 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreatment Effect Estimation for Graph-Structured Targets
Dec 29, 2024Treatment effect estimation, which helps understand the causality between treatment and outcome variable, is a central task in decision-making across various domains. While most studies focus on treatment effect estimation on individual targets, in specific contexts, there is a necessity to comprehend the treatment effect on a group of targets, especially those that have relationships represented as a graph structure between them. In such cases, the focus of treatment assignment is prone to depend on a particular node of the graph, such as the one with the highest degree, thus resulting in an observational bias from a small part of the entire graph. Whereas a bias tends to be caused by the small part, straightforward extensions of previous studies cannot provide efficient bias mitigation owing to the use of the entire graph information. In this study, we propose Graph-target Treatment Effect Estimation (GraphTEE), a framework designed to estimate treatment effects specifically on graph-structured targets. GraphTEE aims to mitigate observational bias by focusing on confounding variable sets and consider a new regularization framework. Additionally, we provide a theoretical analysis on how GraphTEE performs better in terms of bias mitigation. Experiments on synthetic and semi-synthetic datasets demonstrate the effectiveness of our proposed method.
GraphITE: Estimating Individual Effects of Graph-structured Treatments
Sep 29, 2020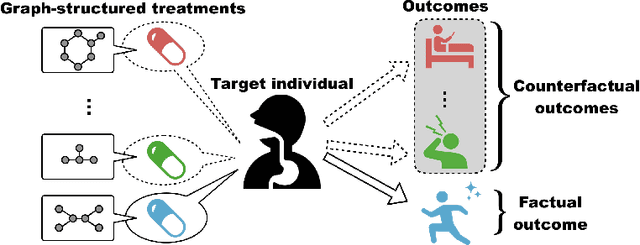
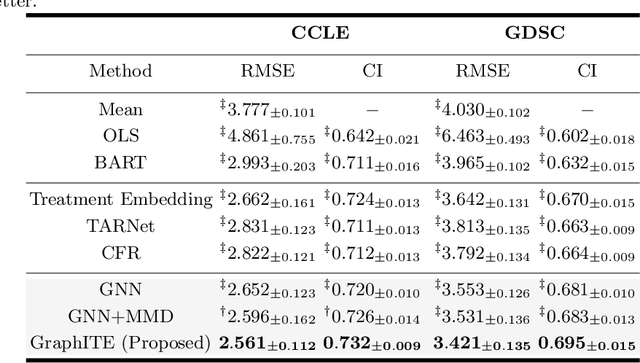
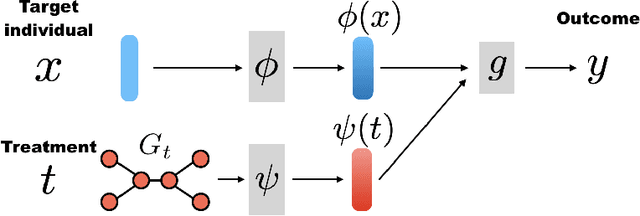
Outcome estimation of treatments for target individuals is an important foundation for decision making based on causal relations. Most existing outcome estimation methods deal with binary or multiple-choice treatments; however, in some applications, the number of treatments can be significantly large, while the treatments themselves have rich information. In this study, we considered one important instance of such cases: the outcome estimation problem of graph-structured treatments such as drugs. Owing to the large number of possible treatments, the counterfactual nature of observational data that appears in conventional treatment effect estimation becomes more of a concern for this problem. Our proposed method, GraphITE (pronounced "graphite") learns the representations of graph-structured treatments using graph neural networks while mitigating observation biases using Hilbert-Schmidt Independence Criterion regularization, which increases the independence of the representations of the targets and treatments. Experiments on two real-world datasets show that GraphITE outperforms baselines, especially in cases with a large number of treatments.
