 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the modes of convergence of Stochastic Optimistic Mirror Descent for saddle point problems
Aug 02, 2019In this article, we study the convergence of Mirror Descent (MD) and Optimistic Mirror Descent (OMD) for saddle point problems satisfying the notion of coherence as proposed in Mertikopoulos et al. We prove convergence of OMD with exact gradients for coherent saddle point problems, and show that monotone convergence only occurs after some sufficiently large number of iterations. This is in contrast to the claim in Mertikopoulos et al. of monotone convergence of OMD with exact gradients for coherent saddle point problems. Besides highlighting this important subtlety, we note that the almost sure convergence guarantees of MD and OMD with stochastic gradients for strictly coherent saddle point problems that are claimed in Mertikopoulos et al. are not fully justified by their proof. As such, we fill out the missing details in the proof and as a result have only been able to prove convergence with high probability. We would like to note that our analysis relies heavily on the core ideas and proof techniques introduced in Zhou et al. and Mertikopoulos et al., and we only aim to re-state and correct the results in light of what we were able to prove rigorously while filling in the much needed missing details in their proofs.
Multi-View Graph Embedding Using Randomized Shortest Paths
Aug 20, 2018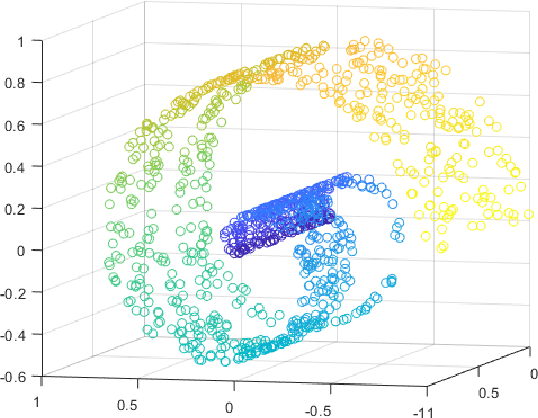
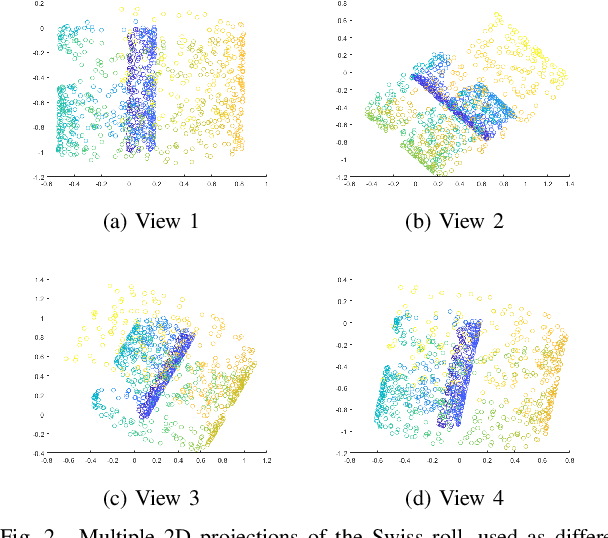

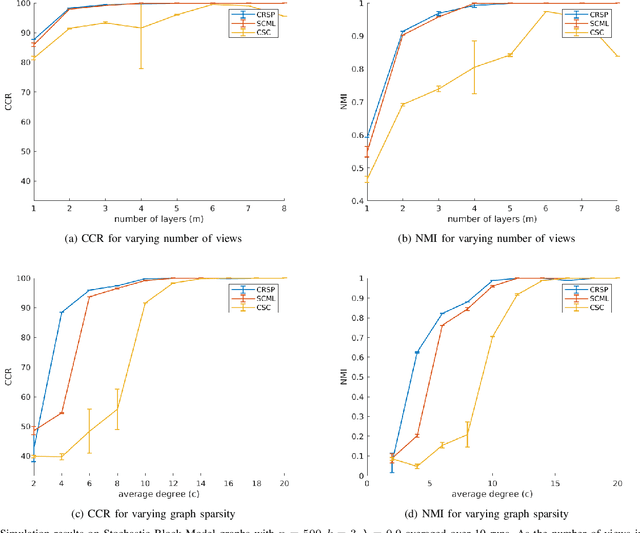
Real-world data sets often provide multiple types of information about the same set of entities. This data is well represented by multi-view graphs, which consist of several distinct sets of edges over the same nodes. These can be used to analyze how entities interact from different viewpoints. Combining multiple views improves the quality of inferences drawn from the underlying data, which has increased interest in developing efficient multi-view graph embedding methods. We propose an algorithm, C-RSP, that generates a common (C) embedding of a multi-view graph using Randomized Shortest Paths (RSP). This algorithm generates a dissimilarity measure between nodes by minimizing the expected cost of a random walk between any two nodes across all views of a multi-view graph, in doing so encoding both the local and global structure of the graph. We test C-RSP on both real and synthetic data and show that it outperforms benchmark algorithms at embedding and clustering tasks while remaining computationally efficient.
