 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithms for item categorization based on ordinal ranking data
Sep 29, 2016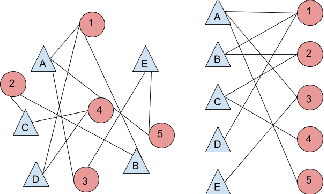

We present a new method for identifying the latent categorization of items based on their rankings. Complimenting a recent work that uses a Dirichlet prior on preference vectors and variational inference, we show that this problem can be effectively dealt with using existing community detection algorithms, with the communities corresponding to item categories. In particular we convert the bipartite ranking data to a unipartite graph of item affinities, and apply community detection algorithms. In this context we modify an existing algorithm - namely the label propagation algorithm to a variant that uses the distance between the nodes for weighting the label propagation - to identify the categories. We propose and analyze a synthetic ordinal ranking model and show its relation to the recently much studied stochastic block model. We test our algorithms on synthetic data and compare performance with several popular community detection algorithms. We also test the method on real data sets of movie categorization from the Movie Lens database. In all of the cases our algorithm is able to identify the categories for a suitable choice of tuning parameter.
Tensor Completion by Alternating Minimization under the Tensor Train (TT) Model
Sep 19, 2016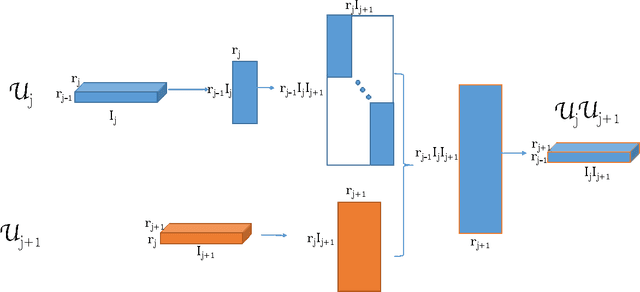
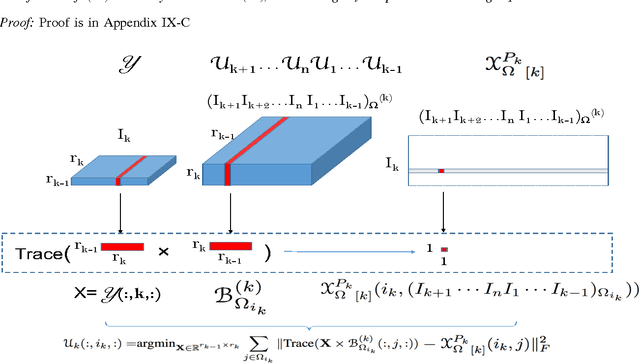
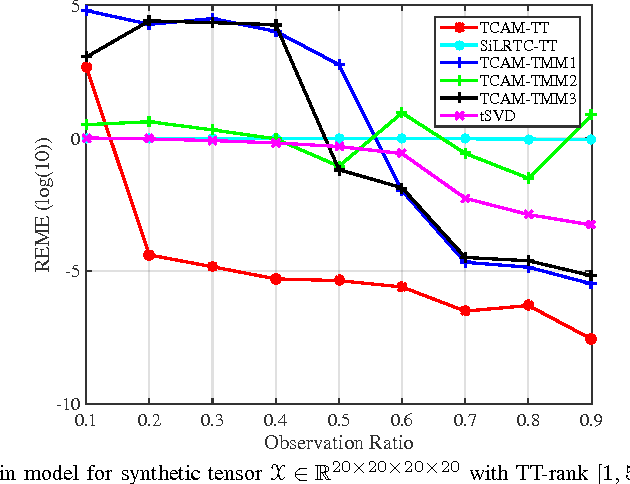
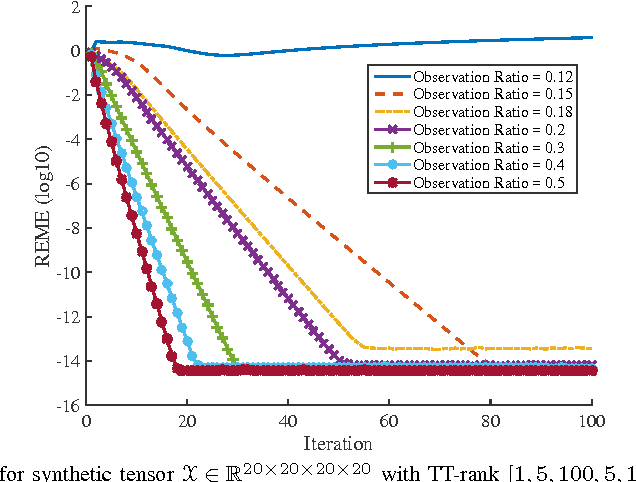
Using the matrix product state (MPS) representation of tensor train decompositions, in this paper we propose a tensor completion algorithm which alternates over the matrices (tensors) in the MPS representation. This development is motivated in part by the success of matrix completion algorithms which alternate over the (low-rank) factors. We comment on the computational complexity of the proposed algorithm and numerically compare it with existing methods employing low rank tensor train approximation for data completion as well as several other recently proposed methods. We show that our method is superior to existing ones for a variety of real settings.
