 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLaMo 2 Technical Report
Sep 05, 2025In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
Reconnaissance and Planning algorithm for constrained MDP
Sep 20, 2019
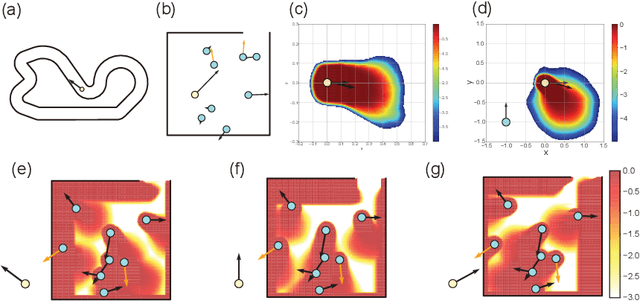

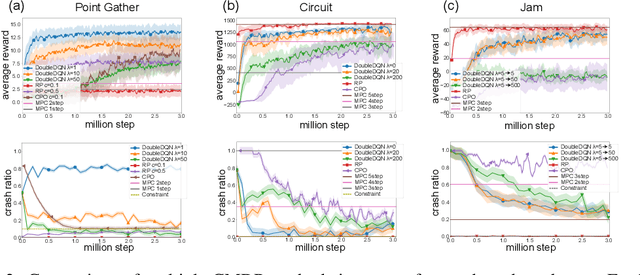
Practical reinforcement learning problems are often formulated as constrained Markov decision process (CMDP) problems, in which the agent has to maximize the expected return while satisfying a set of prescribed safety constraints. In this study, we propose a novel simulator-based method to approximately solve a CMDP problem without making any compromise on the safety constraints. We achieve this by decomposing the CMDP into a pair of MDPs; reconnaissance MDP and planning MDP. The purpose of reconnaissance MDP is to evaluate the set of actions that are safe, and the purpose of planning MDP is to maximize the return while using the actions authorized by reconnaissance MDP. RMDP can define a set of safe policies for any given set of safety constraint, and this set of safe policies can be used to solve another CMDP problem with different reward. Our method is not only computationally less demanding than the previous simulator-based approaches to CMDP, but also capable of finding a competitive reward-seeking policy in a high dimensional environment, including those involving multiple moving obstacles.