 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery of Causal Additive Models in the Presence of Unobserved Variables
Jun 04, 2021
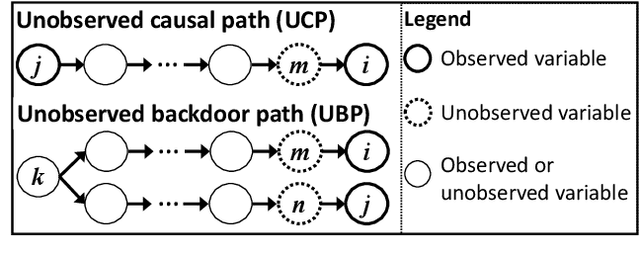
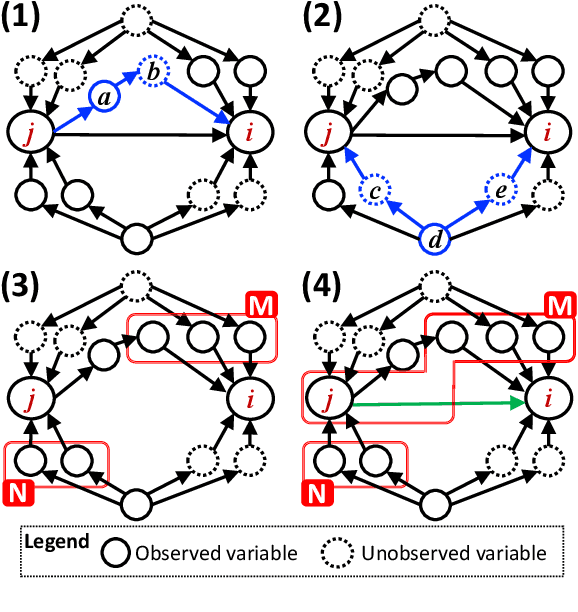
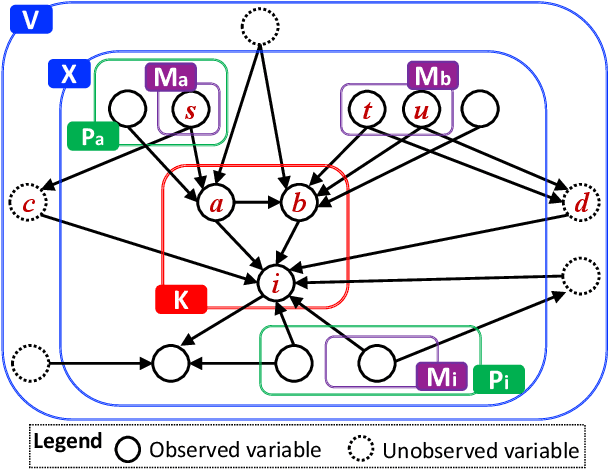
Causal discovery from data affected by unobserved variables is an important but difficult problem to solve. The effects that unobserved variables have on the relationships between observed variables are more complex in nonlinear cases than in linear cases. In this study, we focus on causal additive models in the presence of unobserved variables. Causal additive models exhibit structural equations that are additive in the variables and error terms. We take into account the presence of not only unobserved common causes but also unobserved intermediate variables. Our theoretical results show that, when the causal relationships are nonlinear and there are unobserved variables, it is not possible to identify all the causal relationships between observed variables through regression and independence tests. However, our theoretical results also show that it is possible to avoid incorrect inferences. We propose a method to identify all the causal relationships that are theoretically possible to identify without being biased by unobserved variables. The empirical results using artificial data and simulated functional magnetic resonance imaging (fMRI) data show that our method effectively infers causal structures in the presence of unobserved variables.
