 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Resolution Weak Supervision for Sequential Data
Oct 21, 2019
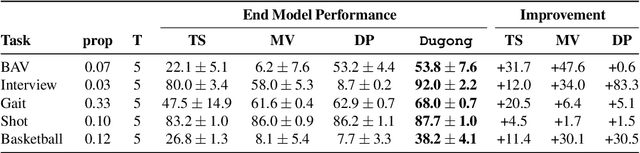
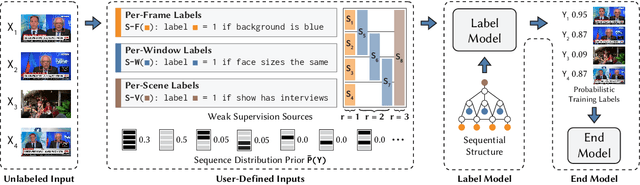

Since manually labeling training data is slow and expensive, recent industrial and scientific research efforts have turned to weaker or noisier forms of supervision sources. However, existing weak supervision approaches fail to model multi-resolution sources for sequential data, like video, that can assign labels to individual elements or collections of elements in a sequence. A key challenge in weak supervision is estimating the unknown accuracies and correlations of these sources without using labeled data. Multi-resolution sources exacerbate this challenge due to complex correlations and sample complexity that scales in the length of the sequence. We propose Dugong, the first framework to model multi-resolution weak supervision sources with complex correlations to assign probabilistic labels to training data. Theoretically, we prove that Dugong, under mild conditions, can uniquely recover the unobserved accuracy and correlation parameters and use parameter sharing to improve sample complexity. Our method assigns clinician-validated labels to population-scale biomedical video repositories, helping outperform traditional supervision by 36.8 F1 points and addressing a key use case where machine learning has been severely limited by the lack of expert labeled data. On average, Dugong improves over traditional supervision by 16.0 F1 points and existing weak supervision approaches by 24.2 F1 points across several video and sensor classification tasks.
Distributionally Robust Language Modeling
Sep 04, 2019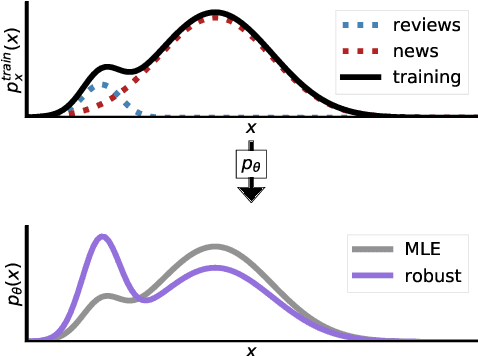

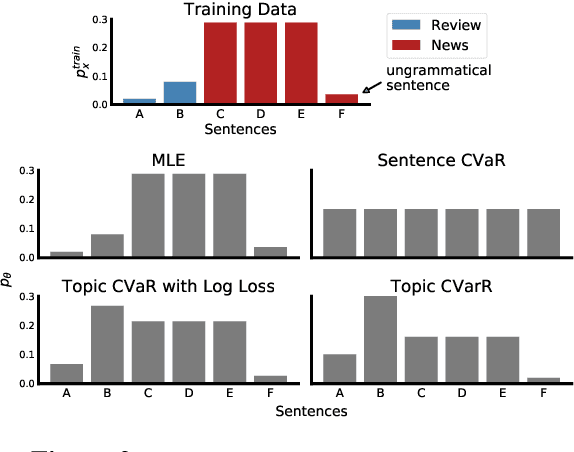
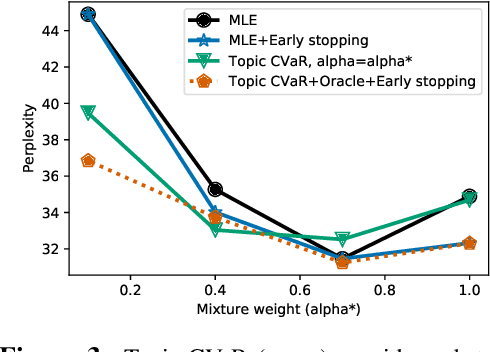
Language models are generally trained on data spanning a wide range of topics (e.g., news, reviews, fiction), but they might be applied to an a priori unknown target distribution (e.g., restaurant reviews). In this paper, we first show that training on text outside the test distribution can degrade test performance when using standard maximum likelihood (MLE) training. To remedy this without the knowledge of the test distribution, we propose an approach which trains a model that performs well over a wide range of potential test distributions. In particular, we derive a new distributionally robust optimization (DRO) procedure which minimizes the loss of the model over the worst-case mixture of topics with sufficient overlap with the training distribution. Our approach, called topic conditional value at risk (topic CVaR), obtains a 5.5 point perplexity reduction over MLE when the language models are trained on a mixture of Yelp reviews and news and tested only on reviews.