 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocXplain: A Novel Model-Agnostic Explainability Method for Document Image Classification
Jul 04, 2024Deep learning (DL) has revolutionized the field of document image analysis, showcasing superhuman performance across a diverse set of tasks. However, the inherent black-box nature of deep learning models still presents a significant challenge to their safe and robust deployment in industry. Regrettably, while a plethora of research has been dedicated in recent years to the development of DL-powered document analysis systems, research addressing their transparency aspects has been relatively scarce. In this paper, we aim to bridge this research gap by introducing DocXplain, a novel model-agnostic explainability method specifically designed for generating high interpretability feature attribution maps for the task of document image classification. In particular, our approach involves independently segmenting the foreground and background features of the documents into different document elements and then ablating these elements to assign feature importance. We extensively evaluate our proposed approach in the context of document image classification, utilizing 4 different evaluation metrics, 2 widely recognized document benchmark datasets, and 10 state-of-the-art document image classification models. By conducting a thorough quantitative and qualitative analysis against 9 existing state-of-the-art attribution methods, we demonstrate the superiority of our approach in terms of both faithfulness and interpretability. To the best of the authors' knowledge, this work presents the first model-agnostic attribution-based explainability method specifically tailored for document images. We anticipate that our work will significantly contribute to advancing research on transparency, fairness, and robustness of document image classification models.
VAEneu: A New Avenue for VAE Application on Probabilistic Forecasting
May 07, 2024This paper presents VAEneu, an innovative autoregressive method for multistep ahead univariate probabilistic time series forecasting. We employ the conditional VAE framework and optimize the lower bound of the predictive distribution likelihood function by adopting the Continuous Ranked Probability Score (CRPS), a strictly proper scoring rule, as the loss function. This novel pipeline results in forecasting sharp and well-calibrated predictive distribution. Through a comprehensive empirical study, VAEneu is rigorously benchmarked against 12 baseline models across 12 datasets. The results unequivocally demonstrate VAEneu's remarkable forecasting performance. VAEneu provides a valuable tool for quantifying future uncertainties, and our extensive empirical study lays the foundation for future comparative studies for univariate multistep ahead probabilistic forecasting.
Improving Disease Detection from Social Media Text via Self-Augmentation and Contrastive Learning
Apr 30, 2024



Detecting diseases from social media has diverse applications, such as public health monitoring and disease spread detection. While language models (LMs) have shown promising performance in this domain, there remains ongoing research aimed at refining their discriminating representations. In this paper, we propose a novel method that integrates Contrastive Learning (CL) with language modeling to address this challenge. Our approach introduces a self-augmentation method, wherein hidden representations of the model are augmented with their own representations. This method comprises two branches: the first branch, a traditional LM, learns features specific to the given data, while the second branch incorporates augmented representations from the first branch to encourage generalization. CL further refines these representations by pulling pairs of original and augmented versions closer while pushing other samples away. We evaluate our method on three NLP datasets encompassing binary, multi-label, and multi-class classification tasks involving social media posts related to various diseases. Our approach demonstrates notable improvements over traditional fine-tuning methods, achieving up to a 2.48% increase in F1-score compared to baseline approaches and a 2.1% enhancement over state-of-the-art methods.
Generating Counterfactual Trajectories with Latent Diffusion Models for Concept Discovery
Apr 16, 2024



Trustworthiness is a major prerequisite for the safe application of opaque deep learning models in high-stakes domains like medicine. Understanding the decision-making process not only contributes to fostering trust but might also reveal previously unknown decision criteria of complex models that could advance the state of medical research. The discovery of decision-relevant concepts from black box models is a particularly challenging task. This study proposes Concept Discovery through Latent Diffusion-based Counterfactual Trajectories (CDCT), a novel three-step framework for concept discovery leveraging the superior image synthesis capabilities of diffusion models. In the first step, CDCT uses a Latent Diffusion Model (LDM) to generate a counterfactual trajectory dataset. This dataset is used to derive a disentangled representation of classification-relevant concepts using a Variational Autoencoder (VAE). Finally, a search algorithm is applied to identify relevant concepts in the disentangled latent space. The application of CDCT to a classifier trained on the largest public skin lesion dataset revealed not only the presence of several biases but also meaningful biomarkers. Moreover, the counterfactuals generated within CDCT show better FID scores than those produced by a previously established state-of-the-art method, while being 12 times more resource-efficient. Unsupervised concept discovery holds great potential for the application of trustworthy AI and the further development of human knowledge in various domains. CDCT represents a further step in this direction.
Class Conditional Time Series Generation with Structured Noise Space GAN
Dec 20, 2023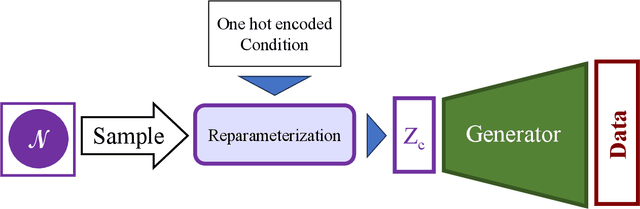



