 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Quality of Class-Conditional Generative Models in Time-Series Domain
Oct 14, 2022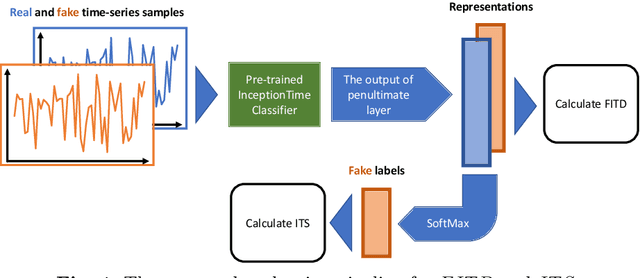
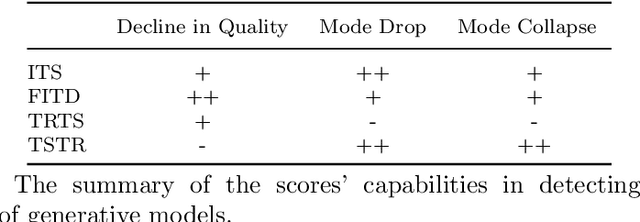
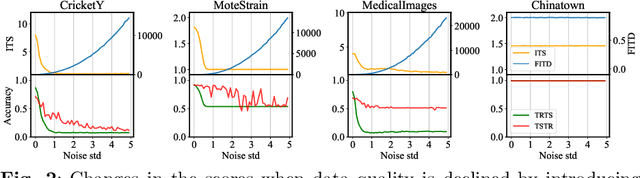
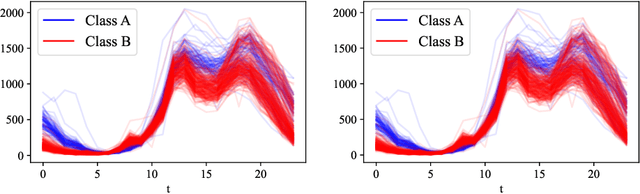
Generative models are designed to address the data scarcity problem. Even with the exploding amount of data, due to computational advancements, some applications (e.g., health care, weather forecast, fault detection) still suffer from data insufficiency, especially in the time-series domain. Thus generative models are essential and powerful tools, but they still lack a consensual approach for quality assessment. Such deficiency hinders the confident application of modern implicit generative models on time-series data. Inspired by assessment methods on the image domain, we introduce the InceptionTime Score (ITS) and the Frechet InceptionTime Distance (FITD) to gauge the qualitative performance of class conditional generative models on the time-series domain. We conduct extensive experiments on 80 different datasets to study the discriminative capabilities of proposed metrics alongside two existing evaluation metrics: Train on Synthetic Test on Real (TSTR) and Train on Real Test on Synthetic (TRTS). Extensive evaluation reveals that the proposed assessment method, i.e., ITS and FITD in combination with TSTR, can accurately assess class-conditional generative model performance.
Leveraging the Potential of Novel Data in Power Line Communication of Electricity Grids
Sep 23, 2022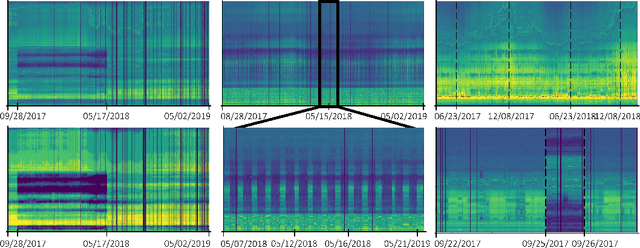

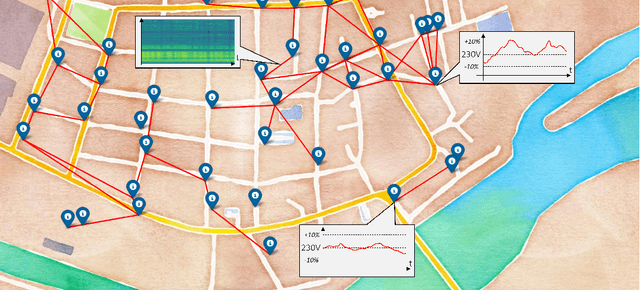

Electricity grids have become an essential part of daily life, even if they are often not noticed in everyday life. We usually only become particularly aware of this dependence by the time the electricity grid is no longer available. However, significant changes, such as the transition to renewable energy (photovoltaic, wind turbines, etc.) and an increasing number of energy consumers with complex load profiles (electric vehicles, home battery systems, etc.), pose new challenges for the electricity grid. To address these challenges, we propose two first-of-its-kind datasets based on measurements in a broadband powerline communications (PLC) infrastructure. Both datasets FiN-1 and FiN-2, were collected during real practical use in a part of the German low-voltage grid that supplies around 4.4 million people and show more than 13 billion datapoints collected by more than 5100 sensors. In addition, we present different use cases in asset management, grid state visualization, forecasting, predictive maintenance, and novelty detection to highlight the benefits of these types of data. For these applications, we particularly highlight the use of novel machine learning architectures to extract rich information from real-world data that cannot be captured using traditional approaches. By publishing the first large-scale real-world dataset, we aim to shed light on the previously largely unrecognized potential of PLC data and emphasize machine-learning-based research in low-voltage distribution networks by presenting a variety of different use cases.
