 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepPolar+: Breaking the BER-BLER Trade-off with Self-Attention and SMART (SNR-MAtched Redundancy Technique) decoding
Jun 11, 2025DeepPolar codes have recently emerged as a promising approach for channel coding, demonstrating superior bit error rate (BER) performance compared to conventional polar codes. Despite their excellent BER characteristics, these codes exhibit suboptimal block error rate (BLER) performance, creating a fundamental BER-BLER trade-off that severely limits their practical deployment in communication systems. This paper introduces DeepPolar+, an enhanced neural polar coding framework that systematically eliminates this BER-BLER trade-off by simultaneously improving BLER performance while maintaining the superior BER characteristics of DeepPolar codes. Our approach achieves this breakthrough through three key innovations: (1) an attention-enhanced decoder architecture that leverages multi-head self-attention mechanisms to capture complex dependencies between bit positions, (2) a structured loss function that jointly optimizes for both bit-level accuracy and block-level reliability, and (3) an adaptive SNR-Matched Redundancy Technique (SMART) for decoding DeepPolar+ code (DP+SMART decoder) that combines specialized models with CRC verification for robust performance across diverse channel conditions. For a (256,37) code configuration, DeepPolar+ demonstrates notable improvements in both BER and BLER performance compared to conventional successive cancellation decoding and DeepPolar, while achieving remarkably faster convergence through improved architecture and optimization strategies. The DeepPolar+SMART variant further amplifies these dual improvements, delivering significant gains in both error rate metrics over existing approaches. DeepPolar+ effectively bridges the gap between theoretical potential and practical implementation of neural polar codes, offering a viable path forward for next-generation error correction systems.
DCT-CompCNN: A Novel Image Classification Network Using JPEG Compressed DCT Coefficients
Jul 26, 2019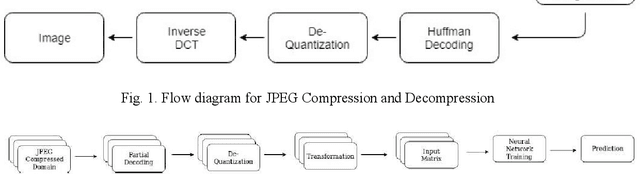
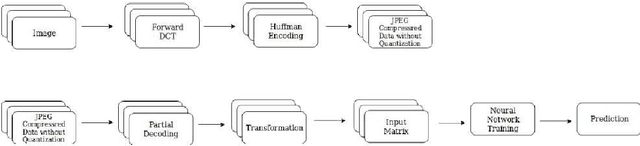
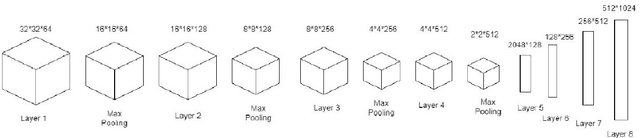
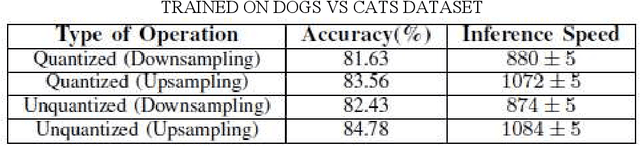
The popularity of Convolutional Neural Network (CNN) in the field of Image Processing and Computer Vision has motivated researchers and industrialist experts across the globe to solve different challenges with high accuracy. The simplest way to train a CNN classifier is to directly feed the original RGB pixels images into the network. However, if we intend to classify images directly with its compressed data, the same approach may not work better, like in case of JPEG compressed images. This research paper investigates the issues of modifying the input representation of the JPEG compressed data, and then feeding into the CNN. The architecture is termed as DCT-CompCNN. This novel approach has shown that CNNs can also be trained with JPEG compressed DCT coefficients, and subsequently can produce a better performance in comparison with the conventional CNN approach. The efficiency of the modified input representation is tested with the existing ResNet-50 architecture and the proposed DCT-CompCNN architecture on a public image classification datasets like Dog Vs Cat and CIFAR-10 datasets, reporting a better performance