 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconfigurable Inverted Index
Aug 12, 2018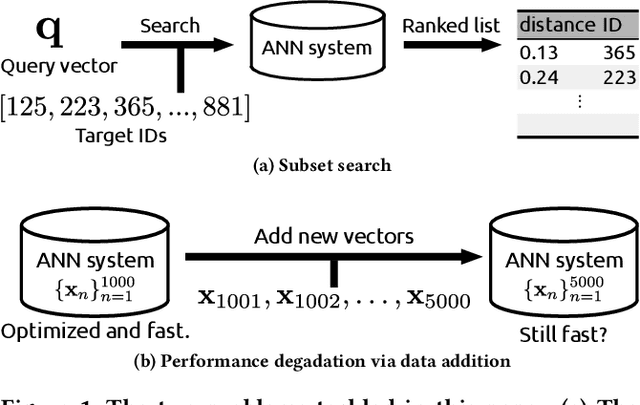

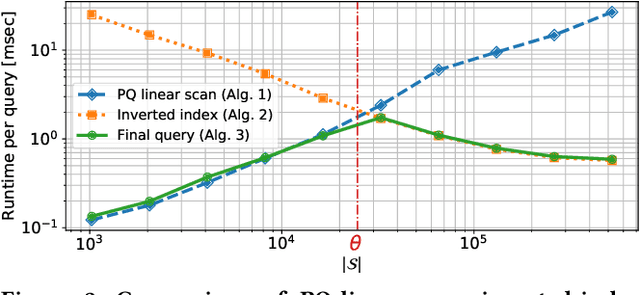
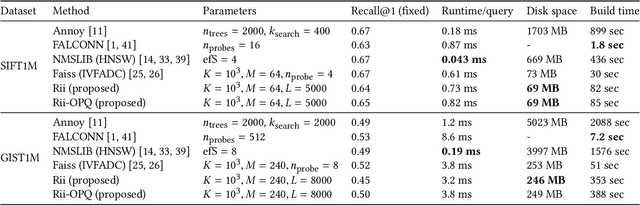
Existing approximate nearest neighbor search systems suffer from two fundamental problems that are of practical importance but have not received sufficient attention from the research community. First, although existing systems perform well for the whole database, it is difficult to run a search over a subset of the database. Second, there has been no discussion concerning the performance decrement after many items have been newly added to a system. We develop a reconfigurable inverted index (Rii) to resolve these two issues. Based on the standard IVFADC system, we design a data layout such that items are stored linearly. This enables us to efficiently run a subset search by switching the search method to a linear PQ scan if the size of a subset is small. Owing to the linear layout, the data structure can be dynamically adjusted after new items are added, maintaining the fast speed of the system. Extensive comparisons show that Rii achieves a comparable performance with state-of-the art systems such as Faiss.
Digital Watermarking for Deep Neural Networks
Feb 06, 2018
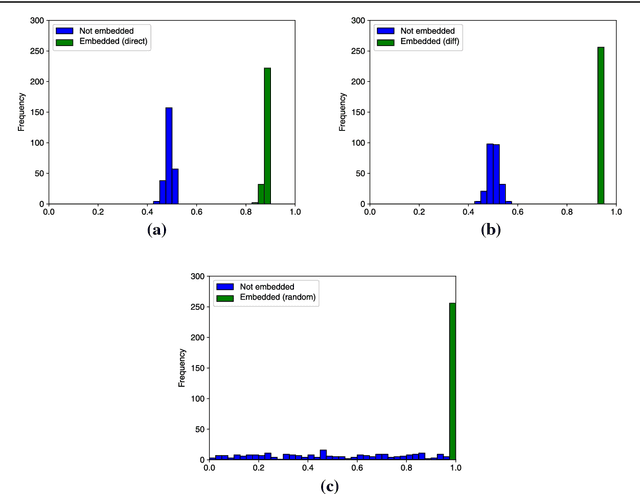

Although deep neural networks have made tremendous progress in the area of multimedia representation, training neural models requires a large amount of data and time. It is well-known that utilizing trained models as initial weights often achieves lower training error than neural networks that are not pre-trained. A fine-tuning step helps to reduce both the computational cost and improve performance. Therefore, sharing trained models has been very important for the rapid progress of research and development. In addition, trained models could be important assets for the owner(s) who trained them, hence we regard trained models as intellectual property. In this paper, we propose a digital watermarking technology for ownership authorization of deep neural networks. First, we formulate a new problem: embedding watermarks into deep neural networks. We also define requirements, embedding situations, and attack types on watermarking in deep neural networks. Second, we propose a general framework for embedding a watermark in model parameters, using a parameter regularizer. Our approach does not impair the performance of networks into which a watermark is placed because the watermark is embedded while training the host network. Finally, we perform comprehensive experiments to reveal the potential of watermarking deep neural networks as the basis of this new research effort. We show that our framework can embed a watermark during the training of a deep neural network from scratch, and during fine-tuning and distilling, without impairing its performance. The embedded watermark does not disappear even after fine-tuning or parameter pruning; the watermark remains complete even after 65% of parameters are pruned.