This paper introduces Structured Noise Space GAN (SNS-GAN), a novel approach in the field of generative modeling specifically tailored for class-conditional generation in both image and time series data. It addresses the challenge of effectively integrating class labels into generative models without requiring structural modifications to the network. The SNS-GAN method embeds class conditions within the generator's noise space, simplifying the training process and enhancing model versatility. The model's efficacy is demonstrated through qualitative validations in the image domain and superior performance in time series generation compared to baseline models. This research opens new avenues for the application of GANs in various domains, including but not limited to time series and image data generation.
Medi-CAT: Contrastive Adversarial Training for Medical Image Classification
Oct 31, 2023



There are not many large medical image datasets available. For these datasets, too small deep learning models can't learn useful features, so they don't work well due to underfitting, and too big models tend to overfit the limited data. As a result, there is a compromise between the two issues. This paper proposes a training strategy Medi-CAT to overcome the underfitting and overfitting phenomena in medical imaging datasets. Specifically, the proposed training methodology employs large pre-trained vision transformers to overcome underfitting and adversarial and contrastive learning techniques to prevent overfitting. The proposed method is trained and evaluated on four medical image classification datasets from the MedMNIST collection. Our experimental results indicate that the proposed approach improves the accuracy up to 2% on three benchmark datasets compared to well-known approaches, whereas it increases the performance up to 4.1% over the baseline methods.
A Unique Training Strategy to Enhance Language Models Capabilities for Health Mention Detection from Social Media Content
Oct 29, 2023



An ever-increasing amount of social media content requires advanced AI-based computer programs capable of extracting useful information. Specifically, the extraction of health-related content from social media is useful for the development of diverse types of applications including disease spread, mortality rate prediction, and finding the impact of diverse types of drugs on diverse types of diseases. Language models are competent in extracting the syntactic and semantics of text. However, they face a hard time extracting similar patterns from social media texts. The primary reason for this shortfall lies in the non-standardized writing style commonly employed by social media users. Following the need for an optimal language model competent in extracting useful patterns from social media text, the key goal of this paper is to train language models in such a way that they learn to derive generalized patterns. The key goal is achieved through the incorporation of random weighted perturbation and contrastive learning strategies. On top of a unique training strategy, a meta predictor is proposed that reaps the benefits of 5 different language models for discriminating posts of social media text into non-health and health-related classes. Comprehensive experimentation across 3 public benchmark datasets reveals that the proposed training strategy improves the performance of the language models up to 3.87%, in terms of F1-score, as compared to their performance with traditional training. Furthermore, the proposed meta predictor outperforms existing health mention classification predictors across all 3 benchmark datasets.
PrIeD-KIE: Towards Privacy Preserved Document Key Information Extraction
Oct 05, 2023



