 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Neural Generators for Dialogue Learn Sentence Planning and Discourse Structuring?
Nov 01, 2018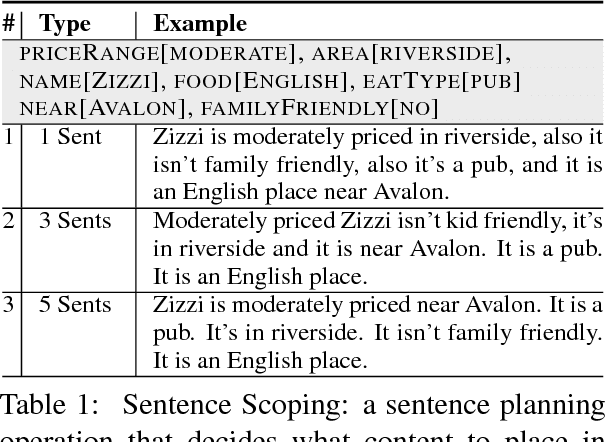
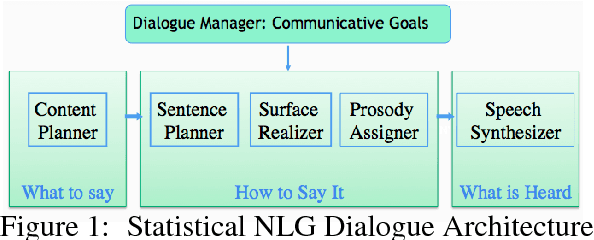


Responses in task-oriented dialogue systems often realize multiple propositions whose ultimate form depends on the use of sentence planning and discourse structuring operations. For example a recommendation may consist of an explicitly evaluative utterance e.g. Chanpen Thai is the best option, along with content related by the justification discourse relation, e.g. It has great food and service, that combines multiple propositions into a single phrase. While neural generation methods integrate sentence planning and surface realization in one end-to-end learning framework, previous work has not shown that neural generators can: (1) perform common sentence planning and discourse structuring operations; (2) make decisions as to whether to realize content in a single sentence or over multiple sentences; (3) generalize sentence planning and discourse relation operations beyond what was seen in training. We systematically create large training corpora that exhibit particular sentence planning operations and then test neural models to see what they learn. We compare models without explicit latent variables for sentence planning with ones that provide explicit supervision during training. We show that only the models with additional supervision can reproduce sentence planing and discourse operations and generalize to situations unseen in training.
Neural MultiVoice Models for Expressing Novel Personalities in Dialog
Sep 05, 2018
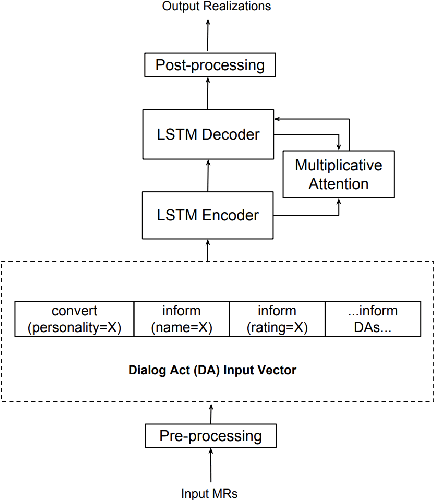

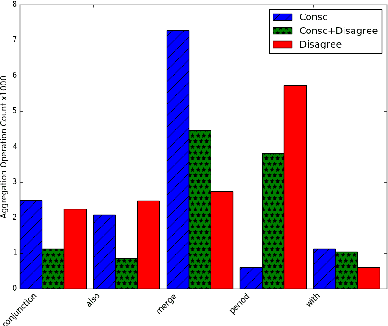
Natural language generators for task-oriented dialog should be able to vary the style of the output utterance while still effectively realizing the system dialog actions and their associated semantics. While the use of neural generation for training the response generation component of conversational agents promises to simplify the process of producing high quality responses in new domains, to our knowledge, there has been very little investigation of neural generators for task-oriented dialog that can vary their response style, and we know of no experiments on models that can generate responses that are different in style from those seen during training, while still maintain- ing semantic fidelity to the input meaning representation. Here, we show that a model that is trained to achieve a single stylis- tic personality target can produce outputs that combine stylistic targets. We carefully evaluate the multivoice outputs for both semantic fidelity and for similarities to and differences from the linguistic features that characterize the original training style. We show that contrary to our predictions, the learned models do not always simply interpolate model parameters, but rather produce styles that are distinct, and novel from the personalities they were trained on.