Consensus-based Sequence Training for Video Captioning
Dec 27, 2017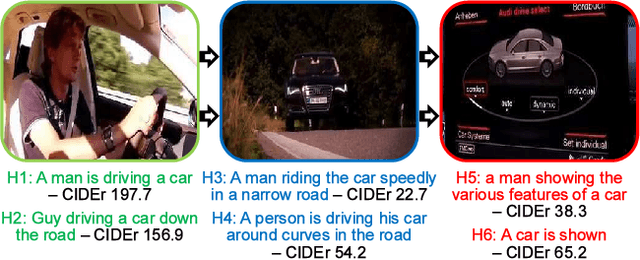
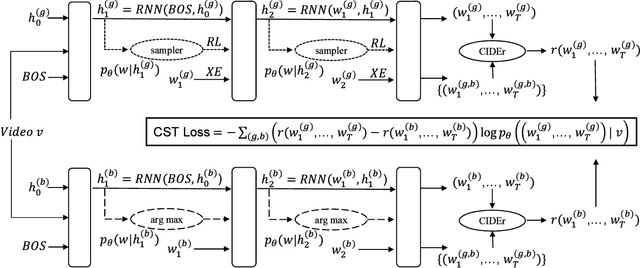
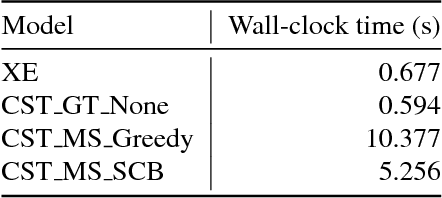
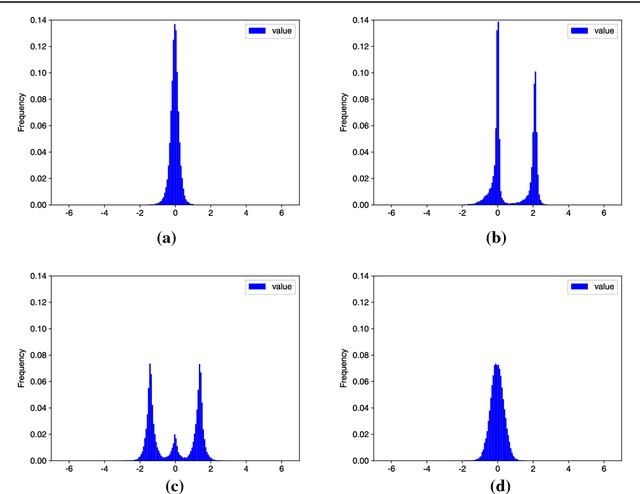
Captioning models are typically trained using the cross-entropy loss. However, their performance is evaluated on other metrics designed to better correlate with human assessments. Recently, it has been shown that reinforcement learning (RL) can directly optimize these metrics in tasks such as captioning. However, this is computationally costly and requires specifying a baseline reward at each step to make training converge. We propose a fast approach to optimize one's objective of interest through the REINFORCE algorithm. First we show that, by replacing model samples with ground-truth sentences, RL training can be seen as a form of weighted cross-entropy loss, giving a fast, RL-based pre-training algorithm. Second, we propose to use the consensus among ground-truth captions of the same video as the baseline reward. This can be computed very efficiently. We call the complete proposal Consensus-based Sequence Training (CST). Applied to the MSRVTT video captioning benchmark, our proposals train significantly faster than comparable methods and establish a new state-of-the-art on the task, improving the CIDEr score from 47.3 to 54.2.
