 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Cropping on Twitter: Fairness Metrics, their Limitations, and the Importance of Representation, Design, and Agency
May 18, 2021
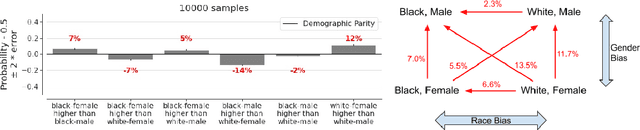
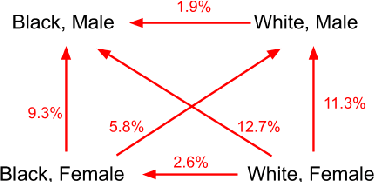
Twitter uses machine learning to crop images, where crops are centered around the part predicted to be the most salient. In fall 2020, Twitter users raised concerns that the automated image cropping system on Twitter favored light-skinned over dark-skinned individuals, as well as concerns that the system favored cropping woman's bodies instead of their heads. In order to address these concerns, we conduct an extensive analysis using formalized group fairness metrics. We find systematic disparities in cropping and identify contributing factors, including the fact that the cropping based on the single most salient point can amplify the disparities. However, we demonstrate that formalized fairness metrics and quantitative analysis on their own are insufficient for capturing the risk of representational harm in automatic cropping. We suggest the removal of saliency-based cropping in favor of a solution that better preserves user agency. For developing a new solution that sufficiently address concerns related to representational harm, our critique motivates a combination of quantitative and qualitative methods that include human-centered design.
Exploring multi-task multi-lingual learning of transformer models for hate speech and offensive speech identification in social media
Jan 27, 2021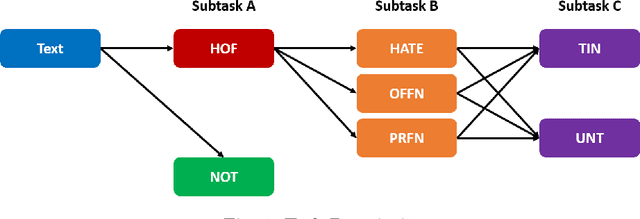
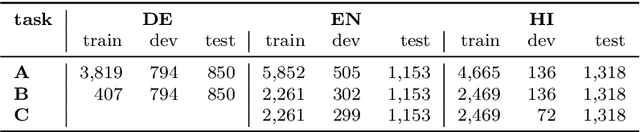
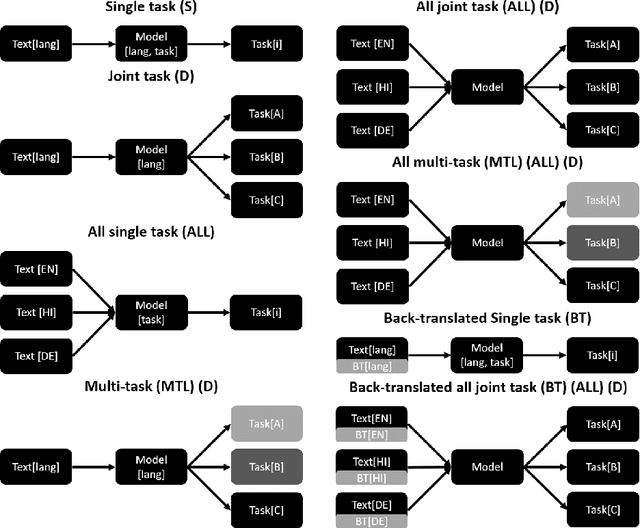
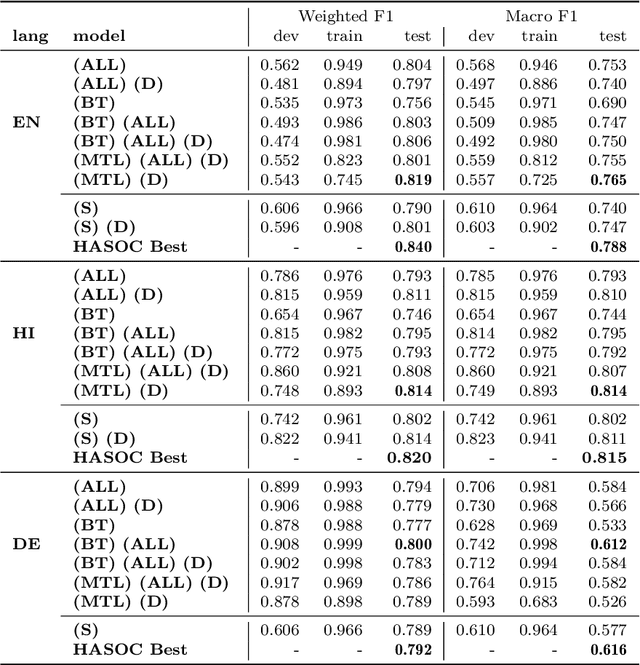
Hate Speech has become a major content moderation issue for online social media platforms. Given the volume and velocity of online content production, it is impossible to manually moderate hate speech related content on any platform. In this paper we utilize a multi-task and multi-lingual approach based on recently proposed Transformer Neural Networks to solve three sub-tasks for hate speech. These sub-tasks were part of the 2019 shared task on hate speech and offensive content (HASOC) identification in Indo-European languages. We expand on our submission to that competition by utilizing multi-task models which are trained using three approaches, a) multi-task learning with separate task heads, b) back-translation, and c) multi-lingual training. Finally, we investigate the performance of various models and identify instances where the Transformer based models perform differently and better. We show that it is possible to to utilize different combined approaches to obtain models that can generalize easily on different languages and tasks, while trading off slight accuracy (in some cases) for a much reduced inference time compute cost. We open source an updated version of our HASOC 2019 code with the new improvements at https://github.com/socialmediaie/MTML_HateSpeech.