Controlling Personality-Based Stylistic Variation with Neural Natural Language Generators
May 22, 2018
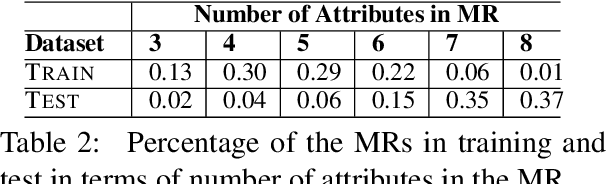

Natural language generators for task-oriented dialogue must effectively realize system dialogue actions and their associated semantics. In many applications, it is also desirable for generators to control the style of an utterance. To date, work on task-oriented neural generation has primarily focused on semantic fidelity rather than achieving stylistic goals, while work on style has been done in contexts where it is difficult to measure content preservation. Here we present three different sequence-to-sequence models and carefully test how well they disentangle content and style. We use a statistical generator, Personage, to synthesize a new corpus of over 88,000 restaurant domain utterances whose style varies according to models of personality, giving us total control over both the semantic content and the stylistic variation in the training data. We then vary the amount of explicit stylistic supervision given to the three models. We show that our most explicit model can simultaneously achieve high fidelity to both semantic and stylistic goals: this model adds a context vector of 36 stylistic parameters as input to the hidden state of the encoder at each time step, showing the benefits of explicit stylistic supervision, even when the amount of training data is large.