Joint Detection and Recounting of Abnormal Events by Learning Deep Generic Knowledge
Sep 26, 2017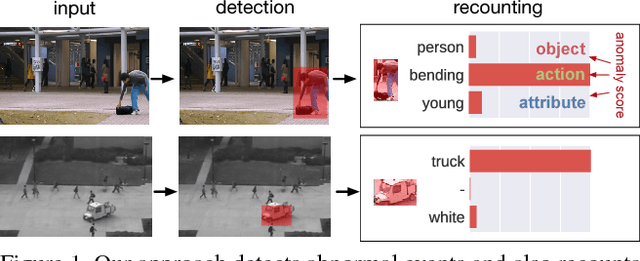
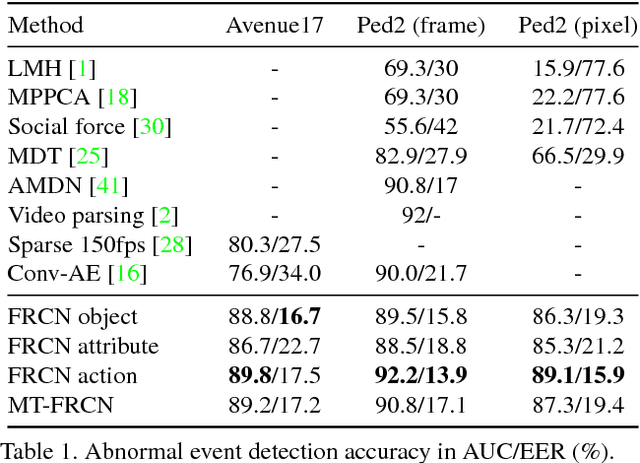
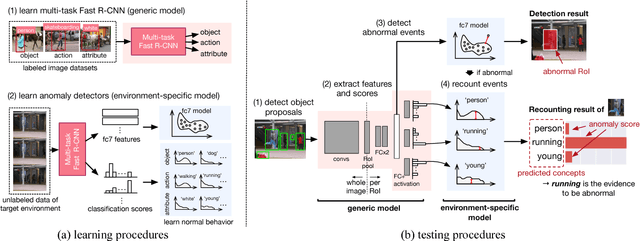
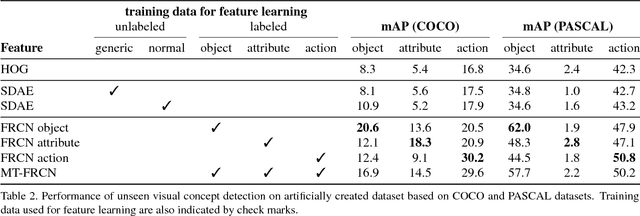
This paper addresses the problem of joint detection and recounting of abnormal events in videos. Recounting of abnormal events, i.e., explaining why they are judged to be abnormal, is an unexplored but critical task in video surveillance, because it helps human observers quickly judge if they are false alarms or not. To describe the events in the human-understandable form for event recounting, learning generic knowledge about visual concepts (e.g., object and action) is crucial. Although convolutional neural networks (CNNs) have achieved promising results in learning such concepts, it remains an open question as to how to effectively use CNNs for abnormal event detection, mainly due to the environment-dependent nature of the anomaly detection. In this paper, we tackle this problem by integrating a generic CNN model and environment-dependent anomaly detectors. Our approach first learns CNN with multiple visual tasks to exploit semantic information that is useful for detecting and recounting abnormal events. By appropriately plugging the model into anomaly detectors, we can detect and recount abnormal events while taking advantage of the discriminative power of CNNs. Our approach outperforms the state-of-the-art on Avenue and UCSD Ped2 benchmarks for abnormal event detection and also produces promising results of abnormal event recounting.