Causal Discovery with Multi-Domain LiNGAM for Latent Factors
Sep 19, 2020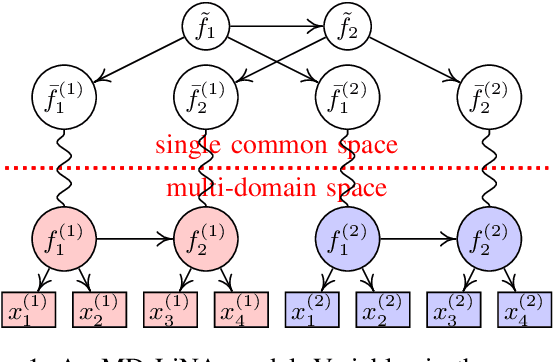
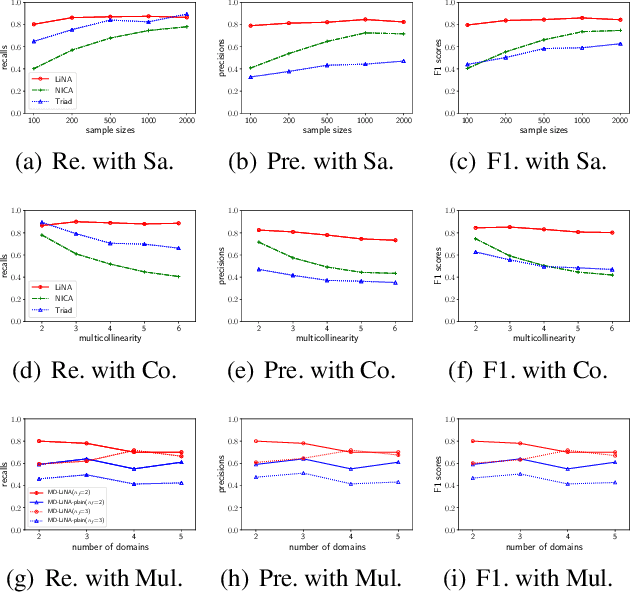
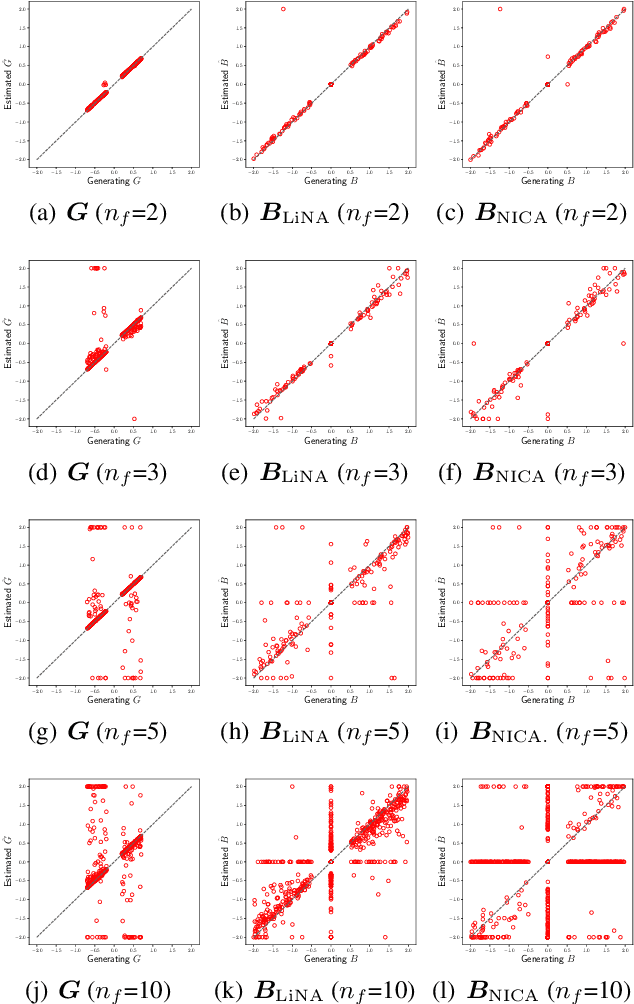
Discovering causal structures among latent factors from observed data is a particularly challenging problem, in which many empirical researchers are interested. Despite its success in certain degrees, existing methods focus on the single-domain observed data only, while in many scenarios data may be originated from distinct domains, e.g. in neuroinformatics. In this paper, we propose Multi-Domain Linear Non-Gaussian Acyclic Models for LAtent Factors (abbreviated as MD-LiNA model) to identify the underlying causal structure between latent factors (of interest), tackling not only single-domain observed data but multiple-domain ones, and provide its identification results. In particular, we first locate the latent factors and estimate the factor loadings matrix for each domain separately. Then to estimate the structure among latent factors (of interest), we derive a score function based on the characterization of independence relations between external influences and the dependence relations between multiple-domain latent factors and latent factors of interest, enforcing acyclicity, sparsity, and elastic net constraints. The resulting optimization thus produces asymptotically correct results. It also exhibits satisfactory capability in regimes of small sample sizes or highly-correlated variables and simultaneously estimates the causal directions and effects between latent factors. Experimental results on both synthetic and real-world data demonstrate the efficacy of our approach.