On Deterministic Conditions for Subspace Clustering under Missing Data
Jul 11, 2016
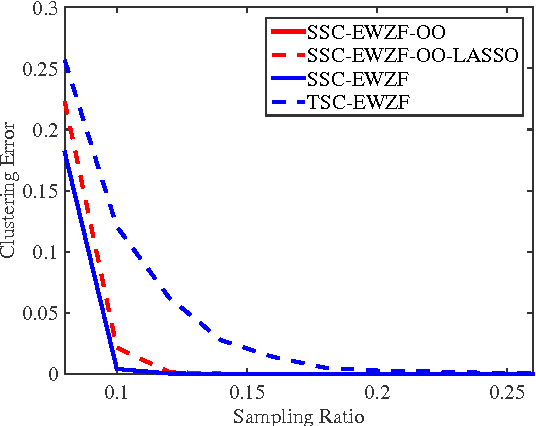
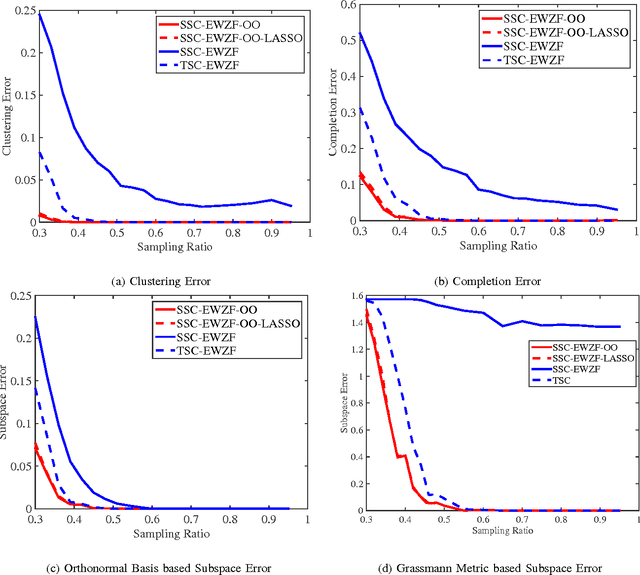
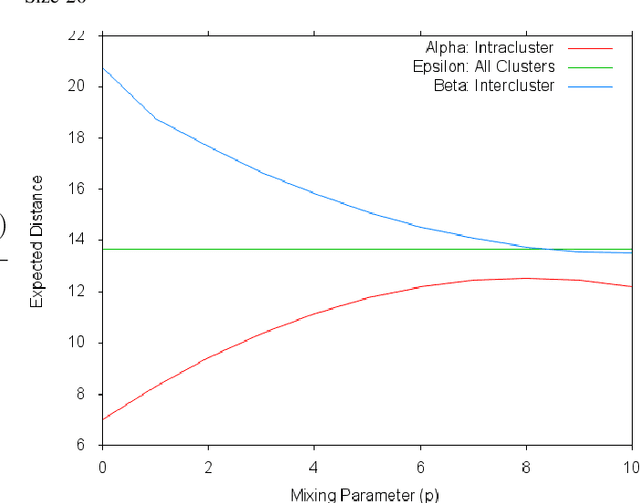
In this paper we present deterministic conditions for success of sparse subspace clustering (SSC) under missing data, when data is assumed to come from a Union of Subspaces (UoS) model. We consider two algorithms, which are variants of SSC with entry-wise zero-filling that differ in terms of the optimization problems used to find affinity matrix for spectral clustering. For both the algorithms, we provide deterministic conditions for any pattern of missing data such that perfect clustering can be achieved. We provide extensive sets of simulation results for clustering as well as completion of data at missing entries, under the UoS model. Our experimental results indicate that in contrast to the full data case, accurate clustering does not imply accurate subspace identification and completion, indicating the natural order of relative hardness of these problems.