Revisiting the Shape-Bias of Deep Learning for Dermoscopic Skin Lesion Classification
Jun 13, 2022
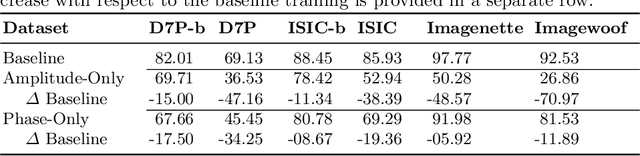
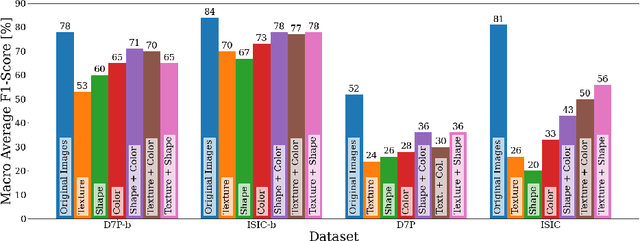
It is generally believed that the human visual system is biased towards the recognition of shapes rather than textures. This assumption has led to a growing body of work aiming to align deep models' decision-making processes with the fundamental properties of human vision. The reliance on shape features is primarily expected to improve the robustness of these models under covariate shift. In this paper, we revisit the significance of shape-biases for the classification of skin lesion images. Our analysis shows that different skin lesion datasets exhibit varying biases towards individual image features. Interestingly, despite deep feature extractors being inclined towards learning entangled features for skin lesion classification, individual features can still be decoded from this entangled representation. This indicates that these features are still represented in the learnt embedding spaces of the models, but not used for classification. In addition, the spectral analysis of different datasets shows that in contrast to common visual recognition, dermoscopic skin lesion classification, by nature, is reliant on complex feature combinations beyond shape-bias. As a natural consequence, shifting away from the prevalent desire of shape-biasing models can even improve skin lesion classifiers in some cases.