A Framework for Generating Annotated Social Media Corpora with Demographics, Stance, Civility, and Topicality
Dec 10, 2020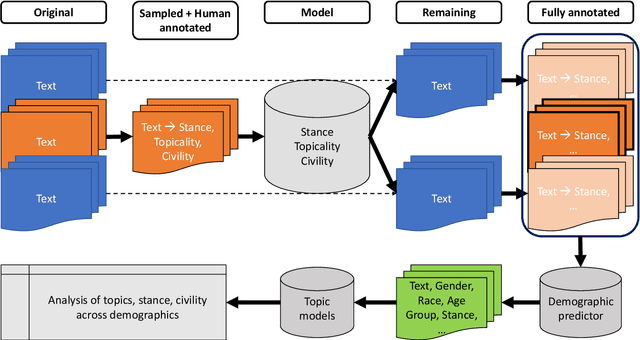
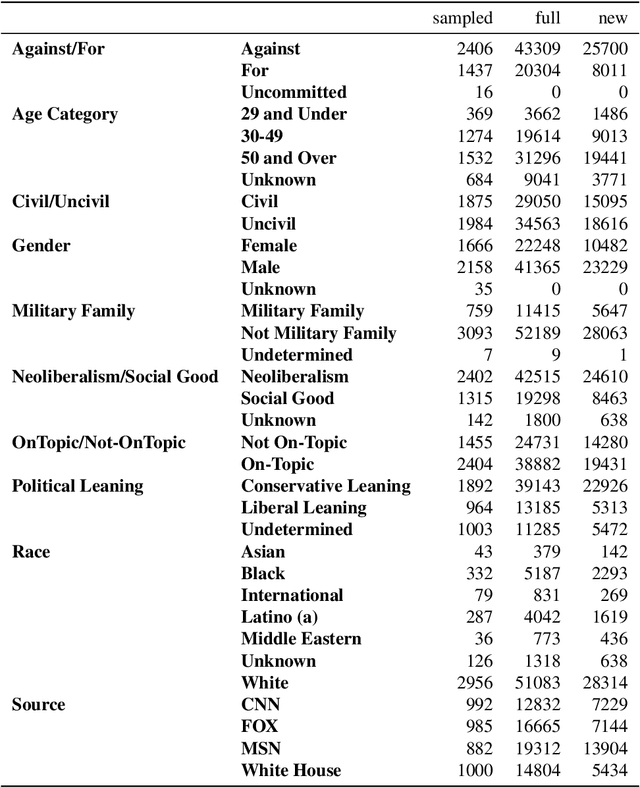
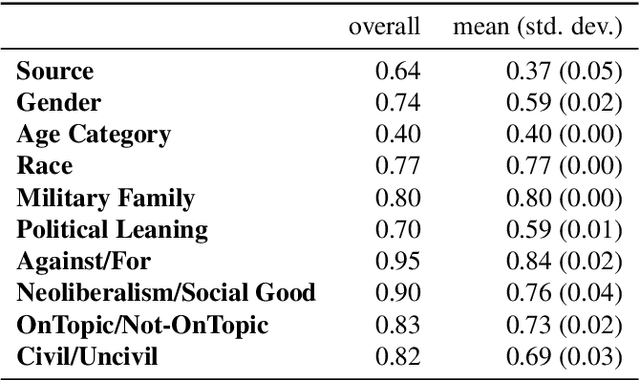
In this paper we introduce a framework for annotating a social media text corpora for various categories. Since, social media data is generated via individuals, it is important to annotate the text for the individuals demographic attributes to enable a socio-technical analysis of the corpora. Furthermore, when analyzing a large data-set we can often annotate a small sample of data and then train a prediction model using this sample to annotate the full data for the relevant categories. We use a case study of a Facebook comment corpora on student loan discussion which was annotated for gender, military affiliation, age-group, political leaning, race, stance, topicalilty, neoliberlistic views and civility of the comment. We release three datasets of Facebook comments for further research at: https://github.com/socialmediaie/StudentDebtFbComments
