 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Model Based Multi-Label Classification from the Crowd
Apr 04, 2016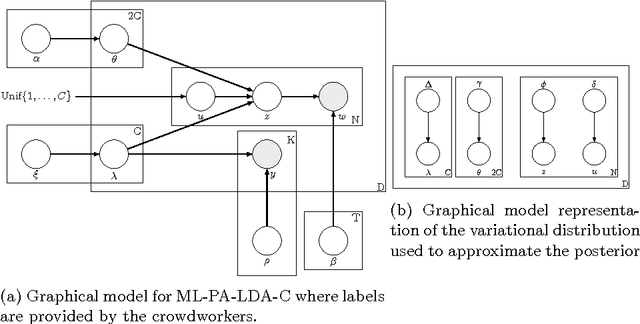
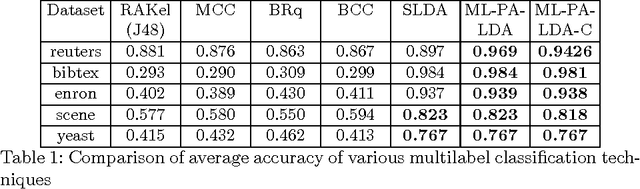
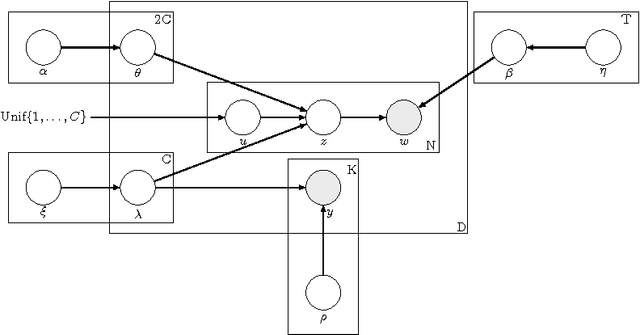
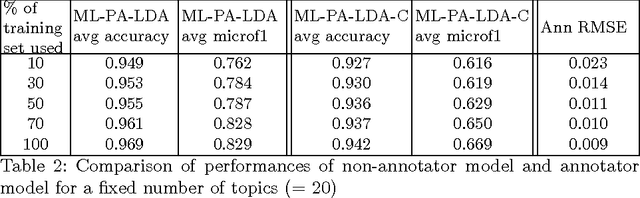
Multi-label classification is a common supervised machine learning problem where each instance is associated with multiple classes. The key challenge in this problem is learning the correlations between the classes. An additional challenge arises when the labels of the training instances are provided by noisy, heterogeneous crowdworkers with unknown qualities. We first assume labels from a perfect source and propose a novel topic model where the present as well as the absent classes generate the latent topics and hence the words. We non-trivially extend our topic model to the scenario where the labels are provided by noisy crowdworkers. Extensive experimentation on real world datasets reveals the superior performance of the proposed model. The proposed model learns the qualities of the annotators as well, even with minimal training data.
