 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Counting with Small Datasets of Large Images
May 28, 2018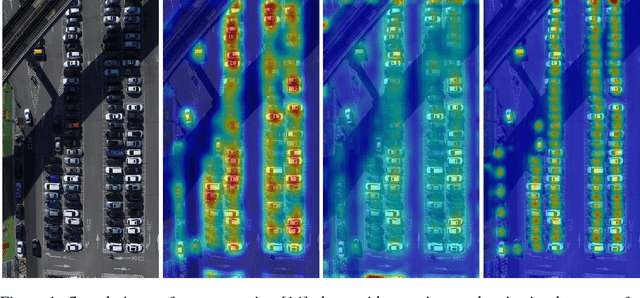

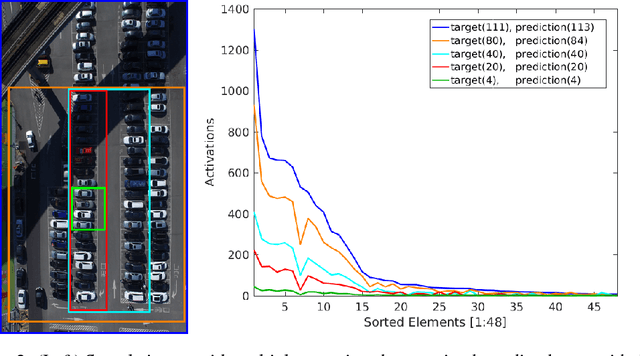
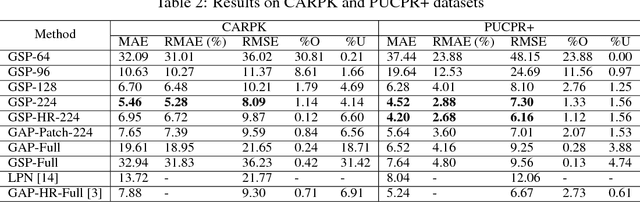
We explore the problem of training one-look regression models for counting objects in datasets comprising a small number of high-resolution, variable-shaped images. To reduce overfitting when training on full resolution samples, we propose to use global sum pooling (GSP) instead of global average pooling (GAP) or fully connected (FC) layers at the backend of a convolutional neural network. Although computationally equivalent to GAP, we show via detailed experimentation that GSP allows convolutional networks to learn the counting task as a simple linear mapping problem generalized over the input shape and the number of objects present. We evaluate our approach on four different aerial image datasets - three car counting datasets (CARPK, PUCPR+, and COWC) and one new challenging dataset for wheat spike counting. Our GSP approach achieves state-of-the-art performance on all four datasets and GSP models trained with smaller-sized image patches localize objects better than their GAP counterparts.
Semantic Binary Segmentation using Convolutional Networks without Decoders
May 25, 2018

In this paper, we propose an efficient architecture for semantic image segmentation using the depth-to-space (D2S) operation. Our D2S model is comprised of a standard CNN encoder followed by a depth-to-space reordering of the final convolutional feature maps. Our approach eliminates the decoder portion of traditional encoder-decoder segmentation models and reduces the amount of computation almost by half. As a participant of the DeepGlobe Road Extraction competition, we evaluate our models on the corresponding road segmentation dataset. Our highly efficient D2S models exhibit comparable performance to standard segmentation models with much lower computational cost.
Improving Object Counting with Heatmap Regulation
May 23, 2018



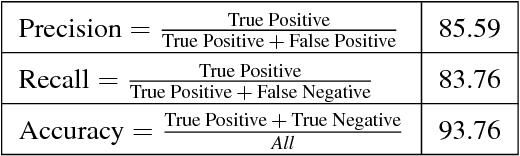
In this paper, we propose a simple and effective way to improve one-look regression models for object counting from images. We use class activation map visualizations to illustrate the drawbacks of learning a pure one-look regression model for a counting task. Based on these insights, we enhance one-look regression counting models by regulating activation maps from the final convolution layer of the network with coarse ground-truth activation maps generated from simple dot annotations. We call this strategy heatmap regulation (HR). We show that this simple enhancement effectively suppresses false detections generated by the corresponding one-look baseline model and also improves the performance in terms of false negatives. Evaluations are performed on four different counting datasets --- two for car counting (CARPK, PUCPR+), one for crowd counting (WorldExpo) and another for biological cell counting (VGG-Cells). Adding HR to a simple VGG front-end improves performance on all these benchmarks compared to a simple one-look baseline model and results in state-of-the-art performance for car counting.
DeepWheat: Estimating Phenotypic Traits from Crop Images with Deep Learning
Jan 26, 2018
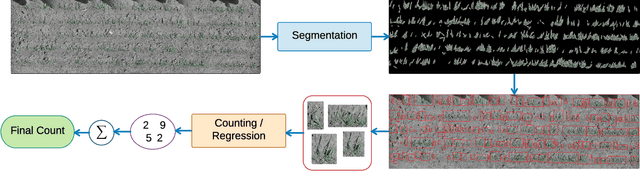
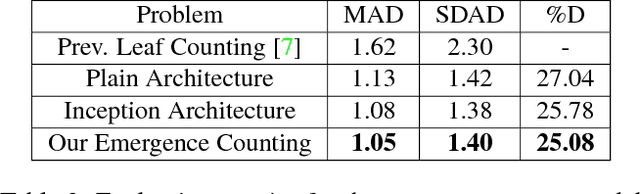
In this paper, we investigate estimating emergence and biomass traits from color images and elevation maps of wheat field plots. We employ a state-of-the-art deconvolutional network for segmentation and convolutional architectures, with residual and Inception-like layers, to estimate traits via high dimensional nonlinear regression. Evaluation was performed on two different species of wheat, grown in field plots for an experimental plant breeding study. Our framework achieves satisfactory performance with mean and standard deviation of absolute difference of 1.05 and 1.40 counts for emergence and 1.45 and 2.05 for biomass estimation. Our results for counting wheat plants from field images are better than the accuracy reported for the similar, but arguably less difficult, task of counting leaves from indoor images of rosette plants. Our results for biomass estimation, even with a very small dataset, improve upon all previously proposed approaches in the literature.
Leaf Counting with Deep Convolutional and Deconvolutional Networks
Aug 29, 2017



In this paper, we investigate the problem of counting rosette leaves from an RGB image, an important task in plant phenotyping. We propose a data-driven approach for this task generalized over different plant species and imaging setups. To accomplish this task, we use state-of-the-art deep learning architectures: a deconvolutional network for initial segmentation and a convolutional network for leaf counting. Evaluation is performed on the leaf counting challenge dataset at CVPPP-2017. Despite the small number of training samples in this dataset, as compared to typical deep learning image sets, we obtain satisfactory performance on segmenting leaves from the background as a whole and counting the number of leaves using simple data augmentation strategies. Comparative analysis is provided against methods evaluated on the previous competition datasets. Our framework achieves mean and standard deviation of absolute count difference of 1.62 and 2.30 averaged over all five test datasets.