A Novel Approach to Train Diverse Types of Language Models for Health Mention Classification of Tweets
Apr 13, 2022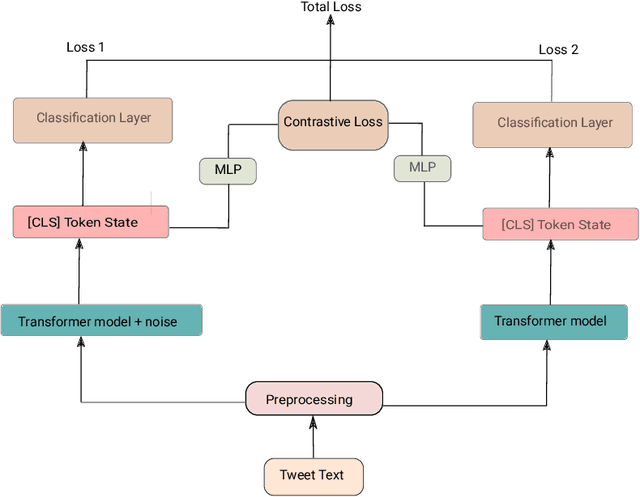

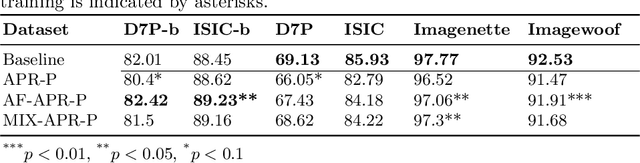
Health mention classification deals with the disease detection in a given text containing disease words. However, non-health and figurative use of disease words adds challenges to the task. Recently, adversarial training acting as a means of regularization has gained popularity in many NLP tasks. In this paper, we propose a novel approach to train language models for health mention classification of tweets that involves adversarial training. We generate adversarial examples by adding perturbation to the representations of transformer models for tweet examples at various levels using Gaussian noise. Further, we employ contrastive loss as an additional objective function. We evaluate the proposed method on the PHM2017 dataset extended version. Results show that our proposed approach improves the performance of classifier significantly over the baseline methods. Moreover, our analysis shows that adding noise at earlier layers improves models' performance whereas adding noise at intermediate layers deteriorates models' performance. Finally, adding noise towards the final layers performs better than the middle layers noise addition.
Improving Health Mentioning Classification of Tweets using Contrastive Adversarial Training
Mar 03, 2022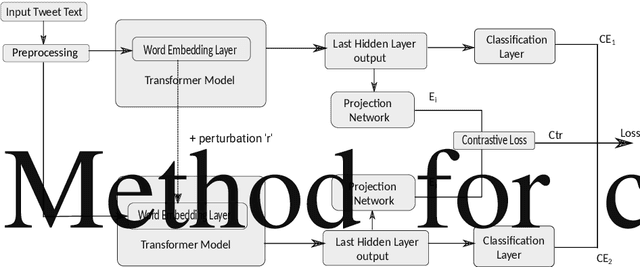

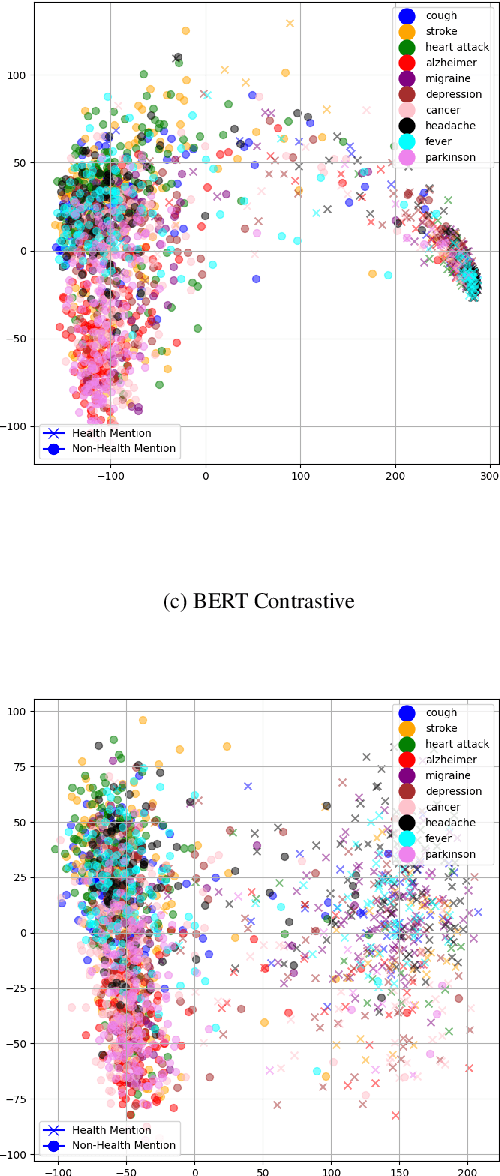
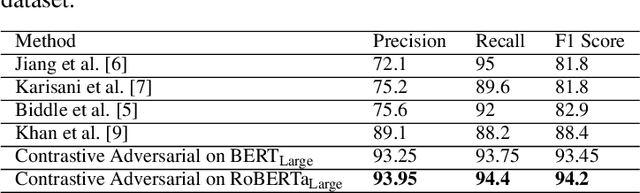
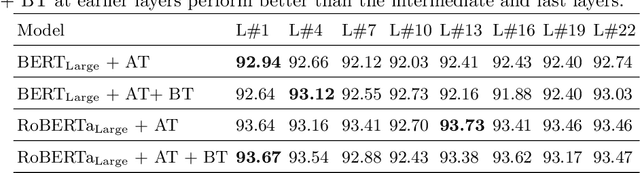
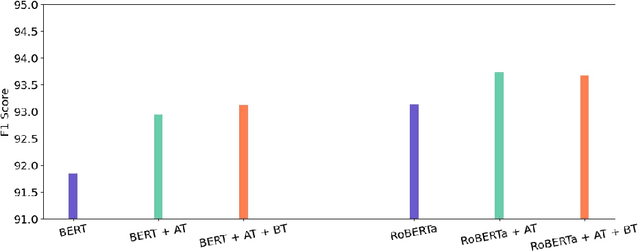