Causal discovery of linear non-Gaussian acyclic models in the presence of latent confounders
Jan 14, 2020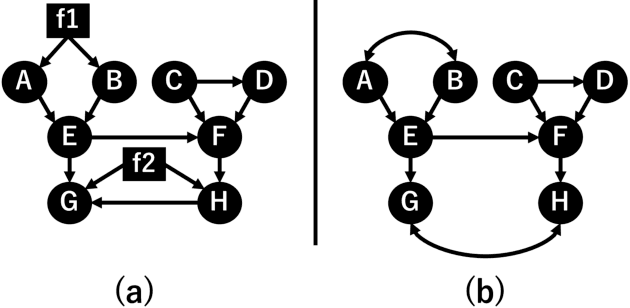
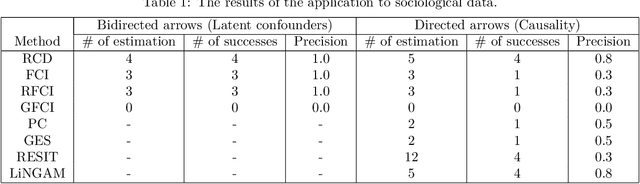
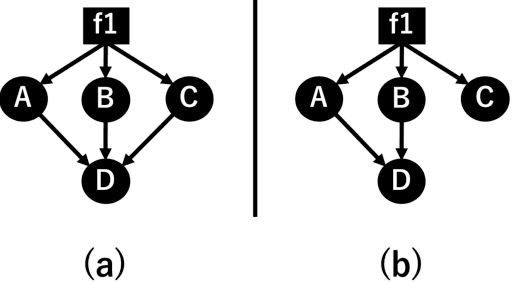
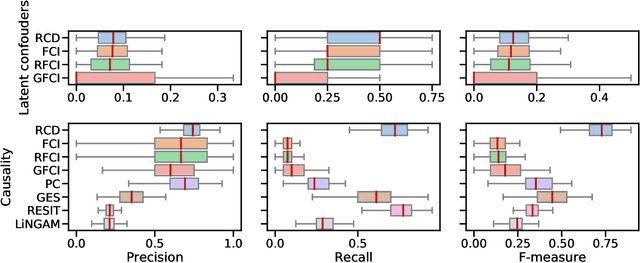
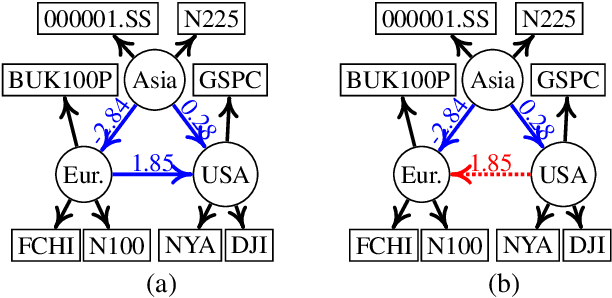
Causal discovery from data affected by latent confounders is an important and difficult challenge. Causal functional model-based approaches have not been used to present variables whose relationships are affected by latent confounders, while some constraint-based methods can present them. This paper proposes a causal functional model-based method called repetitive causal discovery (RCD) to discover the causal structure of observed variables affected by latent confounders. RCD repeats inferring the causal directions between a small number of observed variables and determines whether the relationships are affected by latent confounders. RCD finally produces a causal graph where a bi-directed arrow indicates the pair of variables that have the same latent confounders, and a directed arrow indicates the causal direction of a pair of variables that are not affected by the same latent confounder. The results of experimental validation using simulated data and real-world data confirmed that RCD is effective in identifying latent confounders and causal directions between observed variables.
Analysis of Cause-Effect Inference via Regression Errors
Feb 19, 2018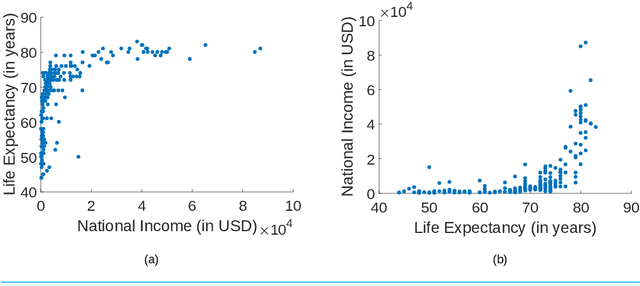

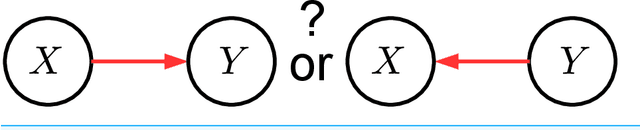
We address the problem of inferring the causal relation between two variables by comparing the least-squares errors of the predictions in both possible causal directions. Under the assumption of an independence between the function relating cause and effect, the conditional noise distribution, and the distribution of the cause, we show that the errors are smaller in causal direction if both variables are equally scaled and the causal relation is close to deterministic. Based on this, we provide an easily applicable algorithm that only requires a regression in both possible causal directions and a comparison of the errors. The performance of the algorithm is compared with different related causal inference methods in various artificial and real-world data sets.