A Robust UCB Scheme for Active Learning in Regression from Strategic Crowds
Jan 29, 2016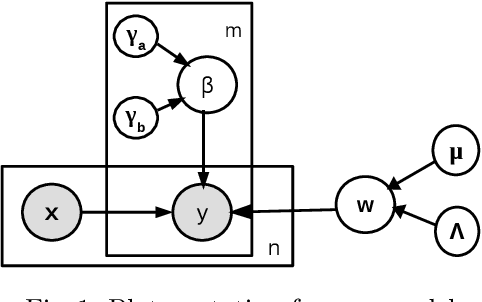
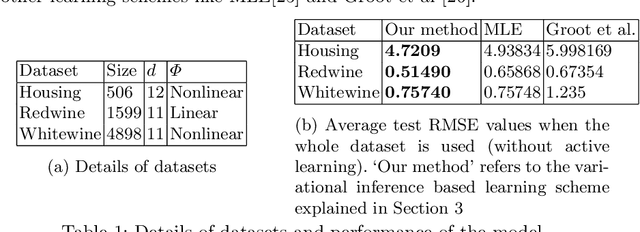
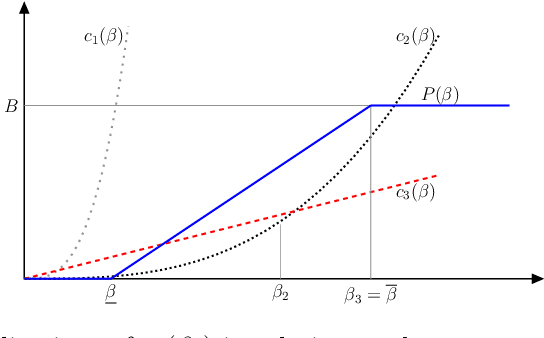
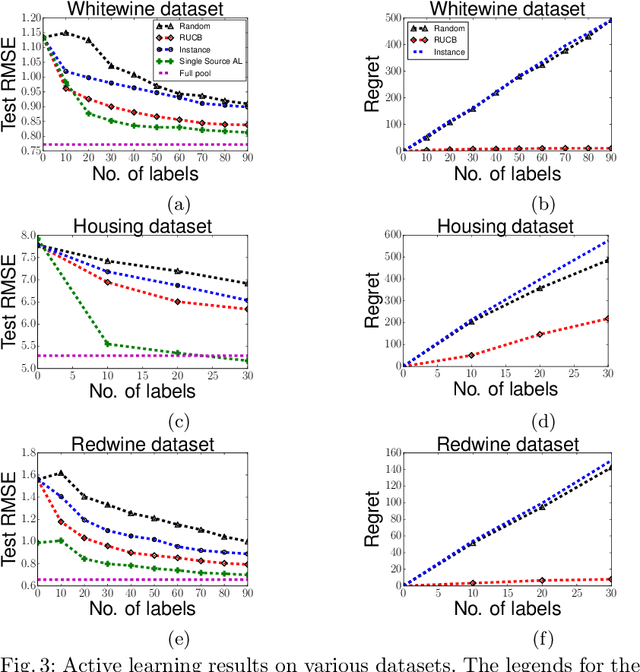
We study the problem of training an accurate linear regression model by procuring labels from multiple noisy crowd annotators, under a budget constraint. We propose a Bayesian model for linear regression in crowdsourcing and use variational inference for parameter estimation. To minimize the number of labels crowdsourced from the annotators, we adopt an active learning approach. In this specific context, we prove the equivalence of well-studied criteria of active learning like entropy minimization and expected error reduction. Interestingly, we observe that we can decouple the problems of identifying an optimal unlabeled instance and identifying an annotator to label it. We observe a useful connection between the multi-armed bandit framework and the annotator selection in active learning. Due to the nature of the distribution of the rewards on the arms, we use the Robust Upper Confidence Bound (UCB) scheme with truncated empirical mean estimator to solve the annotator selection problem. This yields provable guarantees on the regret. We further apply our model to the scenario where annotators are strategic and design suitable incentives to induce them to put in their best efforts.