Principal Component Analysis with Tensor Train Subspace
Mar 13, 2018

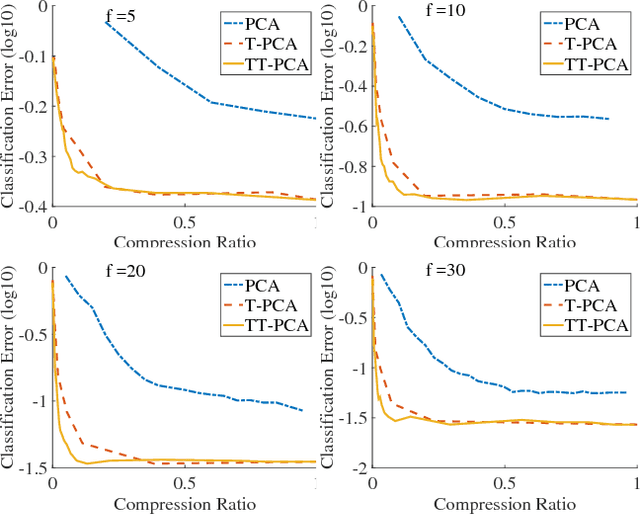
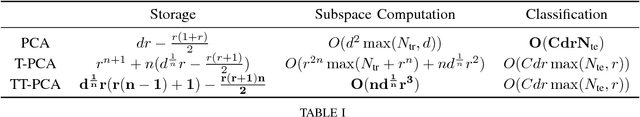
Tensor train is a hierarchical tensor network structure that helps alleviate the curse of dimensionality by parameterizing large-scale multidimensional data via a set of network of low-rank tensors. Associated with such a construction is a notion of Tensor Train subspace and in this paper we propose a TT-PCA algorithm for estimating this structured subspace from the given data. By maintaining low rank tensor structure, TT-PCA is more robust to noise comparing with PCA or Tucker-PCA. This is borne out numerically by testing the proposed approach on the Extended YaleFace Dataset B.
Tensor Train Neighborhood Preserving Embedding
Mar 10, 2018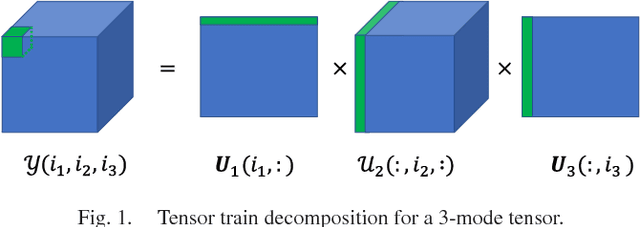
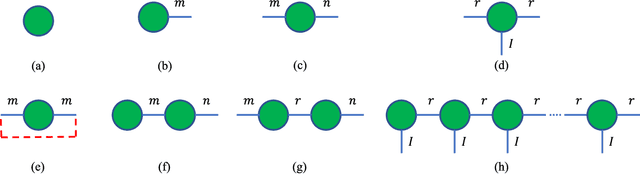
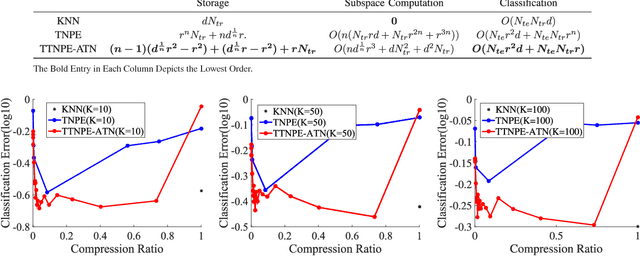
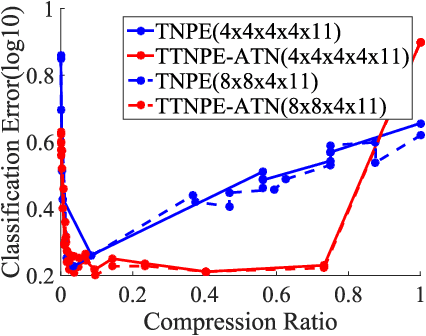
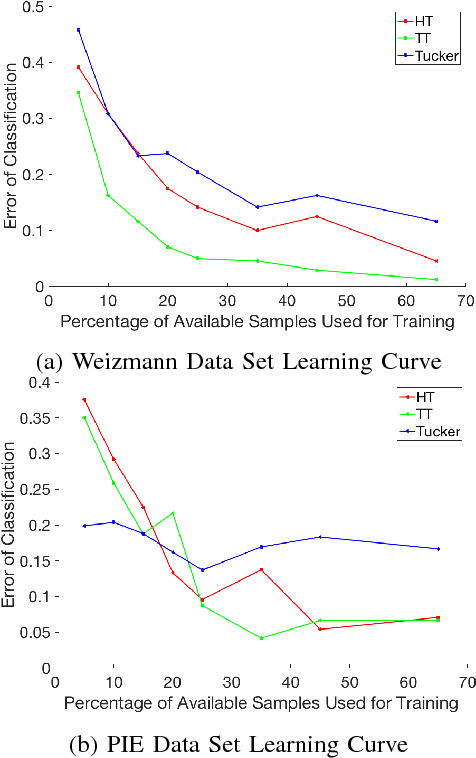
In this paper, we propose a Tensor Train Neighborhood Preserving Embedding (TTNPE) to embed multi-dimensional tensor data into low dimensional tensor subspace. Novel approaches to solve the optimization problem in TTNPE are proposed. For this embedding, we evaluate novel trade-off gain among classification, computation, and dimensionality reduction (storage) for supervised learning. It is shown that compared to the state-of-the-arts tensor embedding methods, TTNPE achieves superior trade-off in classification, computation, and dimensionality reduction in MNIST handwritten digits and Weizmann face datasets.