Region-Based Image Retrieval Revisited
Sep 26, 2017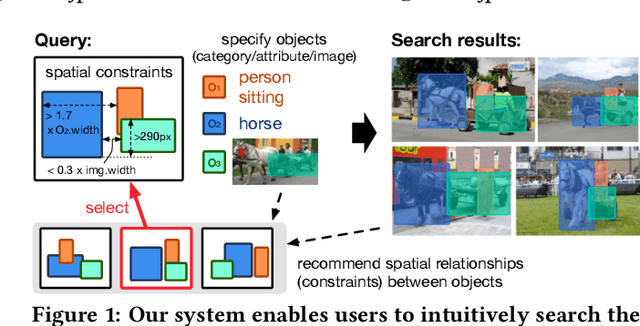
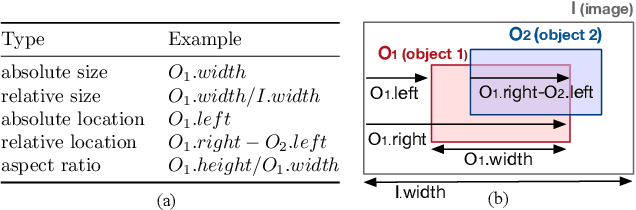
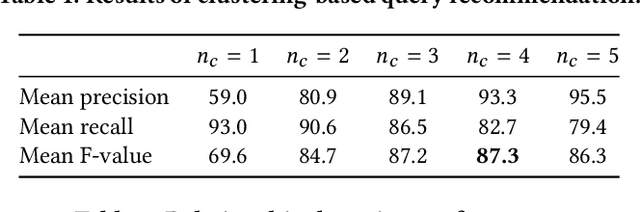
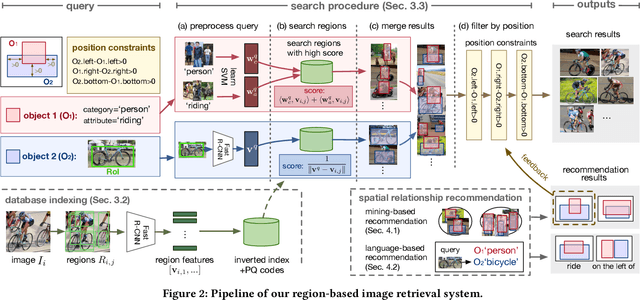
Region-based image retrieval (RBIR) technique is revisited. In early attempts at RBIR in the late 90s, researchers found many ways to specify region-based queries and spatial relationships; however, the way to characterize the regions, such as by using color histograms, were very poor at that time. Here, we revisit RBIR by incorporating semantic specification of objects and intuitive specification of spatial relationships. Our contributions are the following. First, to support multiple aspects of semantic object specification (category, instance, and attribute), we propose a multitask CNN feature that allows us to use deep learning technique and to jointly handle multi-aspect object specification. Second, to help users specify spatial relationships among objects in an intuitive way, we propose recommendation techniques of spatial relationships. In particular, by mining the search results, a system can recommend feasible spatial relationships among the objects. The system also can recommend likely spatial relationships by assigned object category names based on language prior. Moreover, object-level inverted indexing supports very fast shortlist generation, and re-ranking based on spatial constraints provides users with instant RBIR experiences.