SlugNERDS: A Named Entity Recognition Tool for Open Domain Dialogue Systems
May 10, 2018
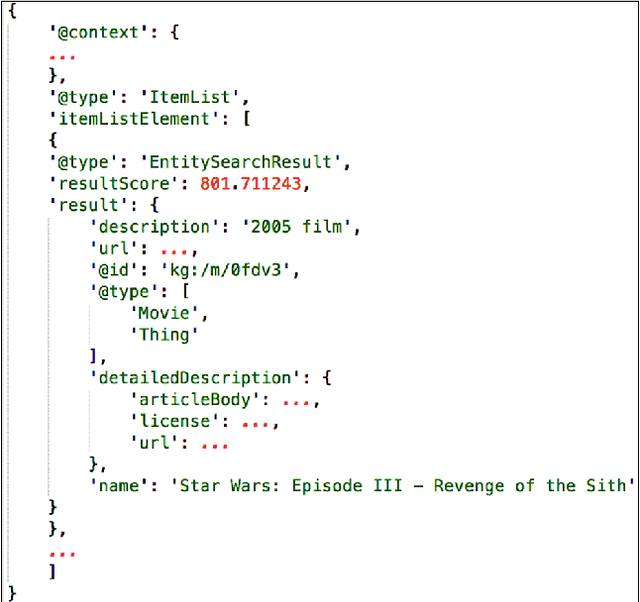
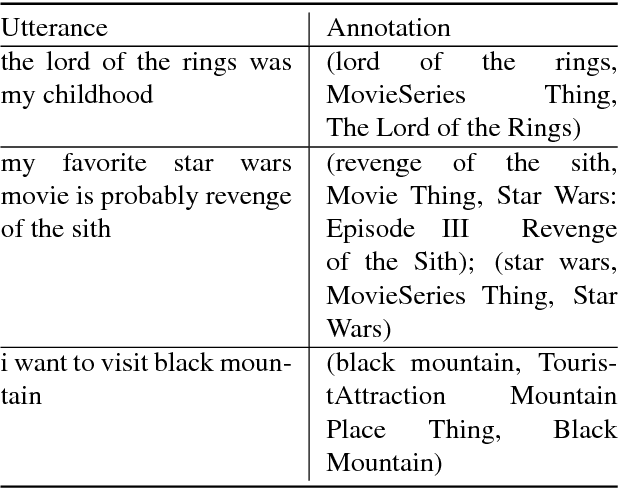
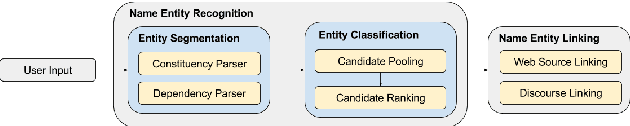
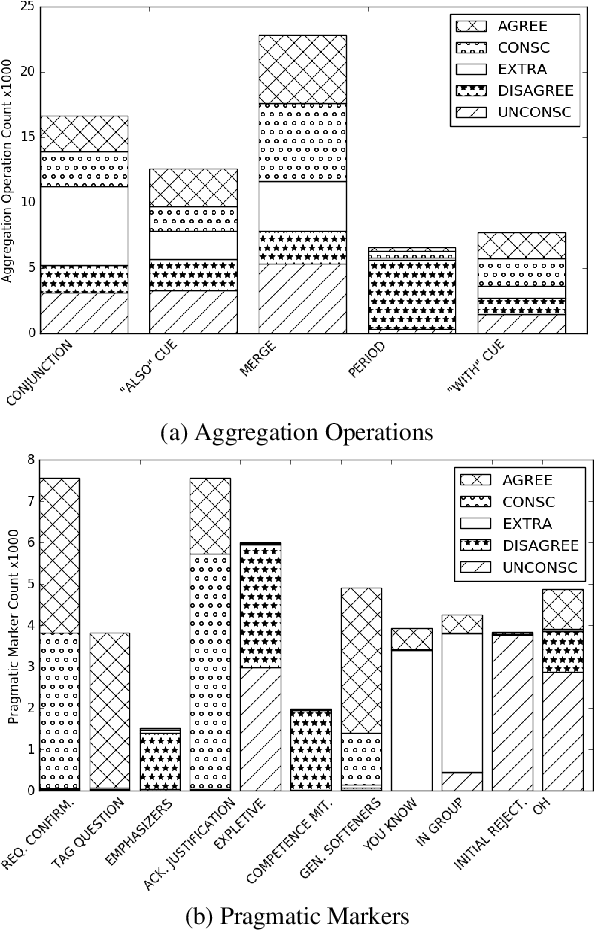
In dialogue systems, the tasks of named entity recognition (NER) and named entity linking (NEL) are vital preprocessing steps for understanding user intent, especially in open domain interaction where we cannot rely on domain-specific inference. UCSC's effort as one of the funded teams in the 2017 Amazon Alexa Prize Contest has yielded Slugbot, an open domain social bot, aimed at casual conversation. We discovered several challenges specifically associated with both NER and NEL when building Slugbot, such as that the NE labels are too coarse-grained or the entity types are not linked to a useful ontology. Moreover, we have discovered that traditional approaches do not perform well in our context: even systems designed to operate on tweets or other social media data do not work well in dialogue systems. In this paper, we introduce Slugbot's Named Entity Recognition for dialogue Systems (SlugNERDS), a NER and NEL tool which is optimized to address these issues. We describe two new resources that we are building as part of this work: SlugEntityDB and SchemaActuator. We believe these resources will be useful for the research community.