Counterfactual Propagation for Semi-Supervised Individual Treatment Effect Estimation
May 11, 2020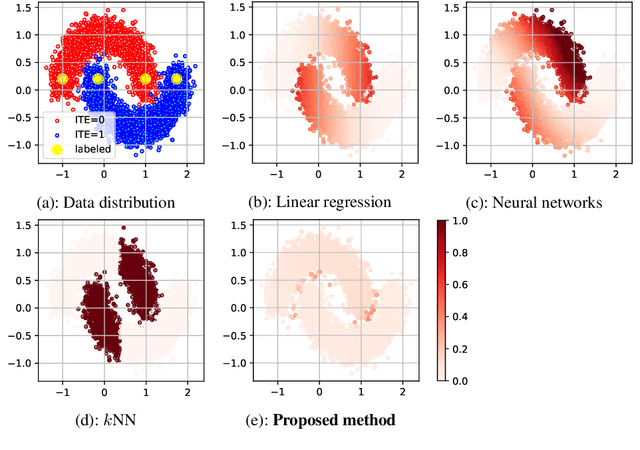
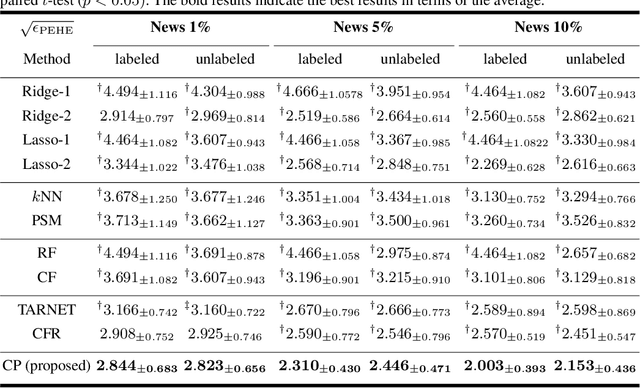
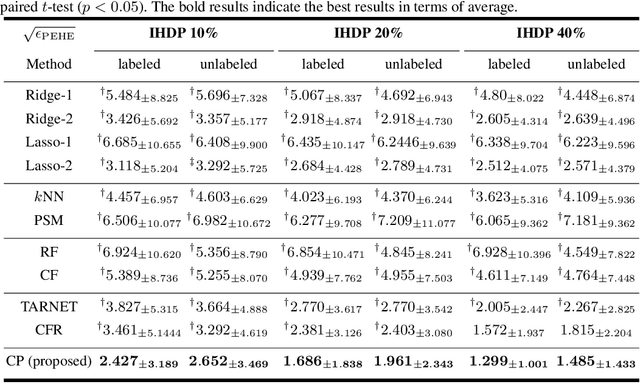
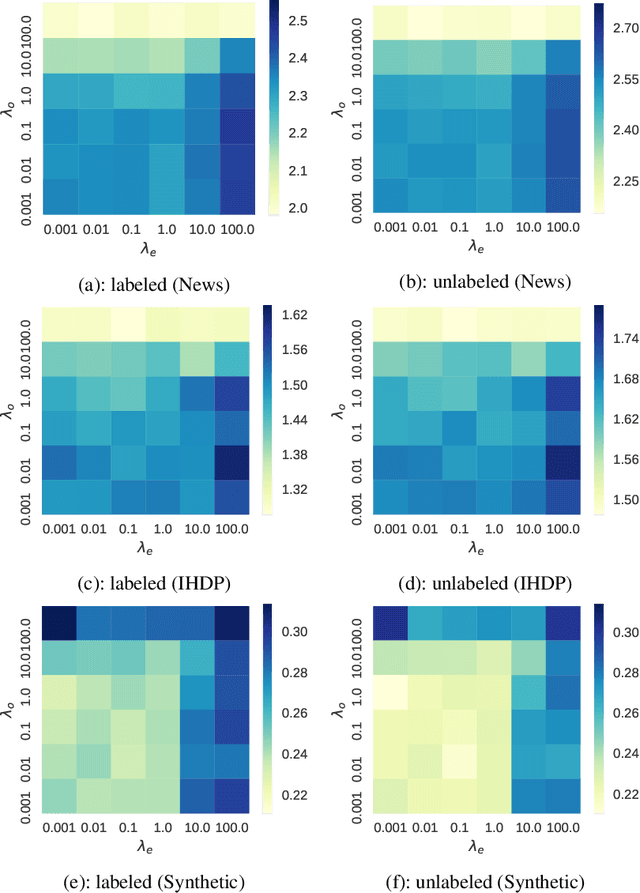
Individual treatment effect (ITE) represents the expected improvement in the outcome of taking a particular action to a particular target, and plays important roles in decision making in various domains. However, its estimation problem is difficult because intervention studies to collect information regarding the applied treatments (i.e., actions) and their outcomes are often quite expensive in terms of time and monetary costs. In this study, we consider a semi-supervised ITE estimation problem that exploits more easily-available unlabeled instances to improve the performance of ITE estimation using small labeled data. We combine two ideas from causal inference and semi-supervised learning, namely, matching and label propagation, respectively, to propose counterfactual propagation, which is the first semi-supervised ITE estimation method. Experiments using semi-real datasets demonstrate that the proposed method can successfully mitigate the data scarcity problem in ITE estimation.