Health mentioning classification (HMC) classifies an input text as health mention or not. Figurative and non-health mention of disease words makes the classification task challenging. Learning the context of the input text is the key to this problem. The idea is to learn word representation by its surrounding words and utilize emojis in the text to help improve the classification results. In this paper, we improve the word representation of the input text using adversarial training that acts as a regularizer during fine-tuning of the model. We generate adversarial examples by perturbing the embeddings of the model and then train the model on a pair of clean and adversarial examples. Additionally, we utilize contrastive loss that pushes a pair of clean and perturbed examples close to each other and other examples away in the representation space. We train and evaluate the method on an extended version of the publicly available PHM2017 dataset. Experiments show an improvement of 1.0% over BERT-Large baseline and 0.6% over RoBERTa-Large baseline, whereas 5.8% over the state-of-the-art in terms of F1 score. Furthermore, we provide a brief analysis of the results by utilizing the power of explainable AI.
Utilizing Out-Domain Datasets to Enhance Multi-Task Citation Analysis
Feb 22, 2022
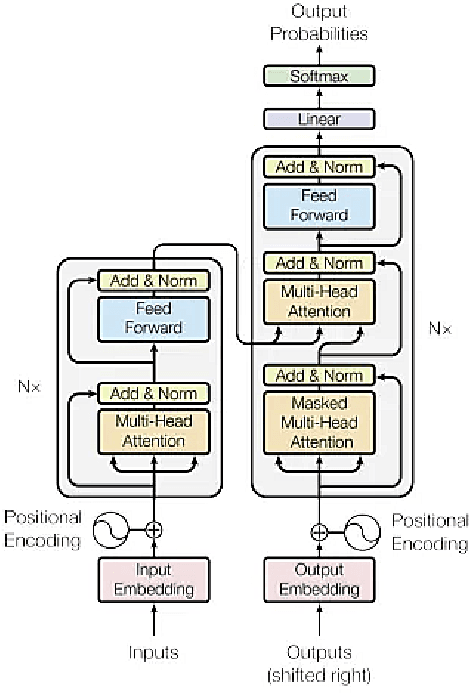
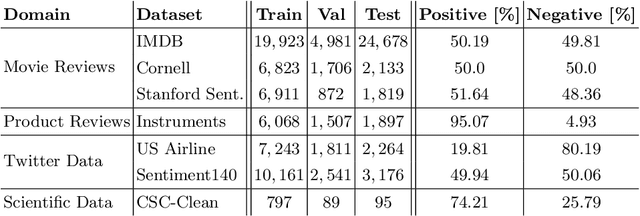
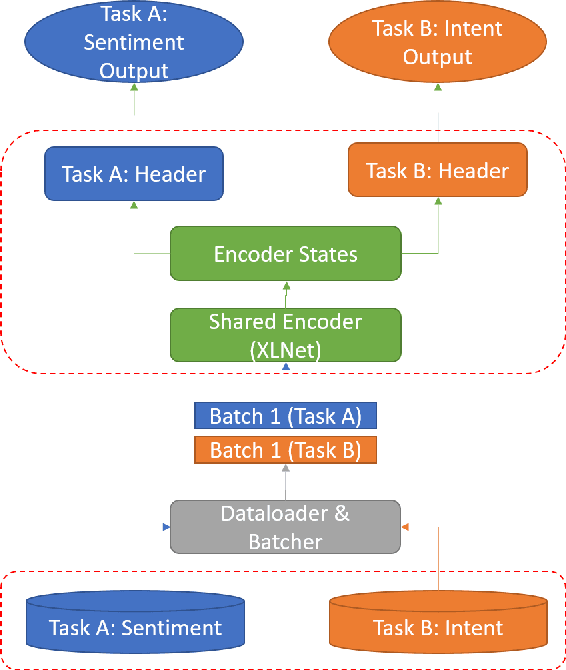
Citations are generally analyzed using only quantitative measures while excluding qualitative aspects such as sentiment and intent. However, qualitative aspects provide deeper insights into the impact of a scientific research artifact and make it possible to focus on relevant literature free from bias associated with quantitative aspects. Therefore, it is possible to rank and categorize papers based on their sentiment and intent. For this purpose, larger citation sentiment datasets are required. However, from a time and cost perspective, curating a large citation sentiment dataset is a challenging