 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Similarity Proportion Loss for Classifying Skeletal Muscle Recovery Stages
May 08, 2025



Evaluating the regeneration process of damaged muscle tissue is a fundamental analysis in muscle research to measure experimental effect sizes and uncover mechanisms behind muscle weakness due to aging and disease. The conventional approach to assessing muscle tissue regeneration involves whole-slide imaging and expert visual inspection of the recovery stages based on the morphological information of cells and fibers. There is a need to replace these tasks with automated methods incorporating machine learning techniques to ensure a quantitative and objective analysis. Given the limited availability of fully labeled data, a possible approach is Learning from Label Proportions (LLP), a weakly supervised learning method using class label proportions. However, current LLP methods have two limitations: (1) they cannot adapt the feature extractor for muscle tissues, and (2) they treat the classes representing recovery stages and cell morphological changes as nominal, resulting in the loss of ordinal information. To address these issues, we propose Ordinal Scale Learning from Similarity Proportion (OSLSP), which uses a similarity proportion loss derived from two bag combinations. OSLSP can update the feature extractor by using class proportion attention to the ordinal scale of the class. Our model with OSLSP outperforms large-scale pre-trained and fine-tuning models in classification tasks of skeletal muscle recovery stages.
Simulating reaction time for Eureka effect in visual object recognition using artificial neural network
Jun 30, 2022

The human brain can recognize objects hidden in even severely degraded images after observing them for a while, which is known as a type of Eureka effect, possibly associated with human creativity. A previous psychological study suggests that the basis of this "Eureka recognition" is neural processes of coincidence of multiple stochastic activities. Here we constructed an artificial-neural-network-based model that simulated the characteristics of the human Eureka recognition.
It's DONE: Direct ONE-shot learning without training optimization
Apr 28, 2022


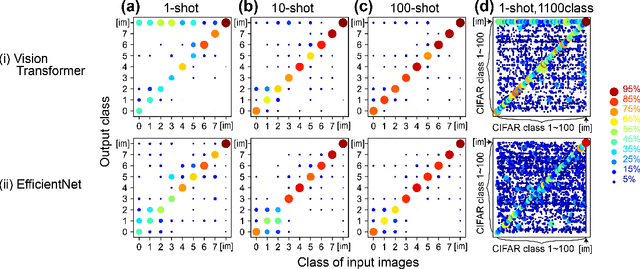
Learning a new concept from one example is a superior function of human brain and it is drawing attention in the field of machine learning as one-shot learning task. In this paper, we propose the simplest method for this task, named Direct ONE-shot learning (DONE). DONE adds a new class to a pretrained deep neural network (DNN) classifier with neither training optimization nor other-classes modification. DONE is inspired by Hebbian theory and directly uses the neural activity input of the final dense layer obtained from a data that belongs to the new additional class as the connectivity weight (synaptic strength) with a newly-provided-output neuron for the new class. DONE requires just one inference for obtaining the output of the final dense layer and its procedure is simple, deterministic, not requiring parameter tuning and hyperparameters. The performance of DONE depends entirely on the pretrained DNN model used as a backbone model, and we confirmed that DONE with a well-trained backbone model performs a practical-level accuracy. DONE has some advantages including a DNN's practical use that is difficult to spend high cost for a training, an evaluation of existing DNN models, and the understanding of the brain. DONE might be telling us one-shot learning is an easy task that can be achieved by a simple principle not only for humans but also for current well-trained DNN models.