Denoising and Completion of 3D Data via Multidimensional Dictionary Learning
Dec 31, 2015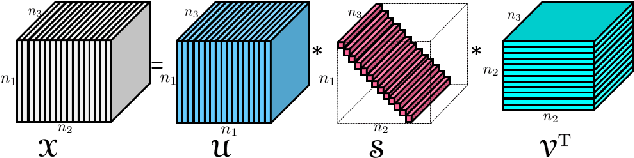
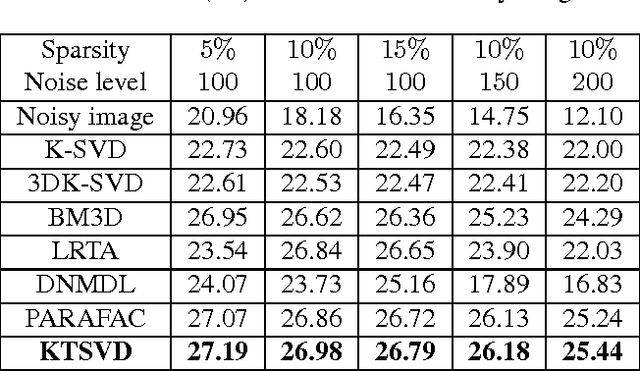
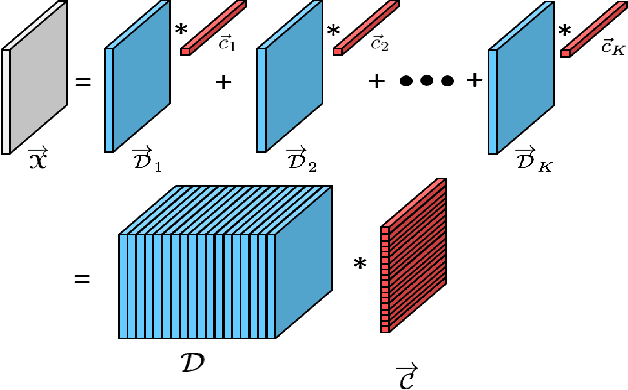
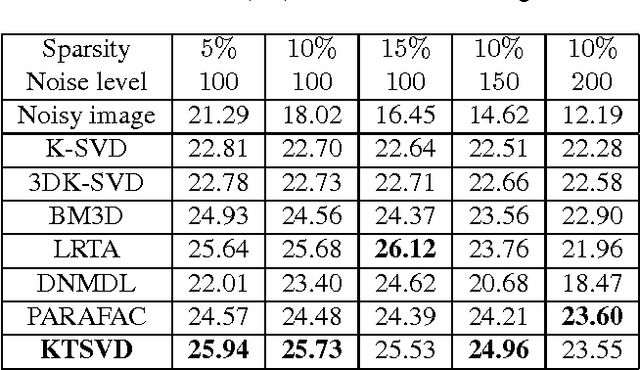
In this paper a new dictionary learning algorithm for multidimensional data is proposed. Unlike most conventional dictionary learning methods which are derived for dealing with vectors or matrices, our algorithm, named KTSVD, learns a multidimensional dictionary directly via a novel algebraic approach for tensor factorization as proposed in [3, 12, 13]. Using this approach one can define a tensor-SVD and we propose to extend K-SVD algorithm used for 1-D data to a K-TSVD algorithm for handling 2-D and 3-D data. Our algorithm, based on the idea of sparse coding (using group-sparsity over multidimensional coefficient vectors), alternates between estimating a compact representation and dictionary learning. We analyze our KTSVD algorithm and demonstrate its result on video completion and multispectral image denoising.