Embedding Watermarks into Deep Neural Networks
Apr 20, 2017
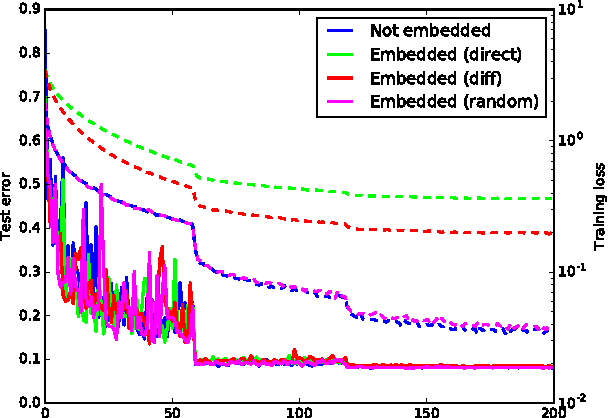
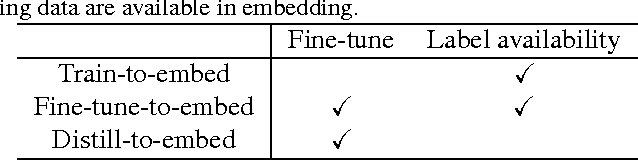
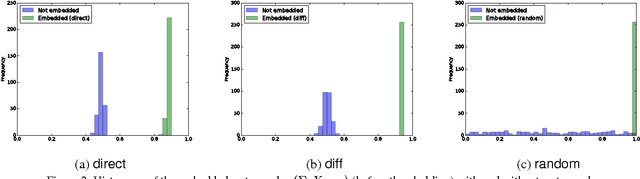
Deep neural networks have recently achieved significant progress. Sharing trained models of these deep neural networks is very important in the rapid progress of researching or developing deep neural network systems. At the same time, it is necessary to protect the rights of shared trained models. To this end, we propose to use a digital watermarking technology to protect intellectual property or detect intellectual property infringement of trained models. Firstly, we formulate a new problem: embedding watermarks into deep neural networks. We also define requirements, embedding situations, and attack types for watermarking to deep neural networks. Secondly, we propose a general framework to embed a watermark into model parameters using a parameter regularizer. Our approach does not hurt the performance of networks into which a watermark is embedded. Finally, we perform comprehensive experiments to reveal the potential of watermarking to deep neural networks as a basis of this new problem. We show that our framework can embed a watermark in the situations of training a network from scratch, fine-tuning, and distilling without hurting the performance of a deep neural network. The embedded watermark does not disappear even after fine-tuning or parameter pruning; the watermark completely remains even after removing 65% of parameters were pruned. The implementation of this research is: https://github.com/yu4u/dnn-watermark
Adaptive Substring Extraction and Modified Local NBNN Scoring for Binary Feature-based Local Mobile Visual Search without False Positives
Oct 20, 2016



In this paper, we propose a stand-alone mobile visual search system based on binary features and the bag-of-visual words framework. The contribution of this study is three-fold: (1) We propose an adaptive substring extraction method that adaptively extracts informative bits from the original binary vector and stores them in the inverted index. These substrings are used to refine visual word-based matching. (2) A modified local NBNN scoring method is proposed in the context of image retrieval, which considers the density of binary features in scoring each feature matching. (3) In order to suppress false positives, we introduce a convexity check step that imposes a convexity constraint on the configuration of a transformed reference image. The proposed system improves retrieval accuracy by 11% compared with a conventional method without increasing the database size. Furthermore, our system with the convexity check does not lead to false positive results.
