 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fuzzy Similarity Based Concept Mining Model for Text Classification
Apr 10, 2012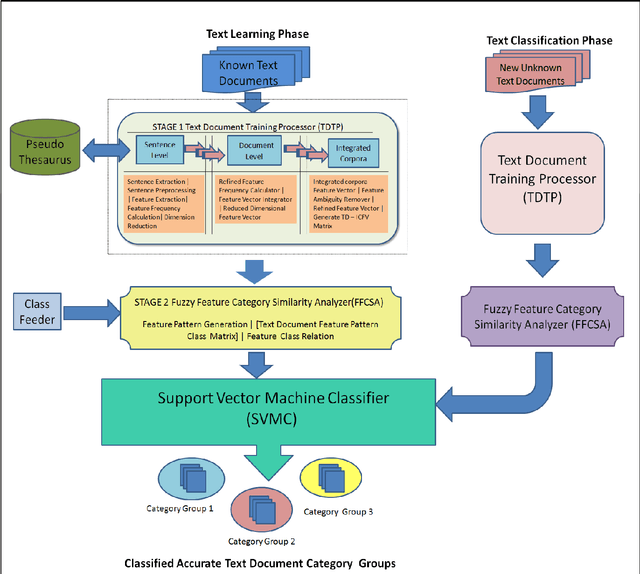
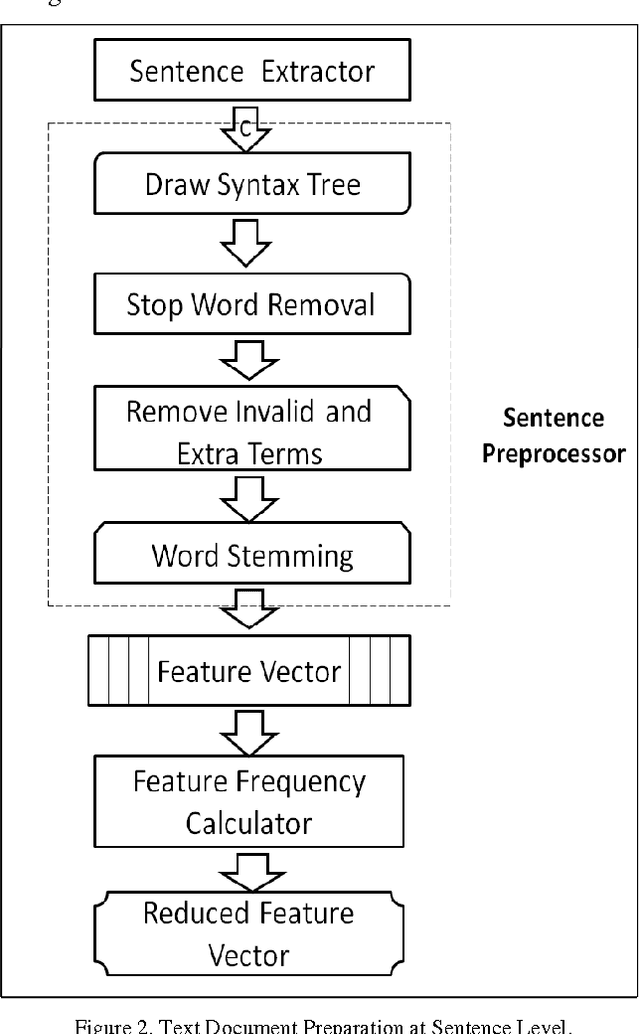
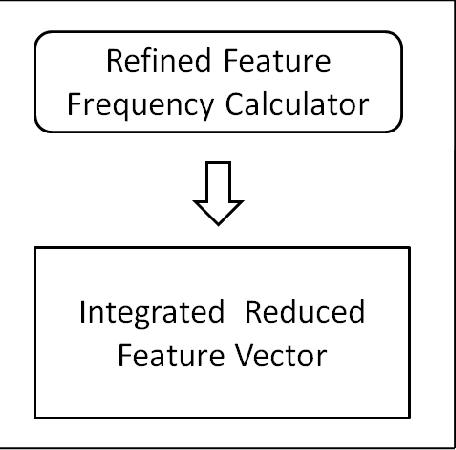
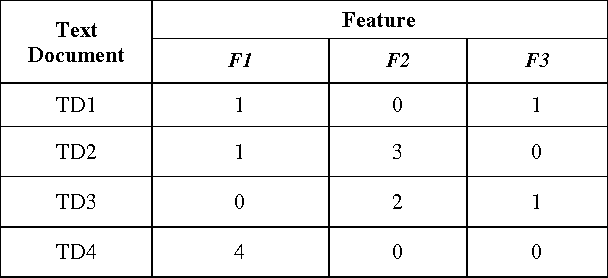
Text Classification is a challenging and a red hot field in the current scenario and has great importance in text categorization applications. A lot of research work has been done in this field but there is a need to categorize a collection of text documents into mutually exclusive categories by extracting the concepts or features using supervised learning paradigm and different classification algorithms. In this paper, a new Fuzzy Similarity Based Concept Mining Model (FSCMM) is proposed to classify a set of text documents into pre - defined Category Groups (CG) by providing them training and preparing on the sentence, document and integrated corpora levels along with