task. Particularly, citation sentiment analysis suffers from both data scarcity and tremendous costs for dataset annotation. To overcome the bottleneck of data scarcity in the citation analysis domain we explore the impact of out-domain data during training to enhance the model performance. Our results emphasize the use of different scheduling methods based on the use case. We empirically found that a model trained using sequential data scheduling is more suitable for domain-specific usecases. Conversely, shuffled data feeding achieves better performance on a cross-domain task. Based on our findings, we propose an end-to-end trainable multi-task model that covers the sentiment and intent analysis that utilizes out-domain datasets to overcome the data scarcity.
TimeREISE: Time-series Randomized Evolving Input Sample Explanation
Feb 16, 2022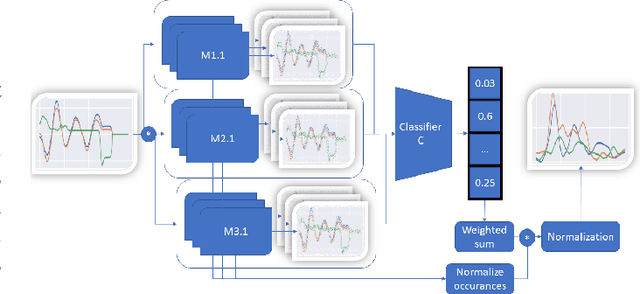
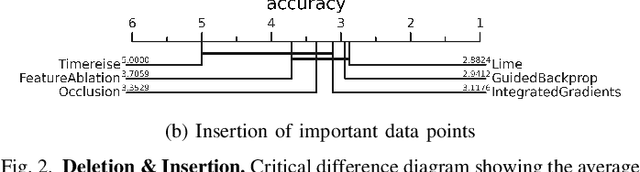
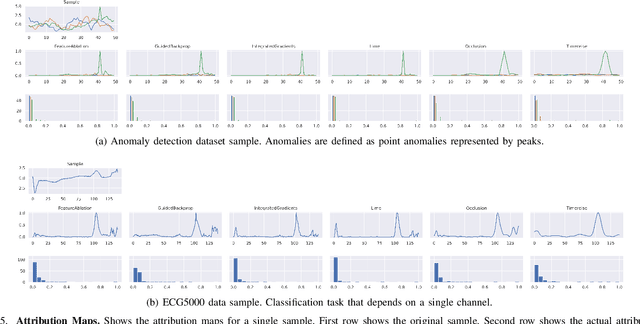
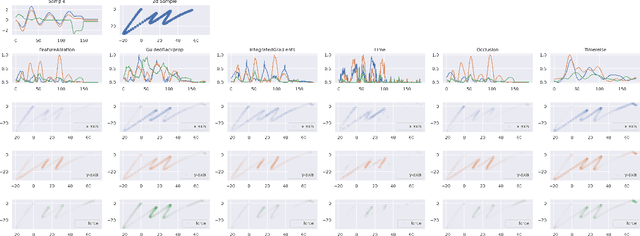
Deep neural networks are one of the most successful classifiers across different domains. However, due to their limitations concerning interpretability their use is limited in safety critical context. The research field of explainable artificial intelligence addresses this problem. However, most of the interpretability methods are aligned to the image modality by design. The paper introduces TimeREISE a model agnostic attribution method specifically aligned to success in the context of time series classification. The method shows superior performance compared to existing approaches concerning different well-established measurements. TimeREISE is applicable to any time series classification network, its runtime does not scale in a linear manner concerning the input shape and it does not rely on prior data knowledge.