Image Retrieval with Fisher Vectors of Binary Features
Sep 27, 2016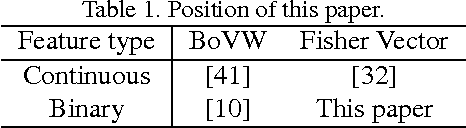

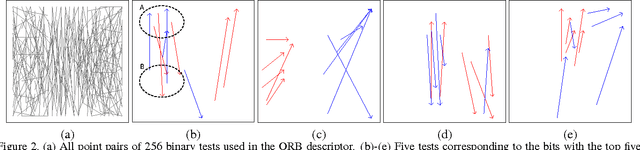
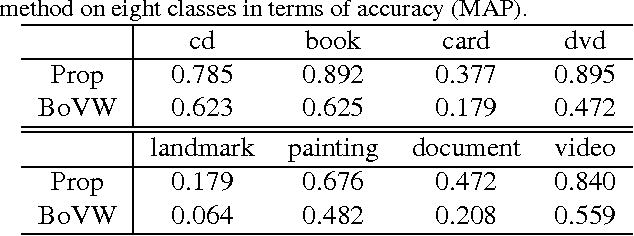
Recently, the Fisher vector representation of local features has attracted much attention because of its effectiveness in both image classification and image retrieval. Another trend in the area of image retrieval is the use of binary features such as ORB, FREAK, and BRISK. Considering the significant performance improvement for accuracy in both image classification and retrieval by the Fisher vector of continuous feature descriptors, if the Fisher vector were also to be applied to binary features, we would receive similar benefits in binary feature based image retrieval and classification. In this paper, we derive the closed-form approximation of the Fisher vector of binary features modeled by the Bernoulli mixture model. We also propose accelerating the Fisher vector by using the approximate value of posterior probability. Experiments show that the Fisher vector representation significantly improves the accuracy of image retrieval compared with a bag of binary words approach.
Faster R-CNN Features for Instance Search
Apr 29, 2016
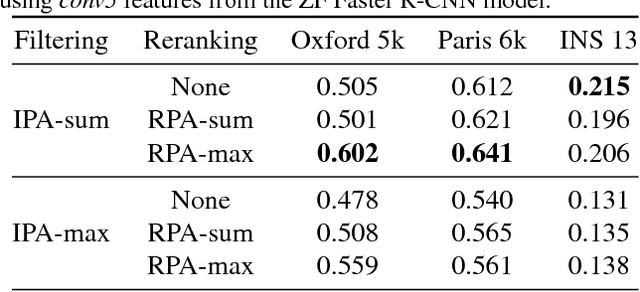
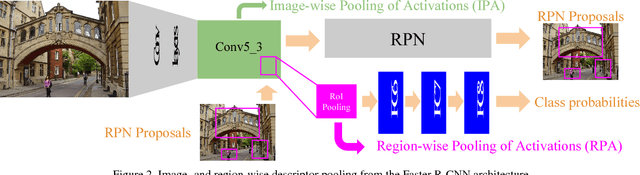
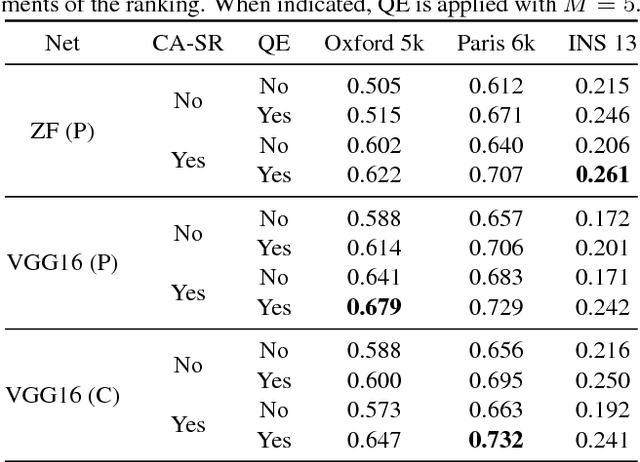
Image representations derived from pre-trained Convolutional Neural Networks (CNNs) have become the new state of the art in computer vision tasks such as instance retrieval. This work explores the suitability for instance retrieval of image- and region-wise representations pooled from an object detection CNN such as Faster R-CNN. We take advantage of the object proposals learned by a Region Proposal Network (RPN) and their associated CNN features to build an instance search pipeline composed of a first filtering stage followed by a spatial reranking. We further investigate the suitability of Faster R-CNN features when the network is fine-tuned for the same objects one wants to retrieve. We assess the performance of our proposed system with the Oxford Buildings 5k, Paris Buildings 6k and a subset of TRECVid Instance Search 2013, achieving competitive results.