Word Embeddings via Tensor Factorization
Sep 15, 2017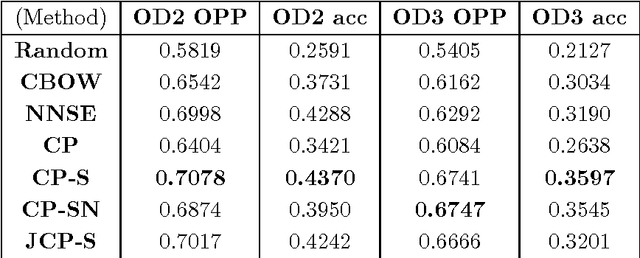
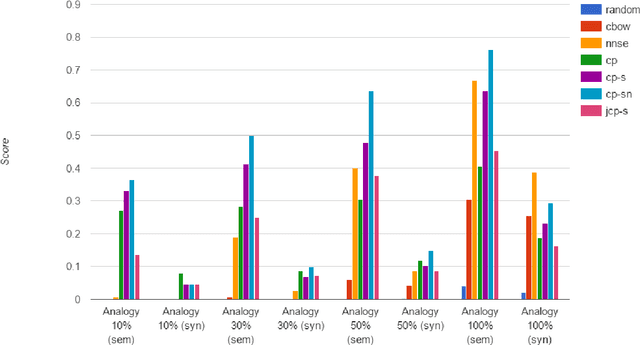
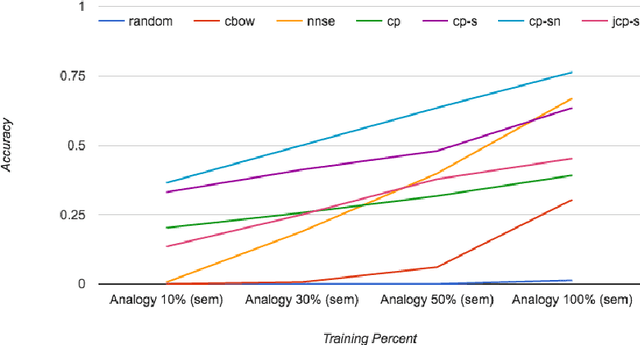
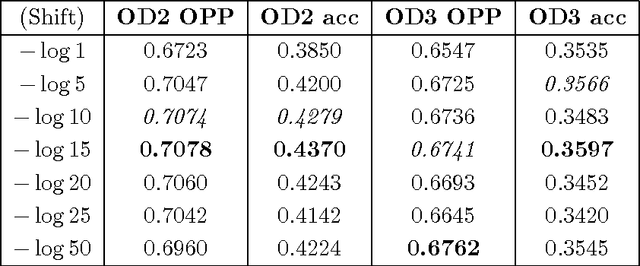
Most popular word embedding techniques involve implicit or explicit factorization of a word co-occurrence based matrix into low rank factors. In this paper, we aim to generalize this trend by using numerical methods to factor higher-order word co-occurrence based arrays, or \textit{tensors}. We present four word embeddings using tensor factorization and analyze their advantages and disadvantages. One of our main contributions is a novel joint symmetric tensor factorization technique related to the idea of coupled tensor factorization. We show that embeddings based on tensor factorization can be used to discern the various meanings of polysemous words without being explicitly trained to do so, and motivate the intuition behind why this works in a way that doesn't with existing methods. We also modify an existing word embedding evaluation metric known as Outlier Detection [Camacho-Collados and Navigli, 2016] to evaluate the quality of the order-$N$ relations that a word embedding captures, and show that tensor-based