feature reduction, ambiguity removal on each level to achieve high system performance. Fuzzy Feature Category Similarity Analyzer (FFCSA) is used to analyze each extracted feature of Integrated Corpora Feature Vector (ICFV) with the corresponding categories or classes. This model uses Support Vector Machine Classifier (SVMC) to classify correctly the training data patterns into two groups; i. e., + 1 and - 1, thereby producing accurate and correct results. The proposed model works efficiently and effectively with great performance and high - accuracy results.
* 7 Pages, 3 Figures, 2 Tables, International Journal of Advanced Computer Science and Applications(IJACSA)
A technical study and analysis on fuzzy similarity based models for text classification
Apr 10, 2012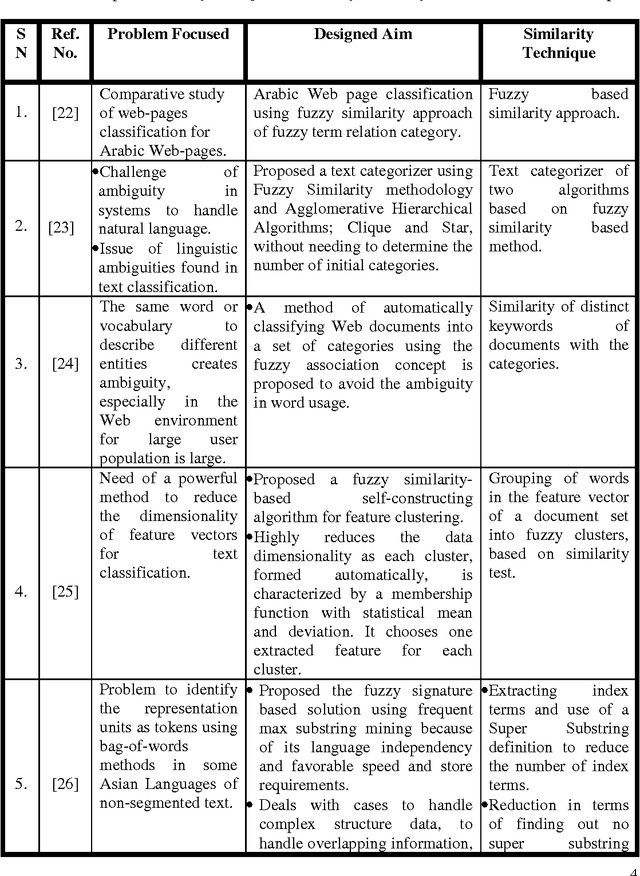
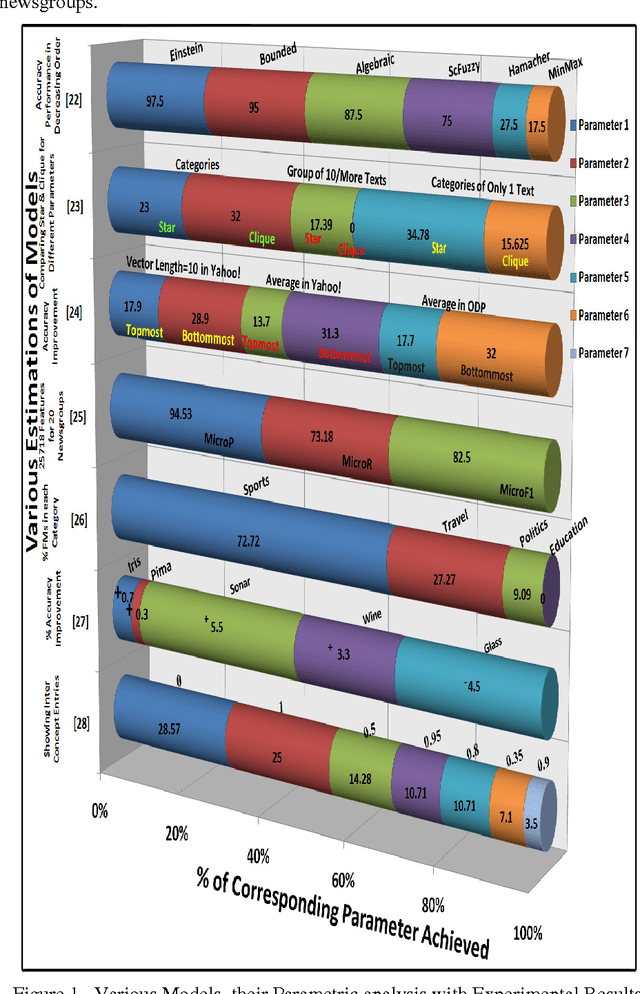
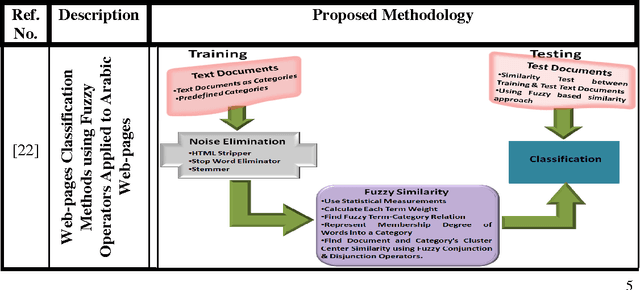
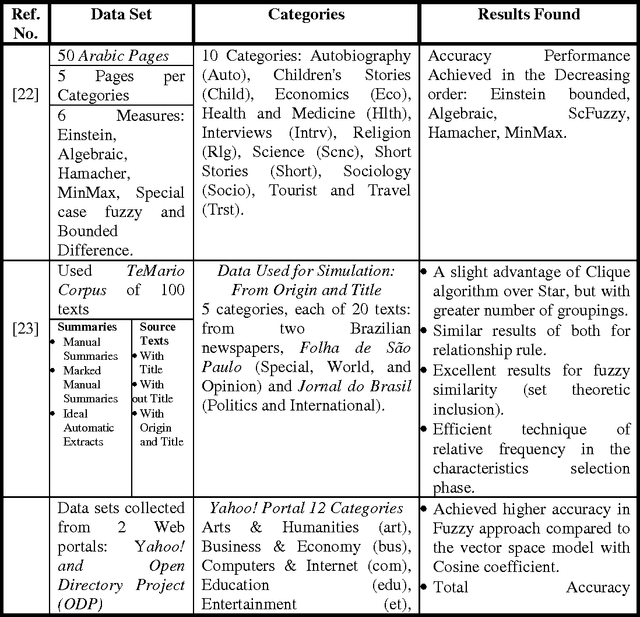
In this new and current era of technology, advancements and techniques, efficient and effective text document classification is becoming a challenging and highly required area to capably categorize text documents into mutually exclusive categories. Fuzzy similarity provides a way to find the similarity of features among various documents. In this paper, a technical review on various fuzzy similarity based models is given. These models are discussed and compared to frame out their use and necessity. A tour of different methodologies is provided which is based upon fuzzy similarity related concerns. It shows that how text and web documents are categorized efficiently into different categories. Various experimental results of these models are also discussed. The technical comparisons among each model's parameters are shown in the form of a 3-D chart. Such study and technical review provide a strong base of research work done on fuzzy similarity based text document categorization.
* 15 pages, 3 tables, 1 figure