* Resources can be found: https://nlds.soe.ucsc.edu/node/56
Exploring Conversational Language Generation for Rich Content about Hotels
May 01, 2018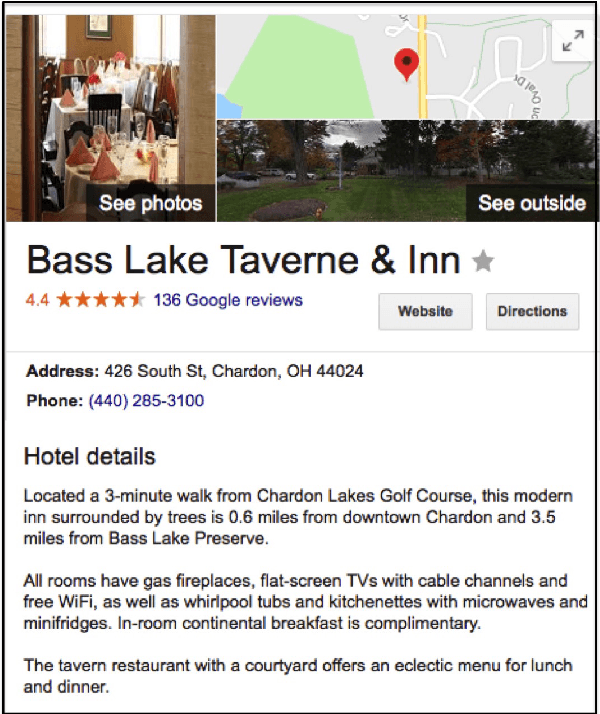
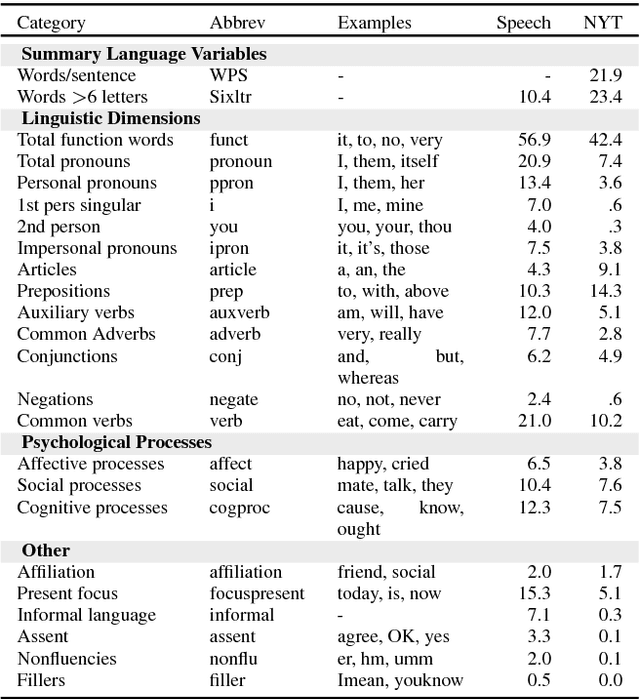

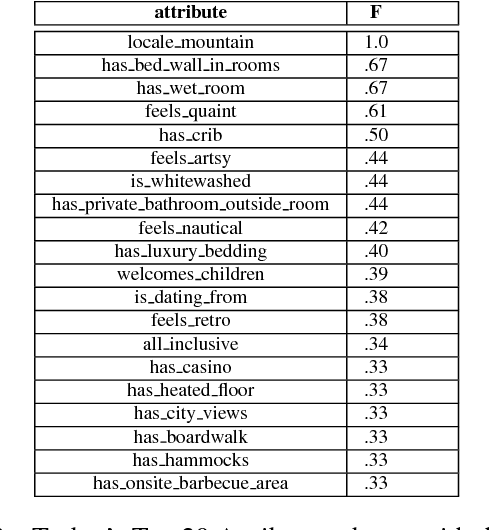
Dialogue systems for hotel and tourist information have typically simplified the richness of the domain, focusing system utterances on only a few selected attributes such as price, location and type of rooms. However, much more content is typically available for hotels, often as many as 50 distinct instantiated attributes for an individual entity. New methods are needed to use this content to generate natural dialogues for hotel information, and in general for any domain with such rich complex content. We describe three experiments aimed at collecting data that can inform an NLG for hotels dialogues, and show, not surprisingly, that the sentences in the original written hotel descriptions provided on webpages for each hotel are stylistically not a very good match for conversational interaction. We quantify the stylistic features that characterize the differences between the