methods outperform existing matrix-based methods at this task. Experimentally, we show that all of our word embeddings either outperform or are competitive with state-of-the-art baselines commonly used today on a variety of recent datasets. Suggested applications of tensor factorization-based word embeddings are given, and all source code and pre-trained vectors are publicly available online.
Faster Clustering via Non-Backtracking Random Walks
Aug 26, 2017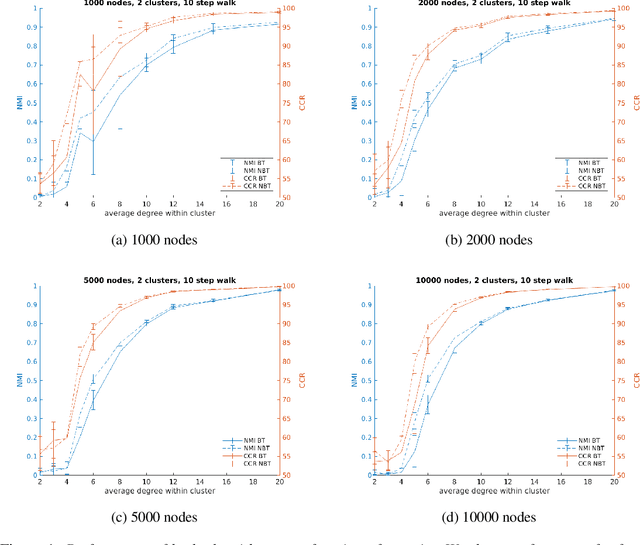
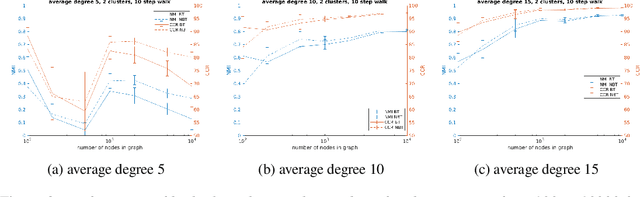
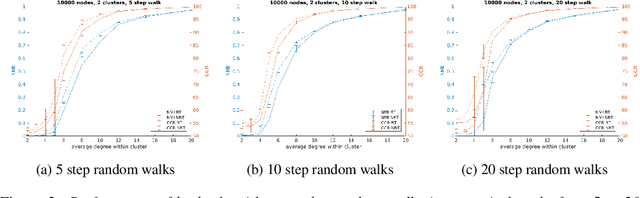
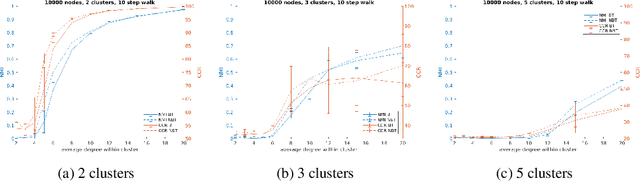
This paper presents VEC-NBT, a variation on the unsupervised graph clustering technique VEC, which improves upon the performance of the original algorithm significantly for sparse graphs. VEC employs a novel application of the state-of-the-art word2vec model to embed a graph in Euclidean space via random walks on the nodes of the graph. In VEC-NBT, we modify the original algorithm to use a non-backtracking random walk instead of the normal backtracking random walk used in VEC. We introduce a modification to a non-backtracking random walk, which we call a begrudgingly-backtracking random walk, and show empirically that using this model of random walks for VEC-NBT requires shorter walks on the graph to obtain results with comparable or greater accuracy than VEC, especially for sparser graphs.
