layer ReLU neural networks in a teacher-student regression model, in which a student network learns an unknown teacher network through its outputs. We show that with a specific regularization and sufficient over-parameterization, the student network can identify the parameters of the teacher network with high probability via gradient descent with a norm dependent stepsize even though the objective function is highly non-convex. The key theoretical tool is the measure representation of the neural networks and a novel application of a dual certificate argument for sparse estimation on a measure space. We analyze the global minima and global convergence property in the measure space.
Benefit of deep learning with non-convex noisy gradient descent: Provable excess risk bound and superiority to kernel methods
Dec 06, 2020Establishing a theoretical analysis that explains why deep learning can outperform shallow learning such as kernel methods is one of the biggest issues in the deep learning literature. Towards answering this question, we evaluate excess risk of a deep learning estimator trained by a noisy gradient descent with ridge regularization on a mildly overparameterized neural network, and discuss its superiority to a class of linear estimators that includes neural tangent kernel approach, random feature model, other kernel methods, $k$-NN estimator and so on. We consider a teacher-student regression model, and eventually show that any linear estimator can be outperformed by deep learning in a sense of the minimax optimal rate especially for a high dimension setting. The obtained excess bounds are so-called fast learning rate which is faster than $O(1/\sqrt{n})$ that is obtained by usual Rademacher complexity analysis. This discrepancy is induced by the non-convex geometry of the model and the noisy gradient descent used for neural network training provably reaches a near global optimal solution even though the loss landscape is highly non-convex. Although the noisy gradient descent does not employ any explicit or implicit sparsity inducing regularization, it shows a preferable generalization performance that dominates linear estimators.