Multilinear Subspace Clustering
Dec 21, 2015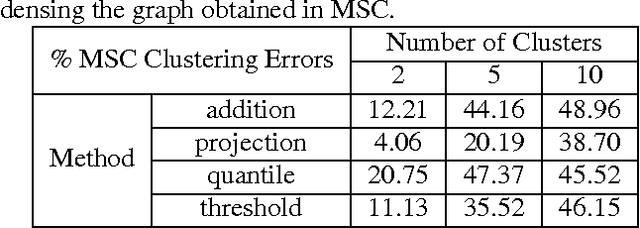

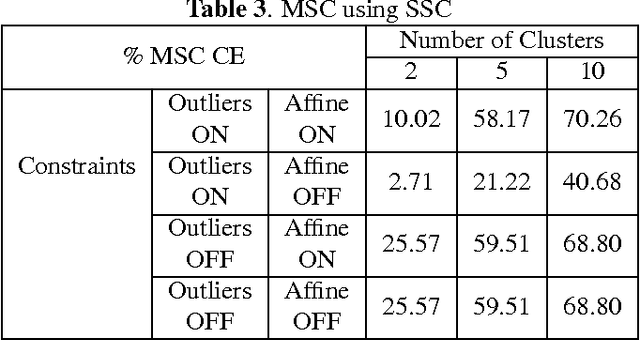
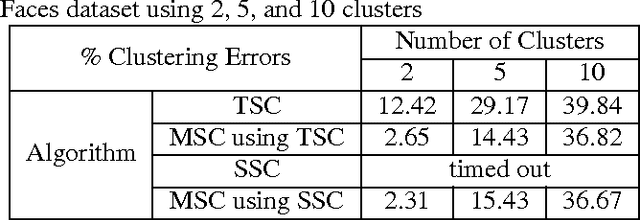
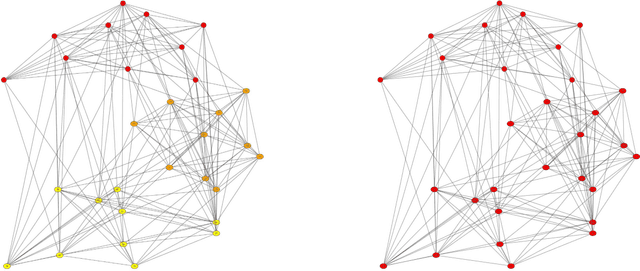
In this paper we present a new model and an algorithm for unsupervised clustering of 2-D data such as images. We assume that the data comes from a union of multilinear subspaces (UOMS) model, which is a specific structured case of the much studied union of subspaces (UOS) model. For segmentation under this model, we develop Multilinear Subspace Clustering (MSC) algorithm and evaluate its performance on the YaleB and Olivietti image data sets. We show that MSC is highly competitive with existing algorithms employing the UOS model in terms of clustering performance while enjoying improvement in computational complexity.
Adaptive Sampling of RF Fingerprints for Fine-grained Indoor Localization
Dec 01, 2015
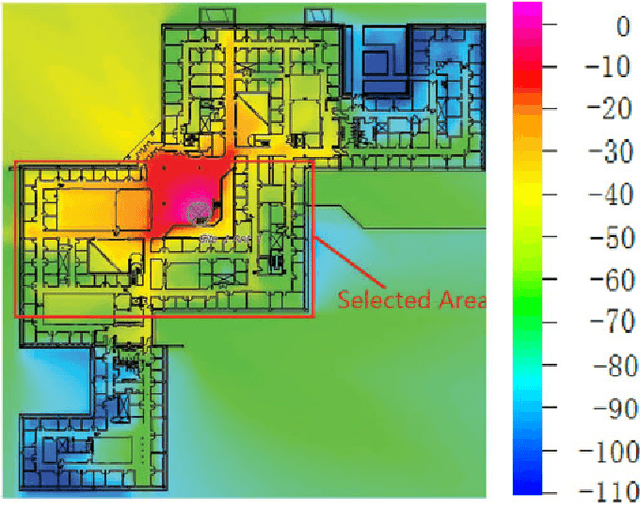
Indoor localization is a supporting technology for a broadening range of pervasive wireless applications. One promis- ing approach is to locate users with radio frequency fingerprints. However, its wide adoption in real-world systems is challenged by the time- and manpower-consuming site survey process, which builds a fingerprint database a priori for localization. To address this problem, we visualize the 3-D RF fingerprint data as a function of locations (x-y) and indices of access points (fingerprint), as a tensor and use tensor algebraic methods for an adaptive tubal-sampling of this fingerprint space. In particular using a recently proposed tensor algebraic framework in [1] we capture the complexity of the fingerprint space as a low-dimensional tensor-column space. In this formulation the proposed scheme exploits adaptivity to identify reference points which are highly informative for learning this low-dimensional space. Further, under certain incoherency conditions we prove that the proposed scheme achieves bounded recovery error and near-optimal sampling complexity. In contrast to several existing work that rely on random sampling, this paper shows that adaptivity in sampling can lead to significant improvements in localization accuracy. The approach is validated on both data generated by the ray-tracing indoor model which accounts for the floor plan and the impact of walls and the real world data. Simulation results show that, while maintaining the same localization accuracy of existing approaches, the amount of samples can be cut down by 71% for the high SNR case and 55% for the low SNR case.