KENN: Enhancing Deep Neural Networks by Leveraging Knowledge for Time Series Forecasting
Feb 16, 2022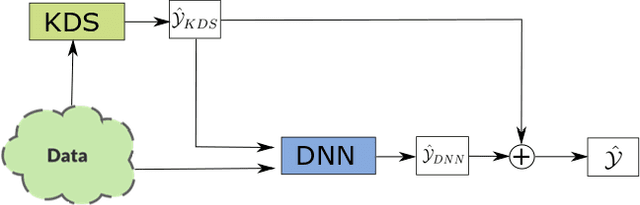
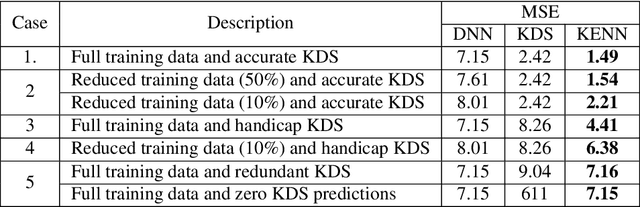
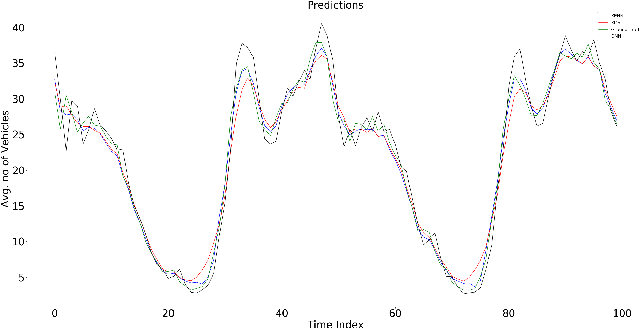
End-to-end data-driven machine learning methods often have exuberant requirements in terms of quality and quantity of training data which are often impractical to fulfill in real-world applications. This is specifically true in time series domain where problems like disaster prediction, anomaly detection, and demand prediction often do not have a large amount of historical data. Moreover, relying purely on past examples for training can be sub-optimal since in doing so we ignore one very important domain i.e knowledge, which has its own distinct advantages. In this paper, we propose a novel knowledge fusion architecture, Knowledge Enhanced Neural Network (KENN), for time series forecasting that specifically aims towards combining strengths of both knowledge and data domains while mitigating their individual weaknesses. We show that KENN not only reduces data dependency of the overall framework but also improves performance by producing predictions that are better than the ones produced by purely knowledge and data driven domains. We also compare KENN with state-of-the-art forecasting methods and show that predictions produced by KENN are significantly better even when trained on only 50\% of the data.
Time to Focus: A Comprehensive Benchmark Using Time Series Attribution Methods
Feb 08, 2022
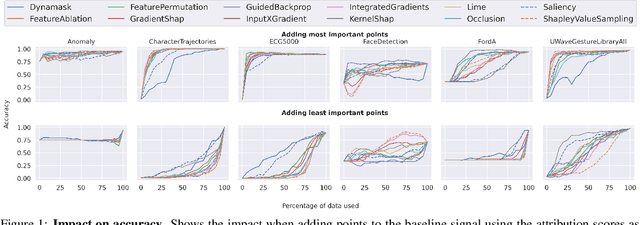
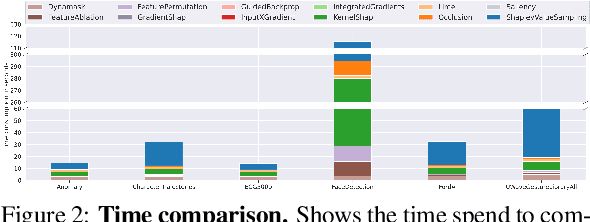
In the last decade neural network have made huge impact both in industry and research due to their ability to extract meaningful features from imprecise or complex data, and by achieving super human performance in several domains. However, due to the lack of transparency the use of these networks is hampered in the areas with safety critical areas. In safety-critical areas, this is necessary by law. Recently several methods have been proposed to uncover this black box by providing interpreation of predictions made by these models. The paper focuses on time series analysis and benchmark several state-of-the-art attribution methods which compute explanations for convolutional classifiers. The presented experiments involve gradient-based and perturbation-based attribution methods. A detailed analysis shows that perturbation-based approaches are superior concerning the Sensitivity and occlusion game. These methods tend to produce explanations with higher continuity. Contrarily, the gradient-based techniques are superb in runtime and Infidelity. In addition, a validation the dependence of the methods on the trained model, feasible application domains, and individual characteristics is attached. The findings accentuate that choosing the best-suited attribution method is strongly correlated with the desired use case. Neither category of attribution methods nor a single approach has shown outstanding performance across all aspects.