An Empirical Evaluation of Sequence-Tagging Trainers
Nov 11, 2013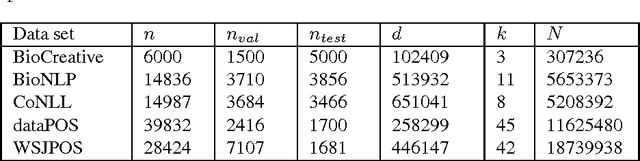
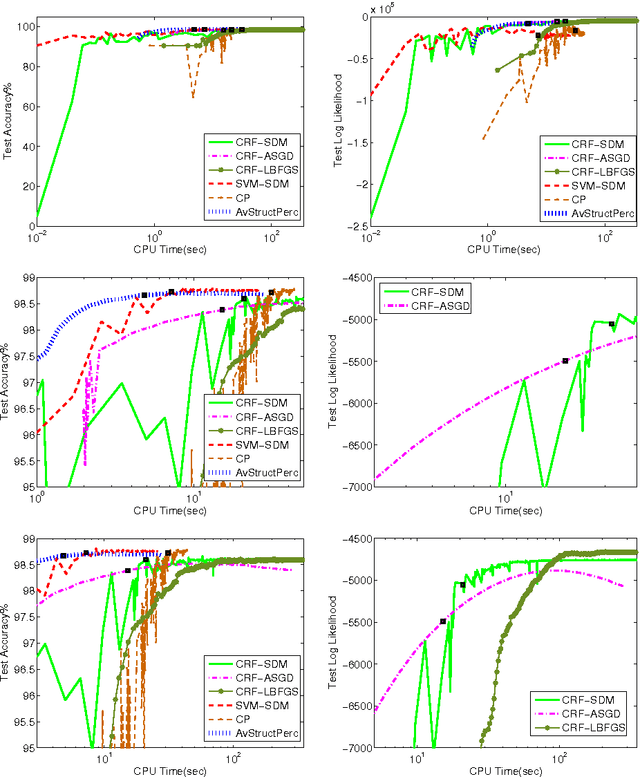
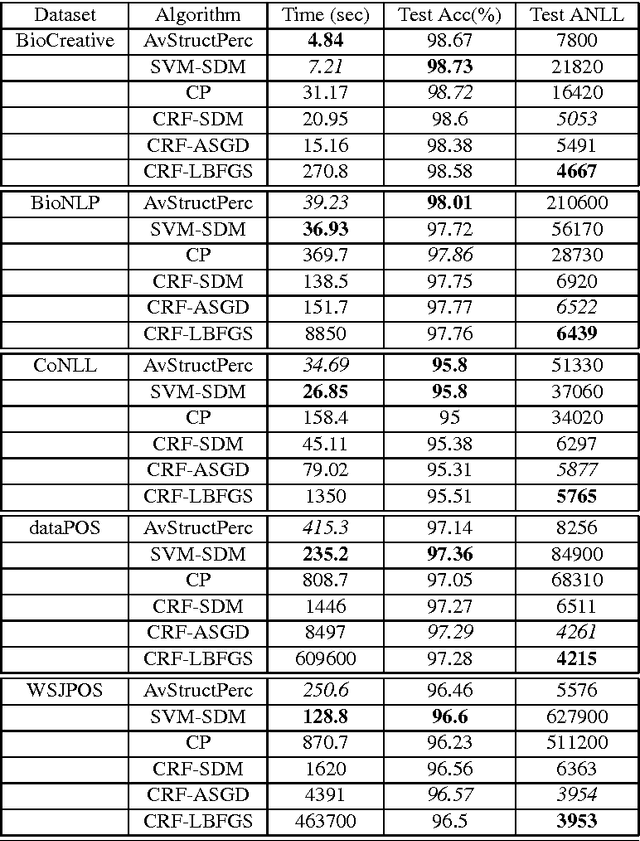
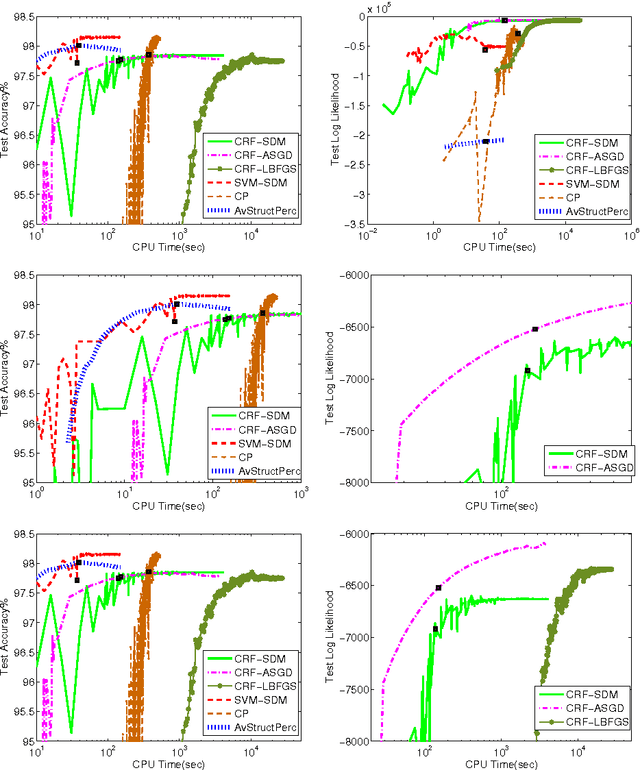
The task of assigning label sequences to a set of observed sequences is common in computational linguistics. Several models for sequence labeling have been proposed over the last few years. Here, we focus on discriminative models for sequence labeling. Many batch and online (updating model parameters after visiting each example) learning algorithms have been proposed in the literature. On large datasets, online algorithms are preferred as batch learning methods are slow. These online algorithms were designed to solve either a primal or a dual problem. However, there has been no systematic comparison of these algorithms in terms of their speed, generalization performance (accuracy/likelihood) and their ability to achieve steady state generalization performance fast. With this aim, we compare different algorithms and make recommendations, useful for a practitioner. We conclude that the selection of an algorithm for sequence labeling depends on the evaluation criterion used and its implementation simplicity.