Combining Linear Non-Gaussian Acyclic Model with Logistic Regression Model for Estimating Causal Structure from Mixed Continuous and Discrete Data
Feb 16, 2018
Estimating causal models from observational data is a crucial task in data analysis. For continuous-valued data, Shimizu et al. have proposed a linear acyclic non-Gaussian model to understand the data generating process, and have shown that their model is identifiable when the number of data is sufficiently large. However, situations in which continuous and discrete variables coexist in the same problem are common in practice. Most existing causal discovery methods either ignore the discrete data and apply a continuous-valued algorithm or discretize all the continuous data and then apply a discrete Bayesian network approach. These methods possibly loss important information when we ignore discrete data or introduce the approximation error due to discretization. In this paper, we define a novel hybrid causal model which consists of both continuous and discrete variables. The model assumes: (1) the value of a continuous variable is a linear function of its parent variables plus a non-Gaussian noise, and (2) each discrete variable is a logistic variable whose distribution parameters depend on the values of its parent variables. In addition, we derive the BIC scoring function for model selection. The new discovery algorithm can learn causal structures from mixed continuous and discrete data without discretization. We empirically demonstrate the power of our method through thorough simulations.
Estimation of interventional effects of features on prediction
Sep 03, 2017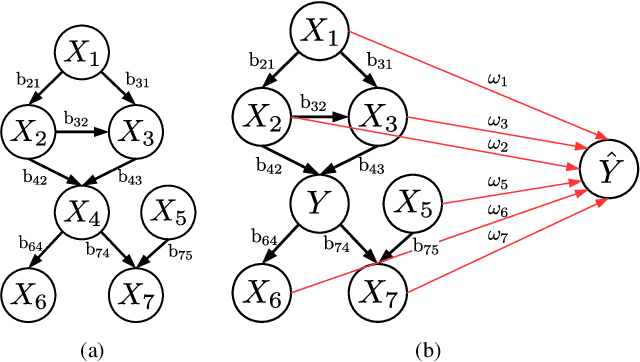
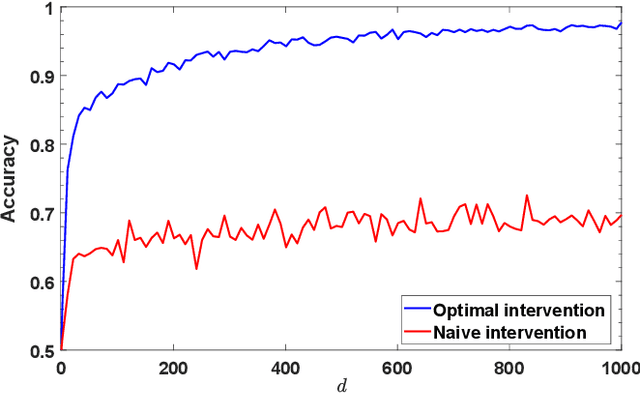
The interpretability of prediction mechanisms with respect to the underlying prediction problem is often unclear. While several studies have focused on developing prediction models with meaningful parameters, the causal relationships between the predictors and the actual prediction have not been considered. Here, we connect the underlying causal structure of a data generation process and the causal structure of a prediction mechanism. To achieve this, we propose a framework that identifies the feature with the greatest causal influence on the prediction and estimates the necessary causal intervention of a feature such that a desired prediction is obtained. The general concept of the framework has no restrictions regarding data linearity; however, we focus on an implementation for linear data here. The framework applicability is evaluated using artificial data and demonstrated using real-world data.