original textual data and the collected dialogic data. We plan to use these in stylistic models for generation, and for scoring retrieved utterances for use in hotel dialogues
Slugbot: An Application of a Novel and Scalable Open Domain Socialbot Framework
Jan 04, 2018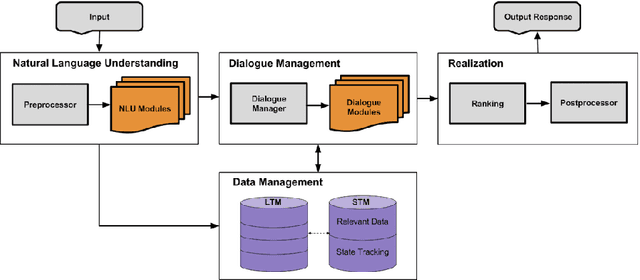
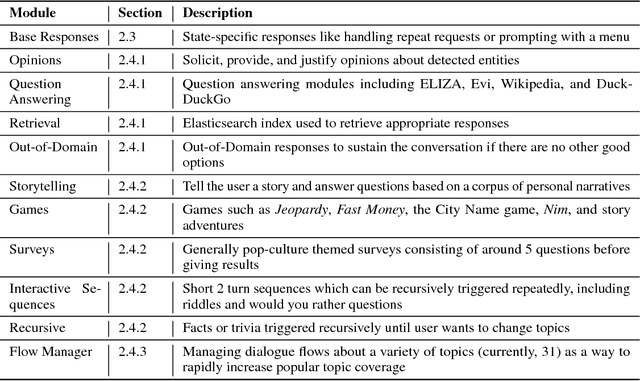


In this paper we introduce a novel, open domain socialbot for the Amazon Alexa Prize competition, aimed at carrying on friendly conversations with users on a variety of topics. We present our modular system, highlighting our different data sources and how we use the human mind as a model for data management. Additionally we build and employ natural language understanding and information retrieval tools and APIs to expand our knowledge bases. We describe our semistructured, scalable framework for crafting topic-specific dialogue flows, and give details on our dialogue management schemes and scoring mechanisms. Finally we briefly evaluate the performance of our system and observe the challenges that an open domain socialbot faces.
Summarizing Dialogic Arguments from Social Media