Large Margin Semi-supervised Structured Output Learning
Nov 09, 2013
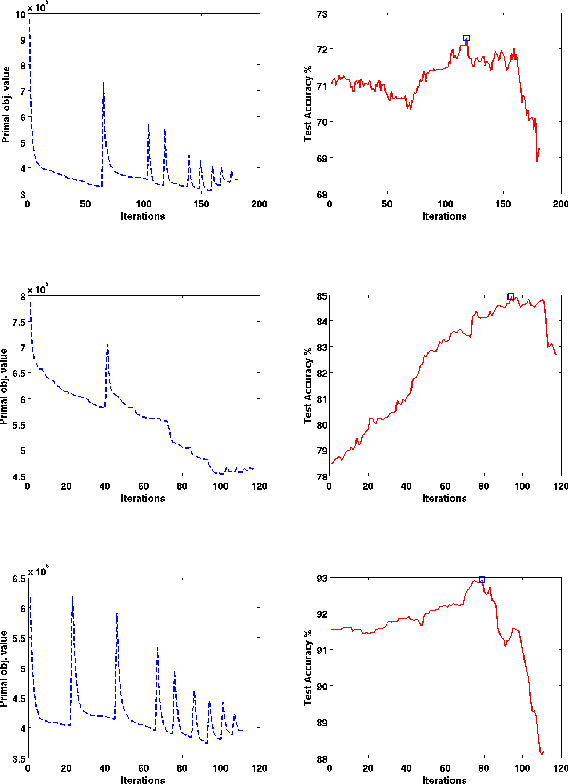

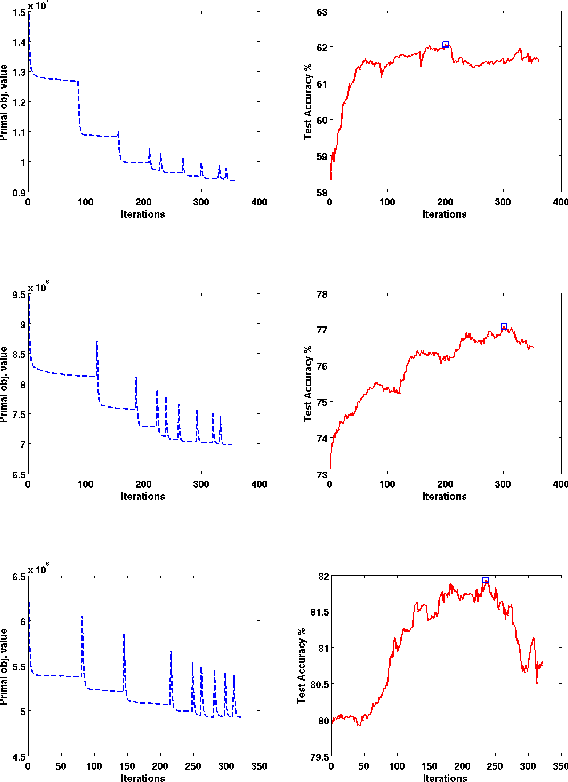
In structured output learning, obtaining labelled data for real-world applications is usually costly, while unlabelled examples are available in abundance. Semi-supervised structured classification has been developed to handle large amounts of unlabelled structured data. In this work, we consider semi-supervised structural SVMs with domain constraints. The optimization problem, which in general is not convex, contains the loss terms associated with the labelled and unlabelled examples along with the domain constraints. We propose a simple optimization approach, which alternates between solving a supervised learning problem and a constraint matching problem. Solving the constraint matching problem is difficult for structured prediction, and we propose an efficient and effective hill-climbing method to solve it. The alternating optimization is carried out within a deterministic annealing framework, which helps in effective constraint matching, and avoiding local minima which are not very useful. The algorithm is simple to implement and achieves comparable generalization performance on benchmark datasets.