* To appear in IEEE Transactions on Mobile Computing
Group-Invariant Subspace Clustering
Oct 15, 2015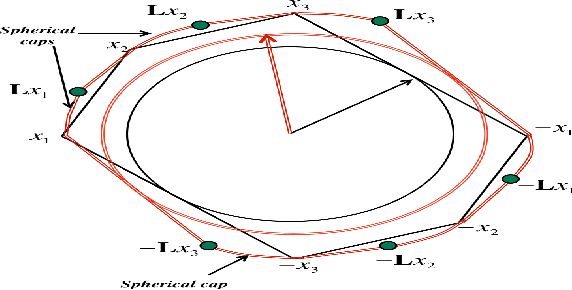
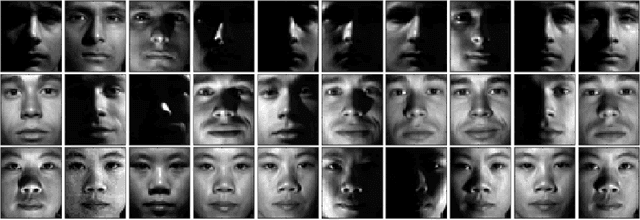
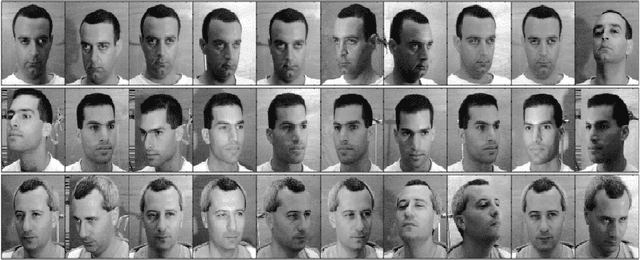
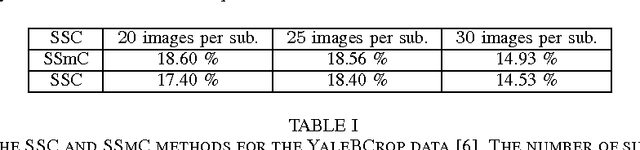
In this paper we consider the problem of group invariant subspace clustering where the data is assumed to come from a union of group-invariant subspaces of a vector space, i.e. subspaces which are invariant with respect to action of a given group. Algebraically, such group-invariant subspaces are also referred to as submodules. Similar to the well known Sparse Subspace Clustering approach where the data is assumed to come from a union of subspaces, we analyze an algorithm which, following a recent work [1], we refer to as Sparse Sub-module Clustering (SSmC). The method is based on finding group-sparse self-representation of data points. In this paper we primarily derive general conditions under which such a group-invariant subspace identification is possible. In particular we extend the geometric analysis in [2] and in the process we identify a related problem in geometric functional analysis.
Information-theoretic Bounds on Matrix Completion under Union of Subspaces Model
Aug 14, 2015In this short note we extend some of the recent results on matrix completion under the assumption that the columns of the matrix can be grouped (clustered) into subspaces (not necessarily disjoint or independent). This model deviates from the typical assumption prevalent in the literature dealing with compression and recovery for big-data applications. The results have a direct bearing on the problem of subspace clustering under missing or incomplete information.