Assessing Demographic Bias in Named Entity Recognition
Aug 08, 2020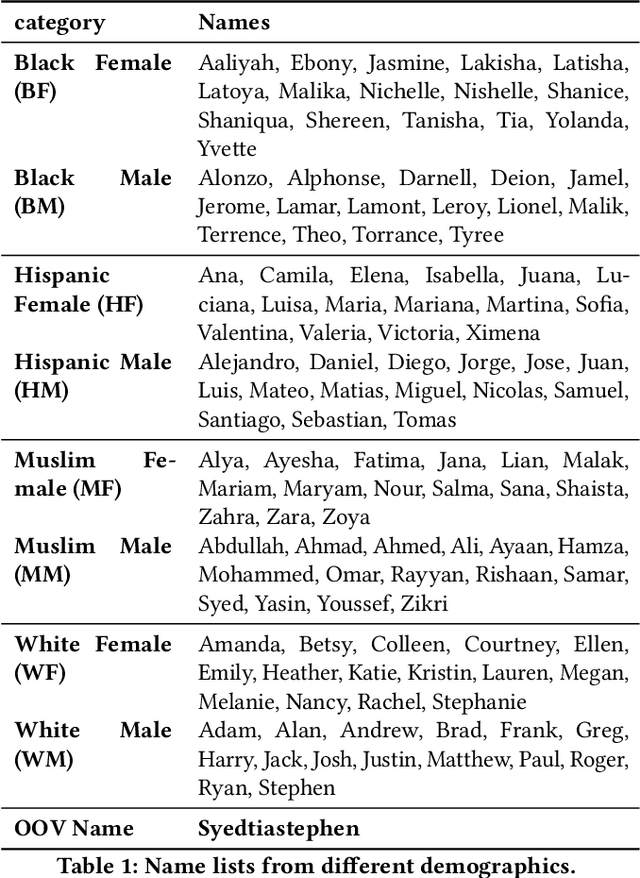
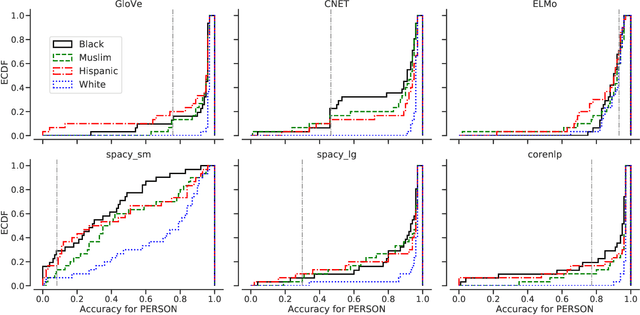

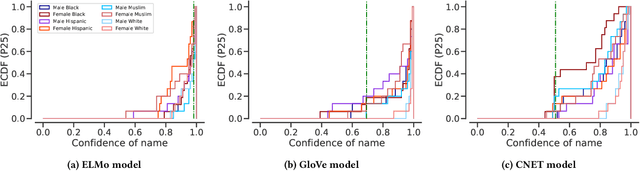
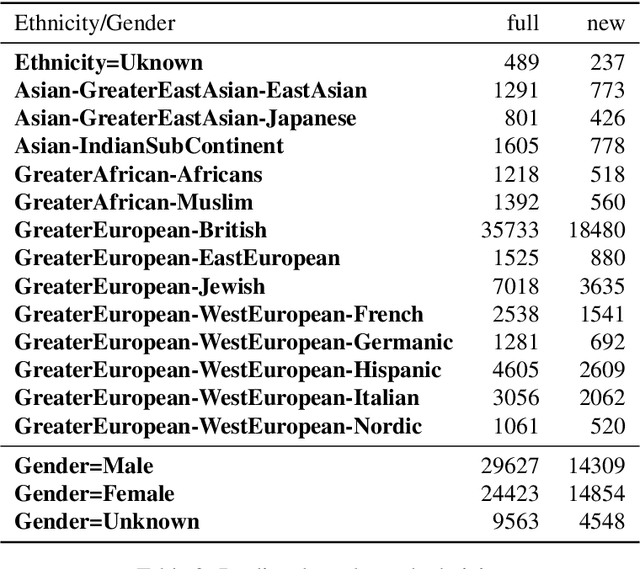
Named Entity Recognition (NER) is often the first step towards automated Knowledge Base (KB) generation from raw text. In this work, we assess the bias in various Named Entity Recognition (NER) systems for English across different demographic groups with synthetically generated corpora. Our analysis reveals that models perform better at identifying names from specific demographic groups across two datasets. We also identify that debiased embeddings do not help in resolving this issue. Finally, we observe that character-based contextualized word representation models such as ELMo results in the least bias across demographics. Our work can shed light on potential biases in automated KB generation due to systematic exclusion of named entities belonging to certain demographics.