Oct 31, 2017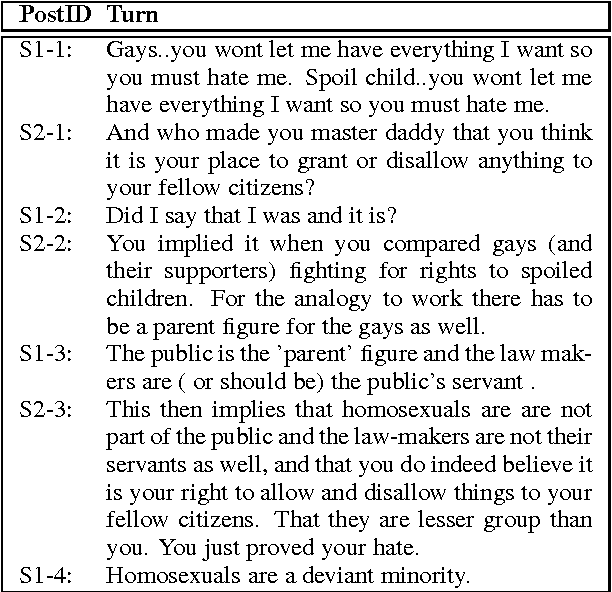
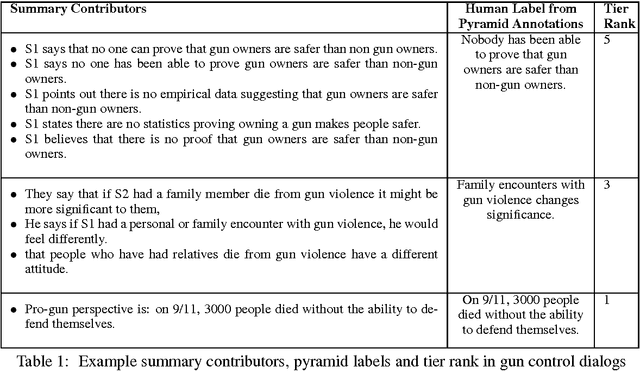

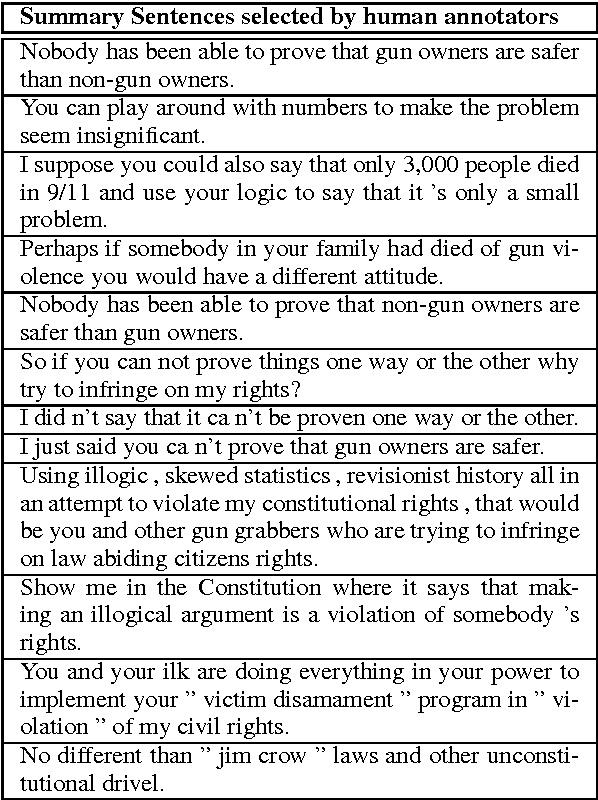
Online argumentative dialog is a rich source of information on popular beliefs and opinions that could be useful to companies as well as governmental or public policy agencies. Compact, easy to read, summaries of these dialogues would thus be highly valuable. A priori, it is not even clear what form such a summary should take. Previous work on summarization has primarily focused on summarizing written texts, where the notion of an abstract of the text is well defined. We collect gold standard training data consisting of five human summaries for each of 161 dialogues on the topics of Gay Marriage, Gun Control and Abortion. We present several different computational models aimed at identifying segments of the dialogues whose content should be used for the summary, using linguistic features and Word2vec features with both SVMs and Bidirectional LSTMs. We show that we can identify the most important arguments by using the dialog context with a best F-measure of 0.74 for gun control, 0.71 for gay marriage, and 0.67 for abortion.