Extension of TSVM to Multi-Class and Hierarchical Text Classification Problems With General Losses
Nov 01, 2012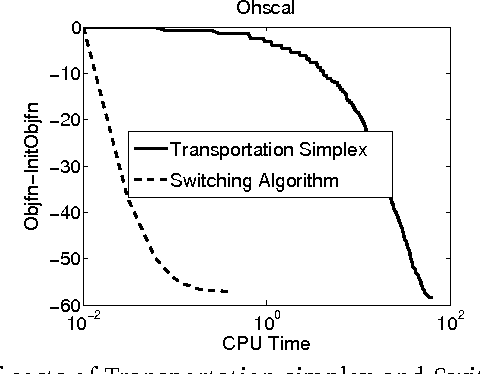

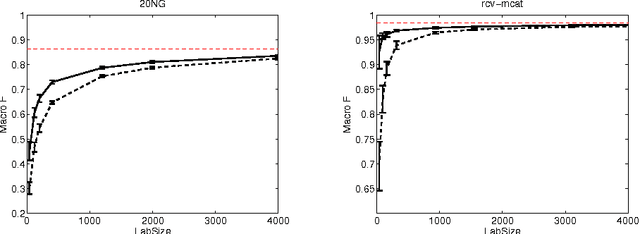
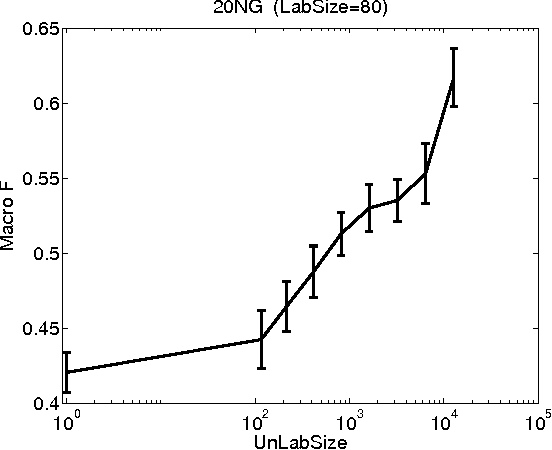
Transductive SVM (TSVM) is a well known semi-supervised large margin learning method for binary text classification. In this paper we extend this method to multi-class and hierarchical classification problems. We point out that the determination of labels of unlabeled examples with fixed classifier weights is a linear programming problem. We devise an efficient technique for solving it. The method is applicable to general loss functions. We demonstrate the value of the new method using large margin loss on a number of multi-class and hierarchical classification datasets. For maxent loss we show empirically that our method is better than expectation regularization/constraint and posterior regularization methods, and competitive with the version of entropy regularization method which uses label constraints.
