 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Substructure Discovery Algorithm For Homogeneous Multilayer Networks
Apr 27, 2025Graph mining analyzes real-world graphs to find core substructures (connected subgraphs) in applications modeled as graphs. Substructure discovery is a process that involves identifying meaningful patterns, structures, or components within a large data set. These substructures can be of various types, such as frequent patterns, motifs, or other relevant features within the data. To model complex data sets -- with multiple types of entities and relationships -- multilayer networks (or MLNs) have been shown to be more effective as compared to simple and attributed graphs. Analysis algorithms on MLNs using the decoupling approach have been shown to be both efficient and accurate. Hence, this paper focuses on substructure discovery in homogeneous multilayer networks (one type of MLN) using a novel decoupling-based approach. In this approach, each layer is processed independently, and then the results from two or more layers are composed to identify substructures in the entire MLN. The algorithm is designed and implemented, including the composition part, using one of the distributed processing frameworks (the Map/Reduce paradigm) to provide scalability. After establishing the correctness, we analyze the speedup and response time of the proposed algorithm and approach through extensive experimental analysis on large synthetic and real-world data sets with diverse graph characteristics.
From Base Data To Knowledge Discovery -- A Life Cycle Approach -- Using Multilayer Networks
May 24, 2021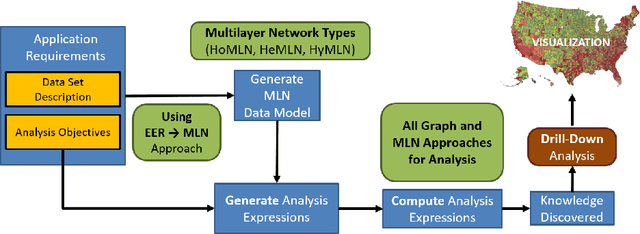
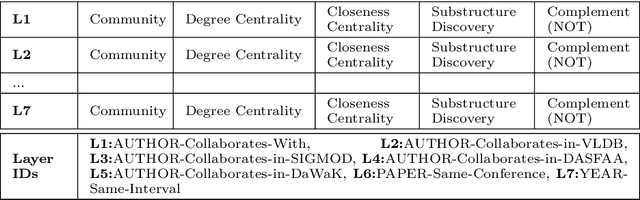
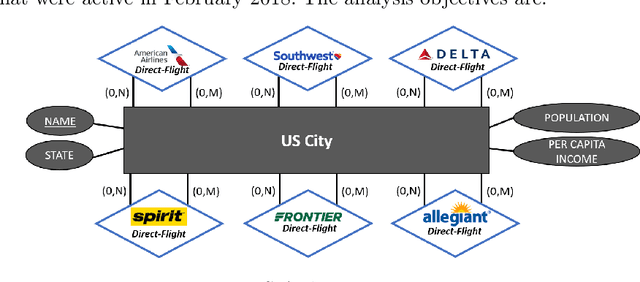
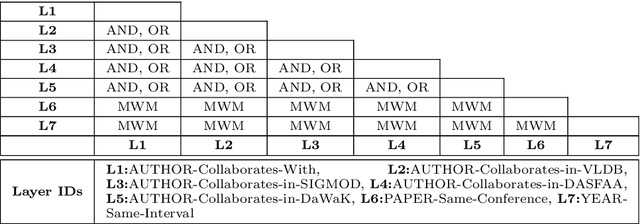
Any large complex data analysis to infer or discover meaningful information/knowledge involves the following steps (in addition to data collection, cleaning, preparing the data for analysis such as attribute elimination): i) Modeling the data -- an approach for modeling and deriving a data representation for analysis using that approach, ii) translating analysis objectives into computations on the model generated; this can be as simple as a single computation (e.g., community detection) or may involve a sequence of operations (e.g., pair-wise community detection over multiple networks) using expressions based on the model, iii) computation of the expressions generated -- efficiency and scalability come into picture here, and iv) drill-down of results to interpret or understand them clearly. Beyond this, it is also meaningful to visualize results for easier understanding. Covid-19 visualization dashboard presented in this paper is an example of this. This paper covers all of the above steps of data analysis life cycle using a data representation that is gaining importance for multi-entity, multi-feature data sets - Multilayer Networks. We use several data sets to establish the effectiveness of modeling using MLNs and analyze them using the proposed decoupling approach. For coverage, we use different types of MLNs for modeling, and community and centrality computations for analysis. The data sets used - US commercial airlines, IMDb, DBLP, and Covid-19 data set. Our experimental analyses using the identified steps validate modeling, breadth of objectives that can be computed, and overall versatility of the life cycle approach. Correctness of results is verified, where possible, using independently available ground truth. We demonstrate drill-down that is afforded by this approach (due to structure and semantics preservation) for a better understanding and visualization of results.
Generic Multilayer Network Data Analysis with the Fusion of Content and Structure
May 21, 2019
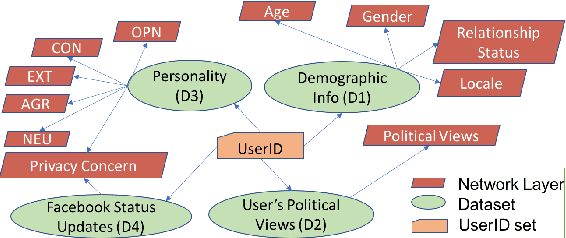
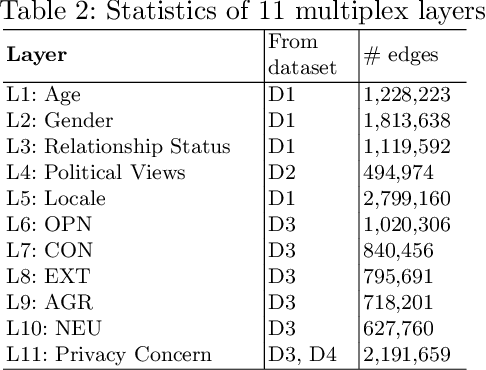
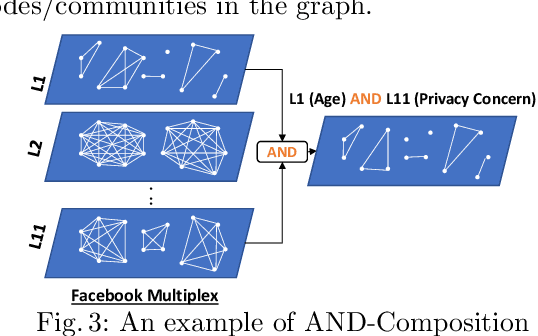
Multi-feature data analysis (e.g., on Facebook, LinkedIn) is challenging especially if one wants to do it efficiently and retain the flexibility by choosing features of interest for analysis. Features (e.g., age, gender, relationship, political view etc.) can be explicitly given from datasets, but also can be derived from content (e.g., political view based on Facebook posts). Analysis from multiple perspectives is needed to understand the datasets (or subsets of it) and to infer meaningful knowledge. For example, the influence of age, location, and marital status on political views may need to be inferred separately (or in combination). In this paper, we adapt multilayer network (MLN) analysis, a nontraditional approach, to model the Facebook datasets, integrate content analysis, and conduct analysis, which is driven by a list of desired application based queries. Our experimental analysis shows the flexibility and efficiency of the proposed approach when modeling and analyzing datasets with multiple features.
* 18 pages