"How May I Help You?": Modeling Twitter Customer Service Conversations Using Fine-Grained Dialogue Acts
Sep 15, 2017
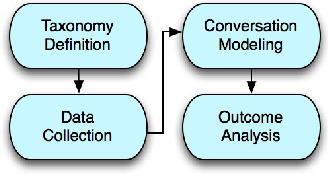
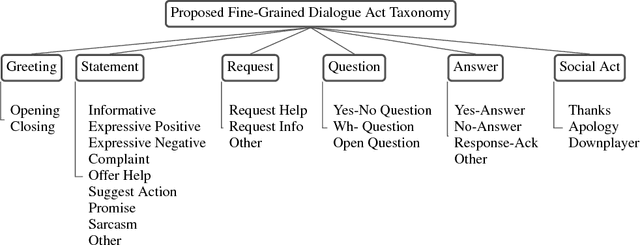
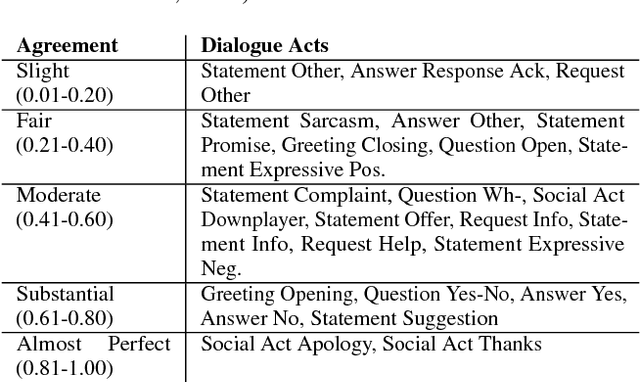
Given the increasing popularity of customer service dialogue on Twitter, analysis of conversation data is essential to understand trends in customer and agent behavior for the purpose of automating customer service interactions. In this work, we develop a novel taxonomy of fine-grained "dialogue acts" frequently observed in customer service, showcasing acts that are more suited to the domain than the more generic existing taxonomies. Using a sequential SVM-HMM model, we model conversation flow, predicting the dialogue act of a given turn in real-time. We characterize differences between customer and agent behavior in Twitter customer service conversations, and investigate the effect of testing our system on different customer service industries. Finally, we use a data-driven approach to predict important conversation outcomes: customer satisfaction, customer frustration, and overall problem resolution. We show that the type and location of certain dialogue acts in a conversation have a significant effect on the probability of desirable and undesirable outcomes, and present actionable rules based on our findings. The patterns and rules we derive can be used as guidelines for outcome-driven automated customer service platforms.
Combining Search with Structured Data to Create a More Engaging User Experience in Open Domain Dialogue
Sep 15, 2017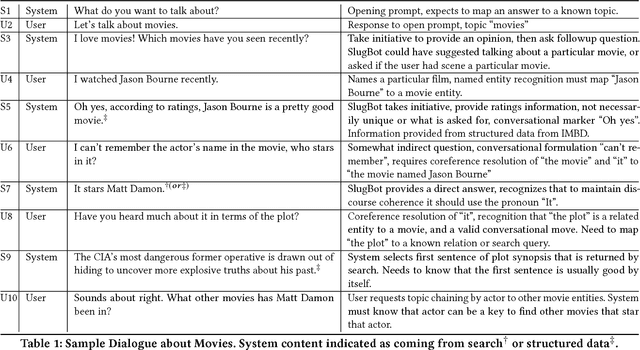


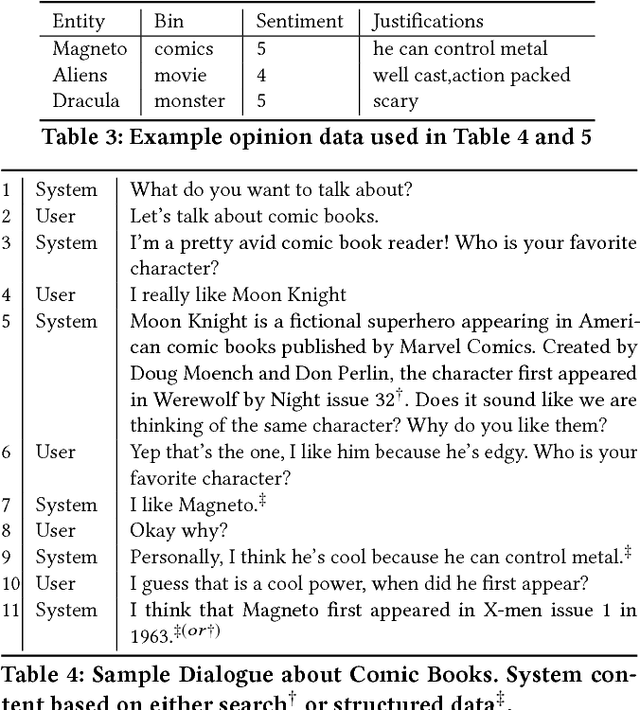
The greatest challenges in building sophisticated open-domain conversational agents arise directly from the potential for ongoing mixed-initiative multi-turn dialogues, which do not follow a particular plan or pursue a particular fixed information need. In order to make coherent conversational contributions in this context, a conversational agent must be able to track the types and attributes of the entities under discussion in the conversation and know how they are related. In some cases, the agent can rely on structured information sources to help identify the relevant semantic relations and produce a turn, but in other cases, the only content available comes from search, and it may be unclear which semantic relations hold between the search results and the discourse context. A further constraint is that the system must produce its contribution to the ongoing conversation in real-time. This paper describes our experience building SlugBot for the 2017 Alexa Prize, and discusses how we leveraged search and structured data from different sources to help SlugBot produce dialogic turns and carry on conversations whose length over the semi-finals user evaluation period averaged 8:17 minutes.
