 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Hierarchical Clustering
Jan 16, 2013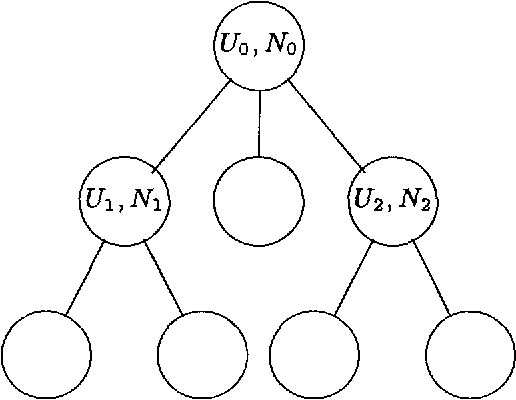
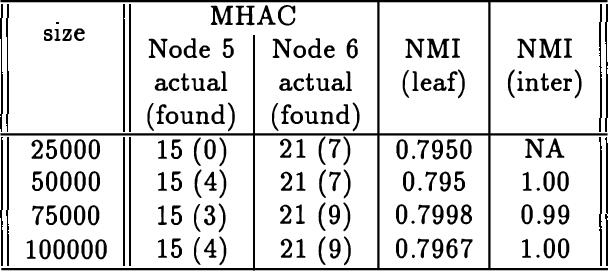
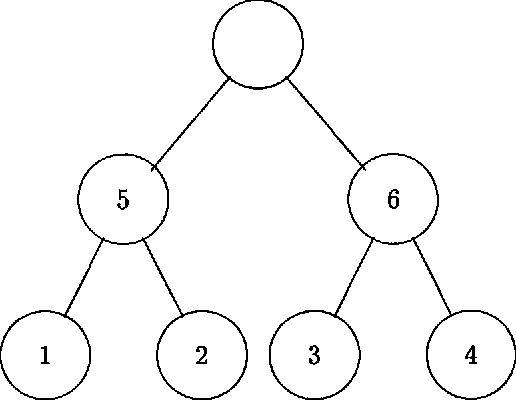
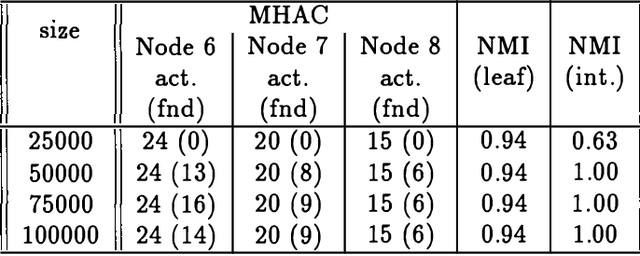
We present an approach to model-based hierarchical clustering by formulating an objective function based on a Bayesian analysis. This model organizes the data into a cluster hierarchy while specifying a complex feature-set partitioning that is a key component of our model. Features can have either a unique distribution in every cluster or a common distribution over some (or even all) of the clusters. The cluster subsets over which these features have such a common distribution correspond to the nodes (clusters) of the tree representing the hierarchy. We apply this general model to the problem of document clustering for which we use a multinomial likelihood function and Dirichlet priors. Our algorithm consists of a two-stage process wherein we first perform a flat clustering followed by a modified hierarchical agglomerative merging process that includes determining the features that will have common distributions over the merged clusters. The regularization induced by using the marginal likelihood automatically determines the optimal model structure including number of clusters, the depth of the tree and the subset of features to be modeled as having a common distribution at each node. We present experimental results on both synthetic data and a real document collection.
Thumbs up? Sentiment Classification using Machine Learning Techniques
May 28, 2002

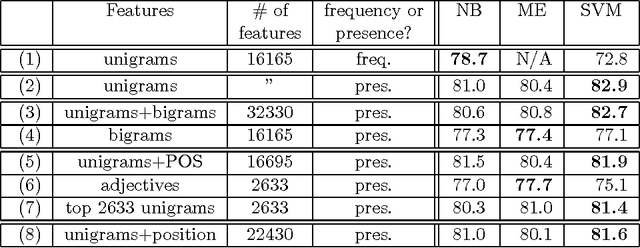
We consider the problem of classifying documents not by topic, but by overall sentiment, e.g., determining whether a review is positive or negative. Using movie reviews as data, we find that standard machine learning techniques definitively outperform human-produced baselines. However, the three machine learning methods we employed (Naive Bayes, maximum entropy classification, and support vector machines) do not perform as well on sentiment classification as on traditional topic-based categorization. We conclude by examining factors that make the sentiment classification problem more challenging.