Error Asymmetry in Causal and Anticausal Regression
Apr 17, 2017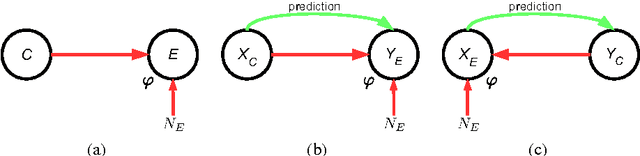
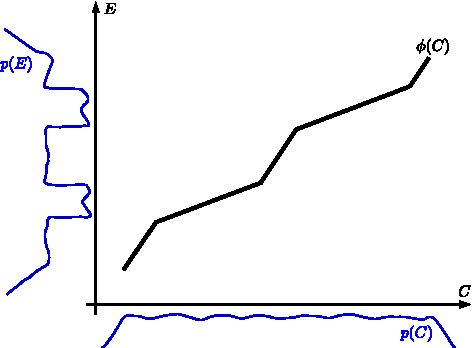
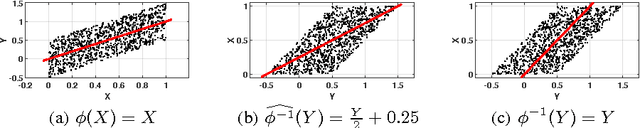
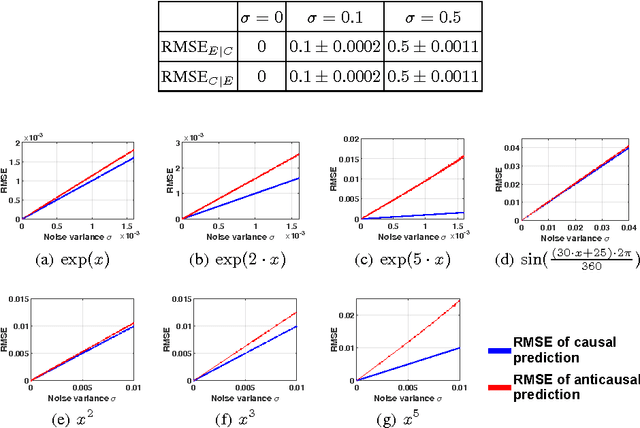
It is generally difficult to make any statements about the expected prediction error in an univariate setting without further knowledge about how the data were generated. Recent work showed that knowledge about the real underlying causal structure of a data generation process has implications for various machine learning settings. Assuming an additive noise and an independence between data generating mechanism and its input, we draw a novel connection between the intrinsic causal relationship of two variables and the expected prediction error. We formulate the theorem that the expected error of the true data generating function as prediction model is generally smaller when the effect is predicted from its cause and, on the contrary, greater when the cause is predicted from its effect. The theorem implies an asymmetry in the error depending on the prediction direction. This is further corroborated with empirical evaluations in artificial and real-world data sets.
Learning Instrumental Variables with Non-Gaussianity Assumptions: Theoretical Limitations and Practical Algorithms
Nov 09, 2015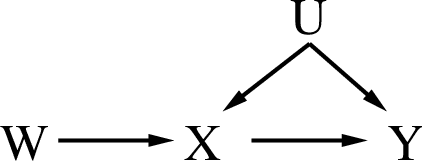
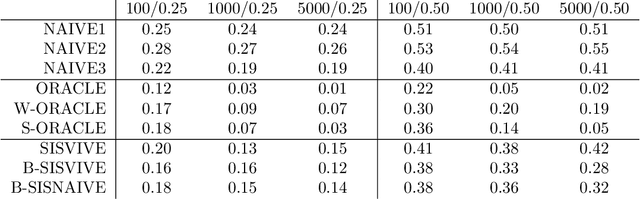

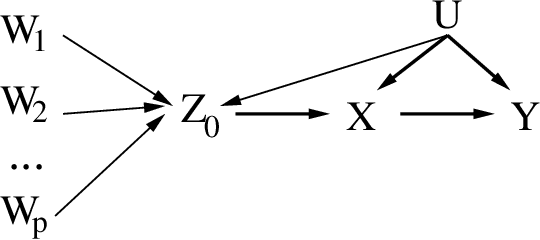
Learning a causal effect from observational data is not straightforward, as this is not possible without further assumptions. If hidden common causes between treatment $X$ and outcome $Y$ cannot be blocked by other measurements, one possibility is to use an instrumental variable. In principle, it is possible under some assumptions to discover whether a variable is structurally instrumental to a target causal effect $X \rightarrow Y$, but current frameworks are somewhat lacking on how general these assumptions can be. A instrumental variable discovery problem is challenging, as no variable can be tested as an instrument in isolation but only in groups, but different variables might require different conditions to be considered an instrument. Moreover, identification constraints might be hard to detect statistically. In this paper, we give a theoretical characterization of instrumental variable discovery, highlighting identifiability problems and solutions, the need for non-Gaussianity assumptions, and how they fit within existing methods.