Creating and Characterizing a Diverse Corpus of Sarcasm in Dialogue
Sep 15, 2017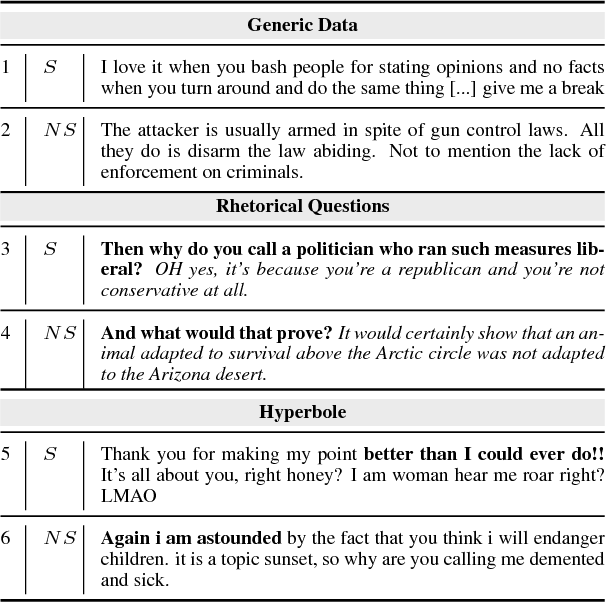

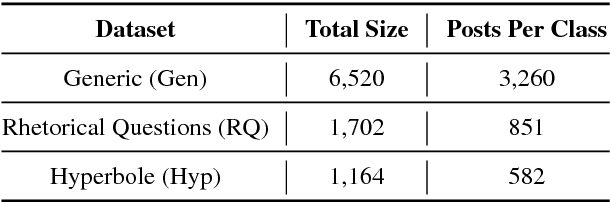
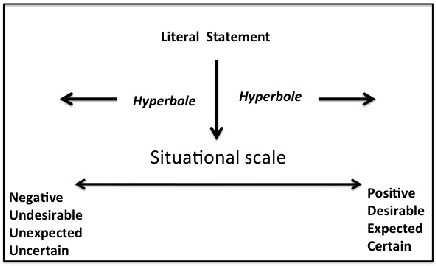
The use of irony and sarcasm in social media allows us to study them at scale for the first time. However, their diversity has made it difficult to construct a high-quality corpus of sarcasm in dialogue. Here, we describe the process of creating a large- scale, highly-diverse corpus of online debate forums dialogue, and our novel methods for operationalizing classes of sarcasm in the form of rhetorical questions and hyperbole. We show that we can use lexico-syntactic cues to reliably retrieve sarcastic utterances with high accuracy. To demonstrate the properties and quality of our corpus, we conduct supervised learning experiments with simple features, and show that we achieve both higher precision and F than previous work on sarcasm in debate forums dialogue. We apply a weakly-supervised linguistic pattern learner and qualitatively analyze the linguistic differences in each class.