Efficient Low Rank Tensor Ring Completion
Jul 23, 2017
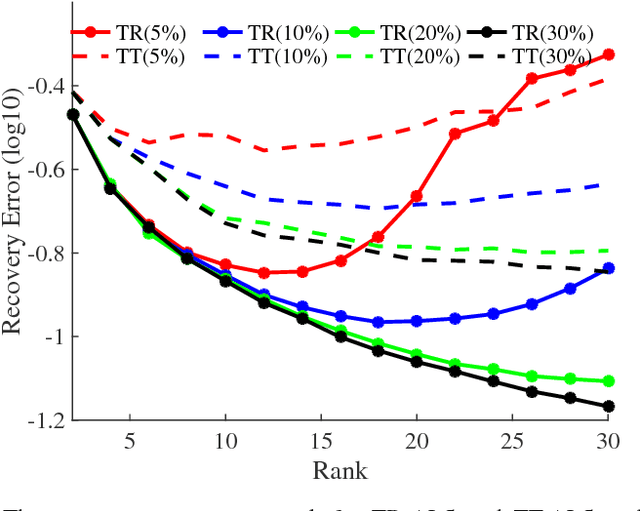


Using the matrix product state (MPS) representation of the recently proposed tensor ring decompositions, in this paper we propose a tensor completion algorithm, which is an alternating minimization algorithm that alternates over the factors in the MPS representation. This development is motivated in part by the success of matrix completion algorithms that alternate over the (low-rank) factors. In this paper, we propose a spectral initialization for the tensor ring completion algorithm and analyze the computational complexity of the proposed algorithm. We numerically compare it with existing methods that employ a low rank tensor train approximation for data completion and show that our method outperforms the existing ones for a variety of real computer vision settings, and thus demonstrate the improved expressive power of tensor ring as compared to tensor train.
Sample, computation vs storage tradeoffs for classification using tensor subspace models
Jun 27, 2017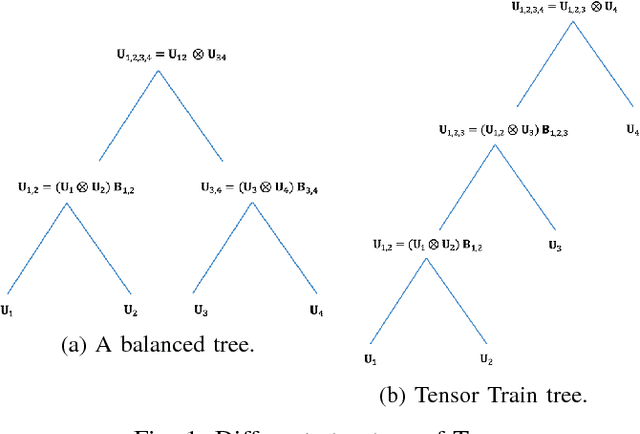
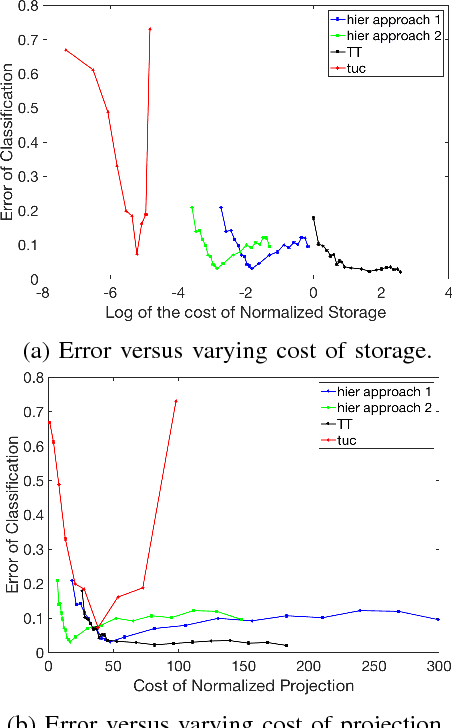
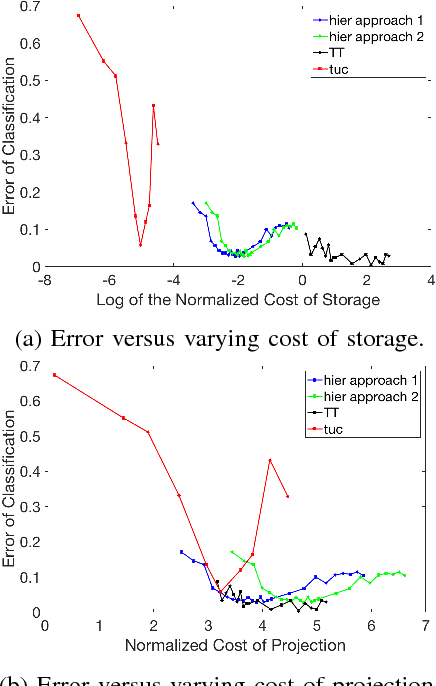
In this paper, we exhibit the tradeoffs between the (training) sample, computation and storage complexity for the problem of supervised classification using signal subspace estimation. Our main tool is the use of tensor subspaces, i.e. subspaces with a Kronecker structure, for embedding the data into lower dimensions. Among the subspaces with a Kronecker structure, we show that using subspaces with a hierarchical structure for representing data leads to improved tradeoffs. One of the main reasons for the improvement is that embedding data into these hierarchical Kronecker structured subspaces prevents overfitting at higher latent dimensions.
