 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteMedCoT-VL: Parameter-Efficient Adaptation for Medical Visual Question Answering
May 10, 2026The reasoning gap between large and compact vision-language models (VLMs) limits the deployment of medical AI on portable clinical devices. Compact VLMs of 2--4B parameters can run on resource-constrained hardware but lack the multi-step reasoning capacity needed for interpretable clinical decision support. Existing knowledge distillation methods transfer answers without the reasoning process behind them. Medical visual question answering (VQA) serves as a testbed for this problem, as it requires models to integrate visual evidence with clinical knowledge through structured reasoning chains. We introduce LiteMedCoT-VL, a pipeline that transfers chain-of-thought reasoning from a 235B teacher model to 2B student models through LoRA-based fine-tuning on explanation-enriched training data. All inference is conducted without image captions by default, simulating the clinical scenario in which a physician interprets a medical image directly without an accompanying radiology report. On the PMC-VQA benchmark, LiteMedCoT-VL achieves 64.9% accuracy, exceeding the zero-shot Qwen3-VL-4B baseline of 53.9% by 11.0 percentage points and outperforming all published baselines. This result indicates that a 2B model with reasoning distillation can match or exceed models with twice the parameters. Visual grounding analysis shows that the model relies on image content rather than exploiting textual priors. Our code is publicly available at https://anonymous.4open.science/r/LiteMedCoT-VL.
CPR: Causal Physiological Representation Learning for Robust ECG Analysis under Distribution Shifts
Dec 31, 2025Deep learning models for Electrocardiogram (ECG) diagnosis have achieved remarkable accuracy but exhibit fragility against adversarial perturbations, particularly Smooth Adversarial Perturbations (SAP) that mimic biological morphology. Existing defenses face a critical dilemma: Adversarial Training (AT) provides robustness but incurs a prohibitive computational burden, while certified methods like Randomized Smoothing (RS) introduce significant inference latency, rendering them impractical for real-time clinical monitoring. We posit that this vulnerability stems from the models' reliance on non-robust spurious correlations rather than invariant pathological features. To address this, we propose Causal Physiological Representation Learning (CPR). Unlike standard denoising approaches that operate without semantic constraints, CPR incorporates a Physiological Structural Prior within a causal disentanglement framework. By modeling ECG generation via a Structural Causal Model (SCM), CPR enforces a structural intervention that strictly separates invariant pathological morphology (P-QRS-T complex) from non-causal artifacts. Empirical results on PTB-XL demonstrate that CPR significantly outperforms standard clinical preprocessing methods. Specifically, under SAP attacks, CPR achieves an F1 score of 0.632, surpassing Median Smoothing (0.541 F1) by 9.1%. Crucially, CPR matches the certified robustness of Randomized Smoothing while maintaining single-pass inference efficiency, offering a superior trade-off between robustness, efficiency, and clinical interpretability.
SCAR: Semantic Cardiac Adversarial Representation via Spatiotemporal Manifold Optimization in ECG
Dec 19, 2025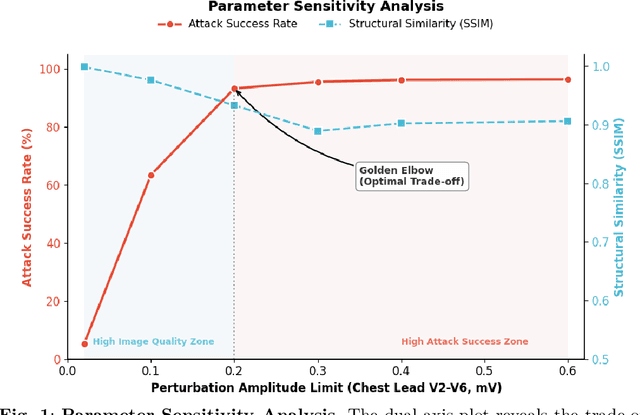

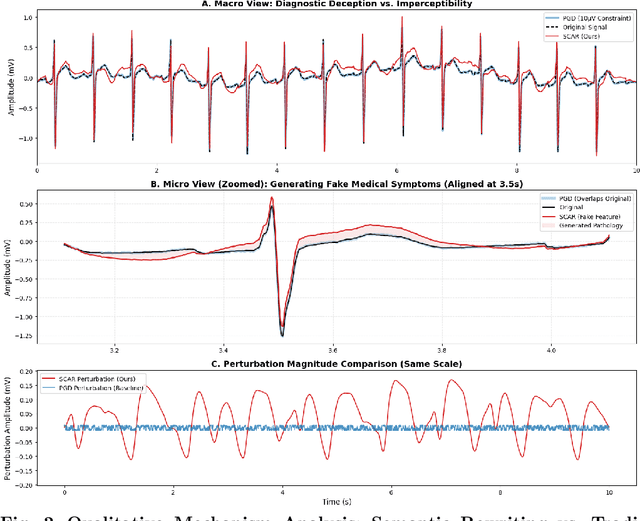
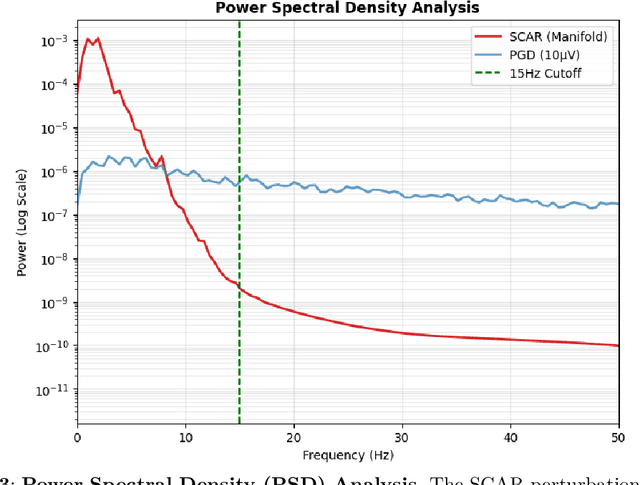
Deep learning models for Electrocardiogram (ECG) analysis have achieved expert-level performance but remain vulnerable to adversarial attacks. However, applying Universal Adversarial Perturbations (UAP) to ECG signals presents a unique challenge: standard imperceptible noise constraints (e.g., 10 uV) fail to generate effective universal attacks due to the high inter-subject variability of cardiac waveforms. Furthermore, traditional "invisible" attacks are easily dismissed by clinicians as technical artifacts, failing to compromise the human-in-the-loop diagnostic pipeline. In this study, we propose SCAR (Semantic Cardiac Adversarial Representation), a novel UAP framework tailored to bypass the clinical "Human Firewall." Unlike traditional approaches, SCAR integrates spatiotemporal smoothing (W=25, approx. 50ms), spectral consistency (<15 Hz), and anatomical amplitude constraints (<0.2 mV) directly into the gradient optimization manifold. Results: We benchmarked SCAR against a rigorous baseline (Standard Universal DeepFool with post-hoc physiological filtering). While the baseline suffers a performance collapse (~16% success rate on transfer tasks), SCAR maintains robust transferability (58.09% on ResNet) and achieves 82.46% success on the source model. Crucially, clinical analysis reveals an emergent targeted behavior: SCAR specifically converges to forging Myocardial Infarction features (90.2% misdiagnosis) by mathematically reconstructing pathological ST-segment elevations. Finally, we demonstrate that SCAR serves a dual purpose: it not only functions as a robust data augmentation strategy for Hybrid Adversarial Training, offering optimal clinical defense, but also provides effective educational samples for training clinicians to recognize low-cost, AI-targeted semantic forgeries.