 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoReSpec: A Framework for Generating Specification using Large Language Models
Apr 04, 2026Formal specification generation has recently drawn attention in software engineering as a way to improve program correctness without requiring manual annotations. Large Language Models (LLMs) have shown promise in this area, but early results reveal several limitations. Generated specifications often fail verification due to syntax errors, logical inaccuracies, or incomplete reasoning, especially in programs with loops or branching logic. Techniques like SpecGen and FormalBench attempt to address this through prompting and benchmarking, but they typically rely on static prompts and do not offer mechanisms for recovering from failure or adapting to different program structures. In this paper, we present AutoReSpec, a collaborative framework that combines open and closed-source LLMs for verifiable specification generation. AutoReSpec dynamically chooses an LLM pair and prompt configuration based on the structure of the input program. If the primary LLM fails to produce a valid output, a collaborative model is invoked, using validator feedback to refine and correct the specification. This two-stage design enables both speed and robustness. We evaluate AutoReSpec on a new benchmark of 72 real-world and synthetic Java programs. Our results show that it achieves 67 passes out of 72, outperforming SpecGen and FormalBench in both Success Probability and Completeness. Our experimental evaluation achieves a 58.2% success probability and a 69.2% completeness score, while cutting evaluation time by 26.89% on average compared to prior methods. Together, these results demonstrate that AutoReSpec offers a scalable, efficient, and reliable approach to LLM-based formal specification generation.
Trustworthy Medical Imaging with Large Language Models: A Study of Hallucinations Across Modalities
Aug 09, 2025



Large Language Models (LLMs) are increasingly applied to medical imaging tasks, including image interpretation and synthetic image generation. However, these models often produce hallucinations, which are confident but incorrect outputs that can mislead clinical decisions. This study examines hallucinations in two directions: image to text, where LLMs generate reports from X-ray, CT, or MRI scans, and text to image, where models create medical images from clinical prompts. We analyze errors such as factual inconsistencies and anatomical inaccuracies, evaluating outputs using expert informed criteria across imaging modalities. Our findings reveal common patterns of hallucination in both interpretive and generative tasks, with implications for clinical reliability. We also discuss factors contributing to these failures, including model architecture and training data. By systematically studying both image understanding and generation, this work provides insights into improving the safety and trustworthiness of LLM driven medical imaging systems.
Can Large Language Models Challenge CNNS in Medical Image Analysis?
May 29, 2025



This study presents a multimodal AI framework designed for precisely classifying medical diagnostic images. Utilizing publicly available datasets, the proposed system compares the strengths of convolutional neural networks (CNNs) and different large language models (LLMs). This in-depth comparative analysis highlights key differences in diagnostic performance, execution efficiency, and environmental impacts. Model evaluation was based on accuracy, F1-score, average execution time, average energy consumption, and estimated $CO_2$ emission. The findings indicate that although CNN-based models can outperform various multimodal techniques that incorporate both images and contextual information, applying additional filtering on top of LLMs can lead to substantial performance gains. These findings highlight the transformative potential of multimodal AI systems to enhance the reliability, efficiency, and scalability of medical diagnostics in clinical settings.
Hallucinations and Key Information Extraction in Medical Texts: A Comprehensive Assessment of Open-Source Large Language Models
Apr 27, 2025



Clinical summarization is crucial in healthcare as it distills complex medical data into digestible information, enhancing patient understanding and care management. Large language models (LLMs) have shown significant potential in automating and improving the accuracy of such summarizations due to their advanced natural language understanding capabilities. These models are particularly applicable in the context of summarizing medical/clinical texts, where precise and concise information transfer is essential. In this paper, we investigate the effectiveness of open-source LLMs in extracting key events from discharge reports, such as reasons for hospital admission, significant in-hospital events, and critical follow-up actions. In addition, we also assess the prevalence of various types of hallucinations in the summaries produced by these models. Detecting hallucinations is vital as it directly influences the reliability of the information, potentially affecting patient care and treatment outcomes. We conduct comprehensive numerical simulations to rigorously evaluate the performance of these models, further probing the accuracy and fidelity of the extracted content in clinical summarization.
Inferring Data Preconditions from Deep Learning Models for Trustworthy Prediction in Deployment
Jan 26, 2024