Unsupervised clustering under the Union of Polyhedral Cones (UOPC) model
Oct 15, 2016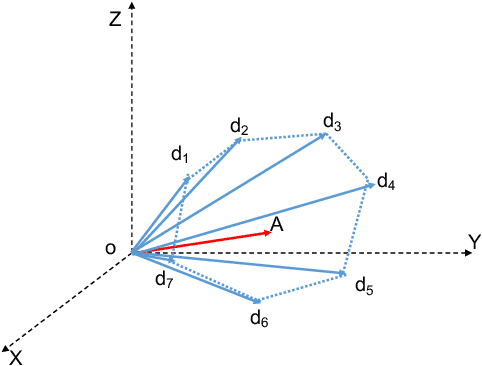
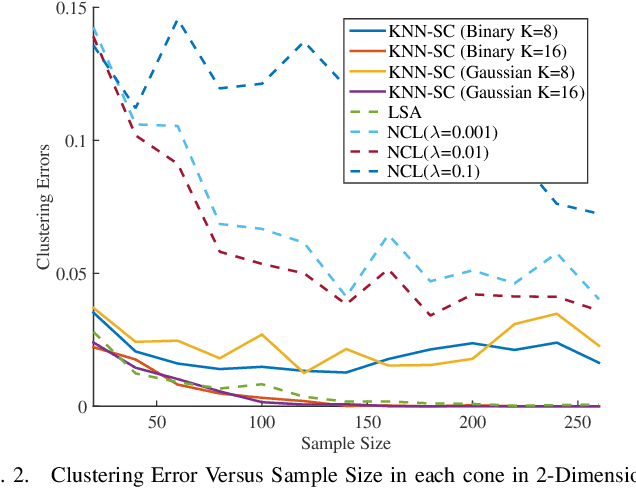
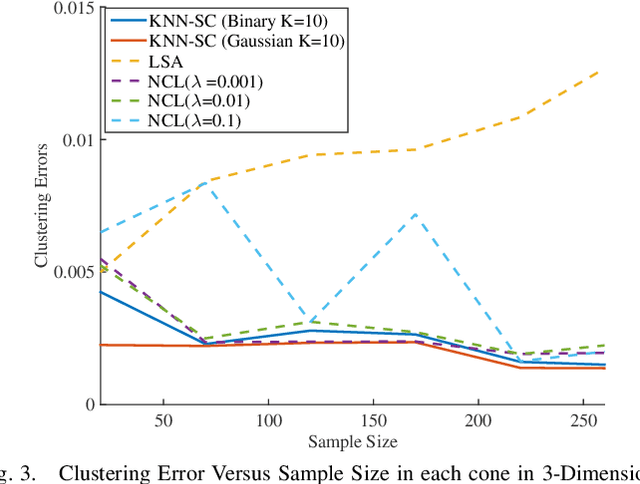
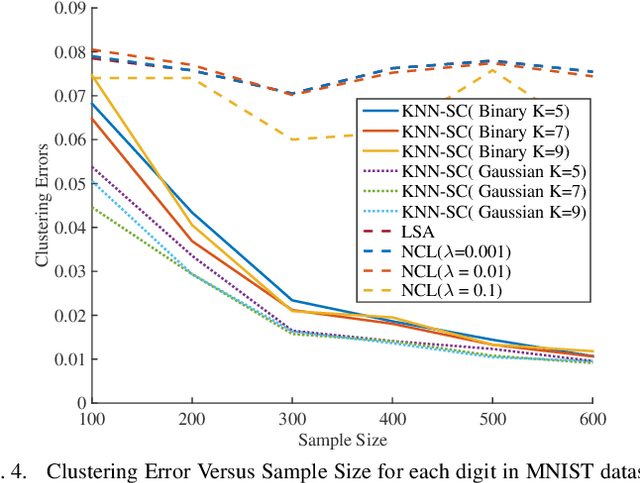
In this paper, we consider clustering data that is assumed to come from one of finitely many pointed convex polyhedral cones. This model is referred to as the Union of Polyhedral Cones (UOPC) model. Similar to the Union of Subspaces (UOS) model where each data from each subspace is generated from a (unknown) basis, in the UOPC model each data from each cone is assumed to be generated from a finite number of (unknown) \emph{extreme rays}.To cluster data under this model, we consider several algorithms - (a) Sparse Subspace Clustering by Non-negative constraints Lasso (NCL), (b) Least squares approximation (LSA), and (c) K-nearest neighbor (KNN) algorithm to arrive at affinity between data points. Spectral Clustering (SC) is then applied on the resulting affinity matrix to cluster data into different polyhedral cones. We show that on an average KNN outperforms both NCL and LSA and for this algorithm we provide the deterministic conditions for correct clustering. For an affinity measure between the cones it is shown that as long as the cones are not very coherent and as long as the density of data within each cone exceeds a threshold, KNN leads to accurate clustering. Finally, simulation results on real datasets (MNIST and YaleFace datasets) depict that the proposed algorithm works well on real data indicating the utility of the UOPC model and the proposed algorithm.
Low-tubal-rank Tensor Completion using Alternating Minimization