An algorithm for online tensor prediction
Jul 28, 2015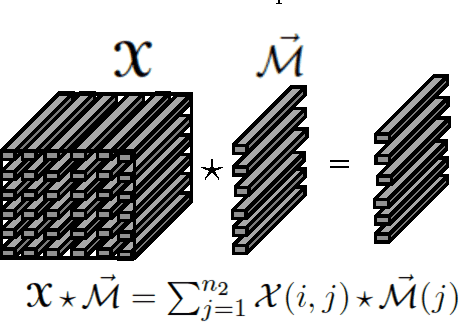
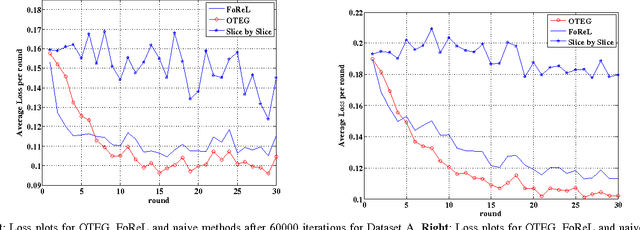
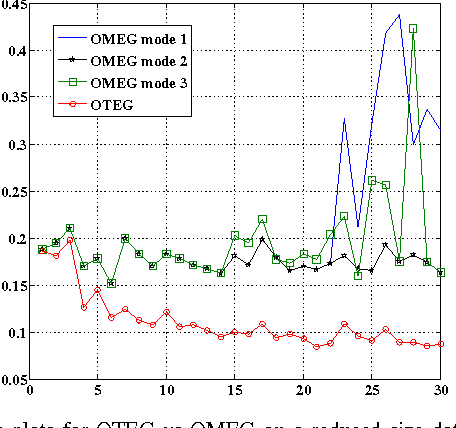
We present a new method for online prediction and learning of tensors ($N$-way arrays, $N >2$) from sequential measurements. We focus on the specific case of 3-D tensors and exploit a recently developed framework of structured tensor decompositions proposed in [1]. In this framework it is possible to treat 3-D tensors as linear operators and appropriately generalize notions of rank and positive definiteness to tensors in a natural way. Using these notions we propose a generalization of the matrix exponentiated gradient descent algorithm [2] to a tensor exponentiated gradient descent algorithm using an extension of the notion of von-Neumann divergence to tensors. Then following a similar construction as in [3], we exploit this algorithm to propose an online algorithm for learning and prediction of tensors with provable regret guarantees. Simulations results are presented on semi-synthetic data sets of ratings evolving in time under local influence over a social network. The result indicate superior performance compared to other (online) convex tensor completion methods.
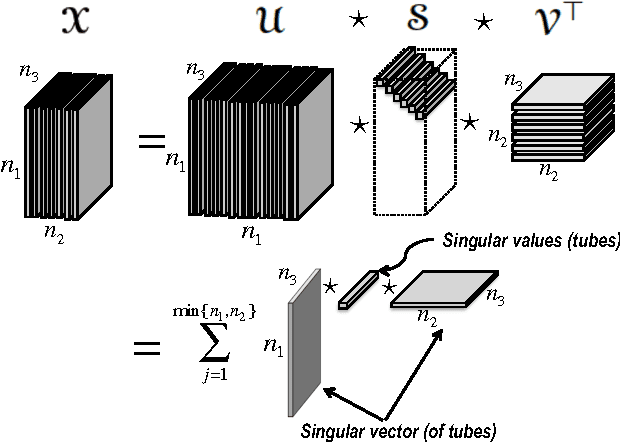
Exact tensor completion using t-SVD
Feb 27, 2015
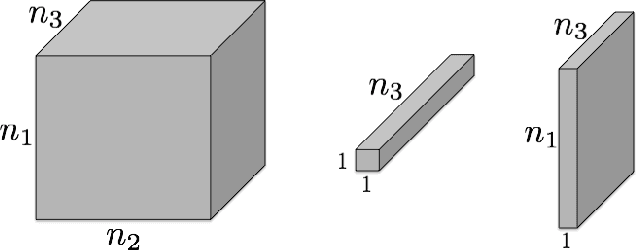
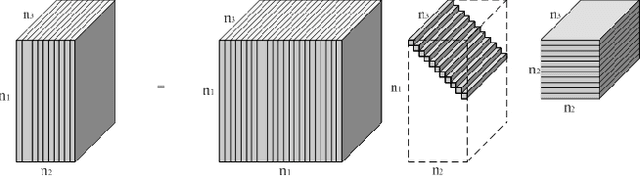

In this paper we focus on the problem of completion of multidimensional arrays (also referred to as tensors) from limited sampling. Our approach is based on a recently proposed tensor-Singular Value Decomposition (t-SVD) [1]. Using this factorization one can derive notion of tensor rank, referred to as the tensor tubal rank, which has optimality properties similar to that of matrix rank derived from SVD. As shown in [2] some multidimensional data, such as panning video sequences exhibit low tensor tubal rank and we look at the problem of completing such data under random sampling of the data cube. We show that by solving a convex optimization problem, which minimizes the tensor nuclear norm obtained as the convex relaxation of tensor tubal rank, one can guarantee recovery with overwhelming probability as long as samples in proportion to the degrees of freedom in t-SVD are observed. In this sense our results are order-wise optimal. The conditions under which this result holds are very similar to the incoherency conditions for the matrix completion, albeit we define incoherency under the algebraic set-up of t-SVD. We show the performance of the algorithm on some real data sets and compare it with other existing approaches based on tensor flattening and Tucker decomposition.