In this paper, we introduce strategies for developing private Key Information Extraction (KIE) systems by leveraging large pretrained document foundation models in conjunction with differential privacy (DP), federated learning (FL), and Differentially Private Federated Learning (DP-FL). Through extensive experimentation on six benchmark datasets (FUNSD, CORD, SROIE, WildReceipts, XFUND, and DOCILE), we demonstrate that large document foundation models can be effectively fine-tuned for the KIE task under private settings to achieve adequate performance while maintaining strong privacy guarantees. Moreover, by thoroughly analyzing the impact of various training and model parameters on model performance, we propose simple yet effective guidelines for achieving an optimal privacy-utility trade-off for the KIE task under global DP. Finally, we introduce FeAm-DP, a novel DP-FL algorithm that enables efficiently upscaling global DP from a standalone context to a multi-client federated environment. We conduct a comprehensive evaluation of the algorithm across various client and privacy settings, and demonstrate its capability to achieve comparable performance and privacy guarantees to standalone DP, even when accommodating an increasing number of participating clients. Overall, our study offers valuable insights into the development of private KIE systems, and highlights the potential of document foundation models for privacy-preserved Document AI applications. To the best of authors' knowledge, this is the first work that explores privacy preserved document KIE using document foundation models.
From Private to Public: Benchmarking GANs in the Context of Private Time Series Classification
Apr 19, 2023Deep learning has proven to be successful in various domains and for different tasks. However, when it comes to private data several restrictions are making it difficult to use deep learning approaches in these application fields. Recent approaches try to generate data privately instead of applying a privacy-preserving mechanism directly, on top of the classifier. The solution is to create public data from private data in a manner that preserves the privacy of the data. In this work, two very prominent GAN-based architectures were evaluated in the context of private time series classification. In contrast to previous work, mostly limited to the image domain, the scope of this benchmark was the time series domain. The experiments show that especially GSWGAN performs well across a variety of public datasets outperforming the competitor DPWGAN. An analysis of the generated datasets further validates the superiority of GSWGAN in the context of time series generation.
Privacy Meets Explainability: A Comprehensive Impact Benchmark
Nov 08, 2022
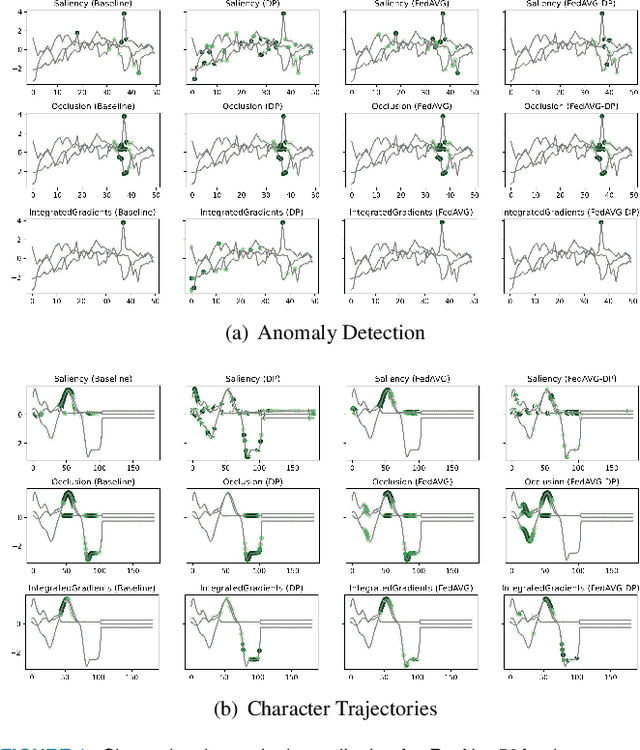


Since the mid-10s, the era of Deep Learning (DL) has continued to this day, bringing forth new superlatives and innovations each year. Nevertheless, the speed with which these innovations translate into real applications lags behind this fast pace. Safety-critical applications, in particular, underlie strict regulatory and ethical requirements which need to be taken care of and are still active areas of debate. eXplainable AI (XAI) and privacy-preserving machine learning (PPML) are both crucial research fields, aiming at mitigating some of the drawbacks of prevailing data-hungry black-box models in DL. Despite brisk research activity in the respective fields, no attention has yet been paid to their interaction. This work is the first to investigate the impact of private learning techniques on generated explanations for DL-based models. In an extensive experimental analysis covering various image and time series datasets from multiple domains, as well as varying privacy techniques, XAI methods, and model architectures, the effects of private training on generated explanations are studied. The findings suggest non-negligible changes in explanations through the introduction of privacy. Apart from reporting individual effects of PPML on XAI, the paper gives clear recommendations for the choice of techniques in real applications. By unveiling the interdependencies of these pivotal technologies, this work is a first step towards overcoming the remaining hurdles for practically applicable AI in safety-critical domains.