Random Noise vs State-of-the-Art Probabilistic Forecasting Methods : A Case Study on CRPS-Sum Discrimination Ability
Jan 21, 2022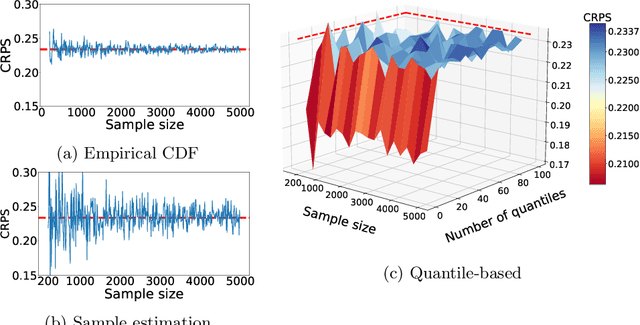

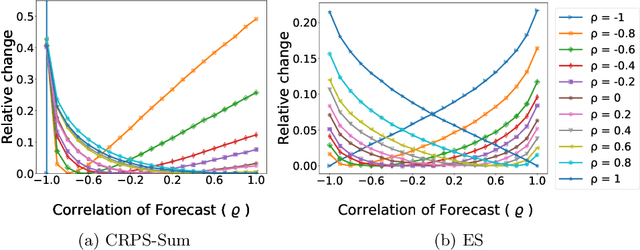
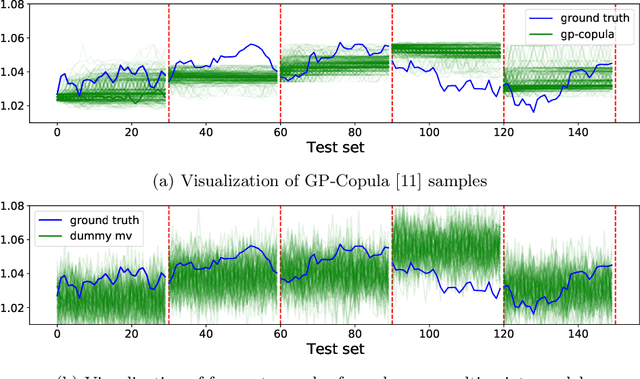
The recent developments in the machine learning domain have enabled the development of complex multivariate probabilistic forecasting models. Therefore, it is pivotal to have a precise evaluation method to gauge the performance and predictability power of these complex methods. To do so, several evaluation metrics have been proposed in the past (such as Energy Score, Dawid-Sebastiani score, variogram score), however, they cannot reliably measure the performance of a probabilistic forecaster. Recently, CRPS-sum has gained a lot of prominence as a reliable metric for multivariate probabilistic forecasting. This paper presents a systematic evaluation of CRPS-sum to understand its discrimination ability. We show that the statistical properties of target data affect the discrimination ability of CRPS-Sum. Furthermore, we highlight that CRPS-Sum calculation overlooks the performance of the model on each dimension. These flaws can lead us to an incorrect assessment of model performance. Finally, with experiments on the real-world dataset, we demonstrate that the shortcomings of CRPS-Sum provide a misleading indication of the probabilistic forecasting performance method. We show that it is easily possible to have a better CRPS-Sum for a dummy model, which looks like random noise, in comparison to the state-of-the-art method.