Oct 05, 2016The low-tubal-rank tensor model has been recently proposed for real-world multidimensional data. In this paper, we study the low-tubal-rank tensor completion problem, i.e., to recover a third-order tensor by observing a subset of its elements selected uniformly at random. We propose a fast iterative algorithm, called {\em Tubal-Alt-Min}, that is inspired by a similar approach for low-rank matrix completion. The unknown low-tubal-rank tensor is represented as the product of two much smaller tensors with the low-tubal-rank property being automatically incorporated, and Tubal-Alt-Min alternates between estimating those two tensors using tensor least squares minimization. First, we note that tensor least squares minimization is different from its matrix counterpart and nontrivial as the circular convolution operator of the low-tubal-rank tensor model is intertwined with the sub-sampling operator. Second, the theoretical performance guarantee is challenging since Tubal-Alt-Min is iterative and nonconvex in nature. We prove that 1) Tubal-Alt-Min guarantees exponential convergence to the global optima, and 2) for an $n \times n \times k$ tensor with tubal-rank $r \ll n$, the required sampling complexity is $O(nr^2k \log^3 n)$ and the computational complexity is $O(n^2rk^2 \log^2 n)$. Third, on both synthetic data and real-world video data, evaluation results show that compared with tensor-nuclear norm minimization (TNN-ADMM), Tubal-Alt-Min improves the recovery error dramatically (by orders of magnitude). It is estimated that Tubal-Alt-Min converges at an exponential rate $10^{-0.4423 \text{Iter}}$ where $\text{Iter}$ denotes the number of iterations, which is much faster than TNN-ADMM's $10^{-0.0332 \text{Iter}}$, and the running time can be accelerated by more than $5$ times for a $200 \times 200 \times 20$ tensor.