A direct method for estimating a causal ordering in a linear non-Gaussian acyclic model
Aug 09, 2014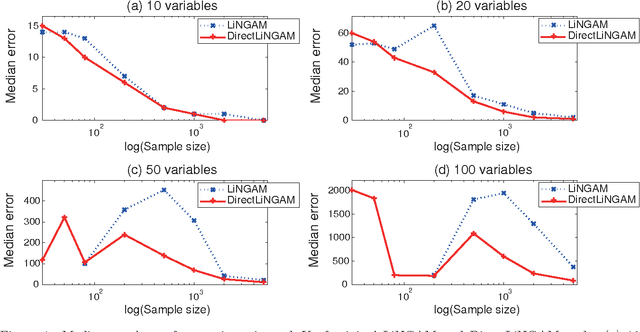
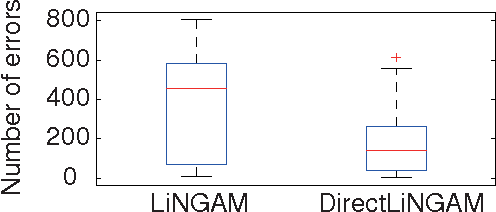
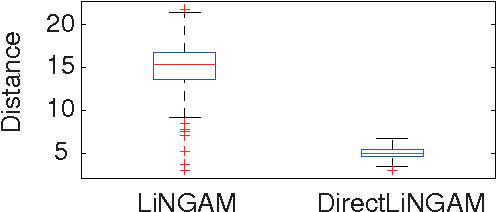
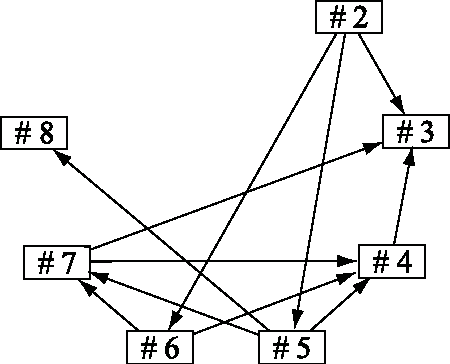
Structural equation models and Bayesian networks have been widely used to analyze causal relations between continuous variables. In such frameworks, linear acyclic models are typically used to model the datagenerating process of variables. Recently, it was shown that use of non-Gaussianity identifies a causal ordering of variables in a linear acyclic model without using any prior knowledge on the network structure, which is not the case with conventional methods. However, existing estimation methods are based on iterative search algorithms and may not converge to a correct solution in a finite number of steps. In this paper, we propose a new direct method to estimate a causal ordering based on non-Gaussianity. In contrast to the previous methods, our algorithm requires no algorithmic parameters and is guaranteed to converge to the right solution within a small fixed number of steps if the data strictly follows the model.
A Bayesian estimation approach to analyze non-Gaussian data-generating processes with latent classes
Aug 02, 2014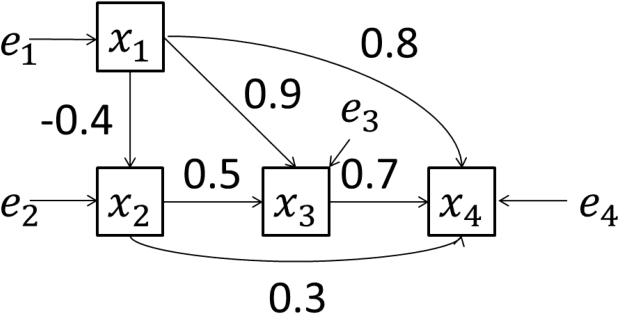
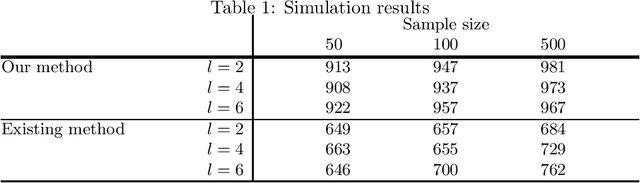
A large amount of observational data has been accumulated in various fields in recent times, and there is a growing need to estimate the generating processes of these data. A linear non-Gaussian acyclic model (LiNGAM) based on the non-Gaussianity of external influences has been proposed to estimate the data-generating processes of variables. However, the results of the estimation can be biased if there are latent classes. In this paper, we first review LiNGAM, its extended model, as well as the estimation procedure for LiNGAM in a Bayesian framework. We then propose a new Bayesian estimation procedure that solves the problem.