Mechanism Design for Cost Optimal PAC Learning in the Presence of Strategic Noisy Annotators
Oct 16, 2012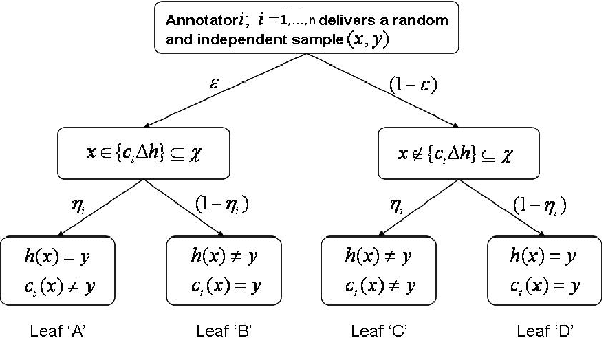
We consider the problem of Probably Approximate Correct (PAC) learning of a binary classifier from noisy labeled examples acquired from multiple annotators (each characterized by a respective classification noise rate). First, we consider the complete information scenario, where the learner knows the noise rates of all the annotators. For this scenario, we derive sample complexity bound for the Minimum Disagreement Algorithm (MDA) on the number of labeled examples to be obtained from each annotator. Next, we consider the incomplete information scenario, where each annotator is strategic and holds the respective noise rate as a private information. For this scenario, we design a cost optimal procurement auction mechanism along the lines of Myerson's optimal auction design framework in a non-trivial manner. This mechanism satisfies incentive compatibility property, thereby facilitating the learner to elicit true noise rates of all the annotators.
An Additive Model View to Sparse Gaussian Process Classifier Design
Jun 26, 2012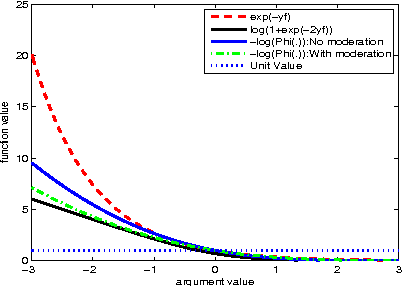
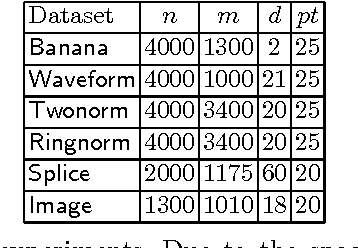
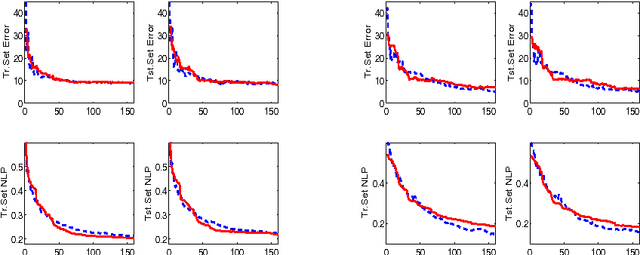
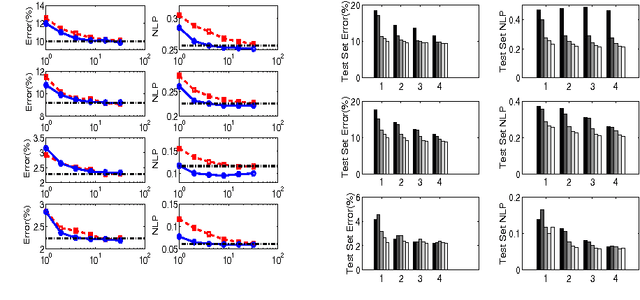
We consider the problem of designing a sparse Gaussian process classifier (SGPC) that generalizes well. Viewing SGPC design as constructing an additive model like in boosting, we present an efficient and effective SGPC design method to perform a stage-wise optimization of a predictive loss function. We introduce new methods for two key components viz., site parameter estimation and basis vector selection in any SGPC design. The proposed adaptive sampling based basis vector selection method aids in achieving improved generalization performance at a reduced computational cost. This method can also be used in conjunction with any other site parameter estimation methods. It has similar computational and storage complexities as the well-known information vector machine and is suitable for large datasets. The hyperparameters can be determined by optimizing a predictive loss function. The experimental results show better generalization performance of the proposed basis vector selection method on several benchmark datasets, particularly for relatively smaller basis vector set sizes or on difficult datasets.