Deep learning models are trained with certain assumptions about the data during the development stage and then used for prediction in the deployment stage. It is important to reason about the trustworthiness of the model's predictions with unseen data during deployment. Existing methods for specifying and verifying traditional software are insufficient for this task, as they cannot handle the complexity of DNN model architecture and expected outcomes. In this work, we propose a novel technique that uses rules derived from neural network computations to infer data preconditions for a DNN model to determine the trustworthiness of its predictions. Our approach, DeepInfer involves introducing a novel abstraction for a trained DNN model that enables weakest precondition reasoning using Dijkstra's Predicate Transformer Semantics. By deriving rules over the inductive type of neural network abstract representation, we can overcome the matrix dimensionality issues that arise from the backward non-linear computation from the output layer to the input layer. We utilize the weakest precondition computation using rules of each kind of activation function to compute layer-wise precondition from the given postcondition on the final output of a deep neural network. We extensively evaluated DeepInfer on 29 real-world DNN models using four different datasets collected from five different sources and demonstrated the utility, effectiveness, and performance improvement over closely related work. DeepInfer efficiently detects correct and incorrect predictions of high-accuracy models with high recall (0.98) and high F-1 score (0.84) and has significantly improved over prior technique, SelfChecker. The average runtime overhead of DeepInfer is low, 0.22 sec for all unseen datasets. We also compared runtime overhead using the same hardware settings and found that DeepInfer is 3.27 times faster than SelfChecker.
What Kinds of Contracts Do ML APIs Need?
Jul 26, 2023Recent work has shown that Machine Learning (ML) programs are error-prone and called for contracts for ML code. Contracts, as in the design by contract methodology, help document APIs and aid API users in writing correct code. The question is: what kinds of contracts would provide the most help to API users? We are especially interested in what kinds of contracts help API users catch errors at earlier stages in the ML pipeline. We describe an empirical study of posts on Stack Overflow of the four most often-discussed ML libraries: TensorFlow, Scikit-learn, Keras, and PyTorch. For these libraries, our study extracted 413 informal (English) API specifications. We used these specifications to understand the following questions. What are the root causes and effects behind ML contract violations? Are there common patterns of ML contract violations? When does understanding ML contracts require an advanced level of ML software expertise? Could checking contracts at the API level help detect the violations in early ML pipeline stages? Our key findings are that the most commonly needed contracts for ML APIs are either checking constraints on single arguments of an API or on the order of API calls. The software engineering community could employ existing contract mining approaches to mine these contracts to promote an increased understanding of ML APIs. We also noted a need to combine behavioral and temporal contract mining approaches. We report on categories of required ML contracts, which may help designers of contract languages.
Identifying Classes Susceptible to Adversarial Attacks
May 30, 2019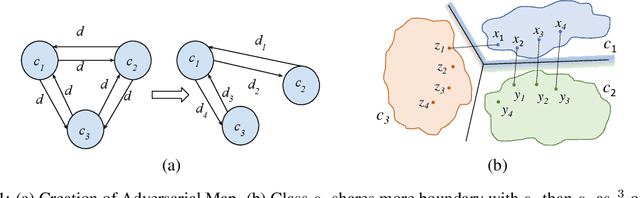

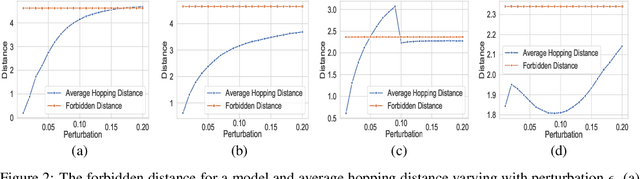
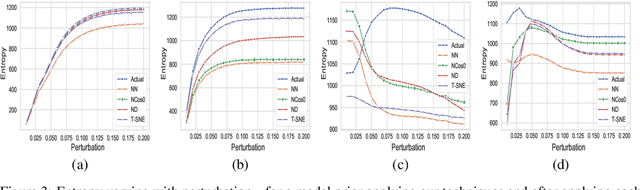
Despite numerous attempts to defend deep learning based image classifiers, they remain susceptible to the adversarial attacks. This paper proposes a technique to identify susceptible classes, those classes that are more easily subverted. To identify the susceptible classes we use distance-based measures and apply them on a trained model. Based on the distance among original classes, we create mapping among original classes and adversarial classes that helps to reduce the randomness of a model to a significant amount in an adversarial setting. We analyze the high dimensional geometry among the feature classes and identify the k most susceptible target classes in an adversarial attack. We conduct experiments using MNIST, Fashion MNIST, CIFAR-10 (ImageNet and ResNet-32) datasets. Finally, we evaluate our techniques in order to determine which distance-based measure works best and how the randomness of a model changes with perturbation.