 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Translation using Diffusion Models
Nov 02, 2021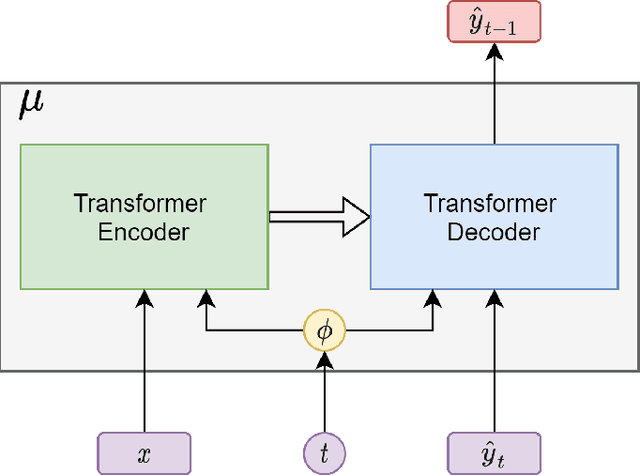
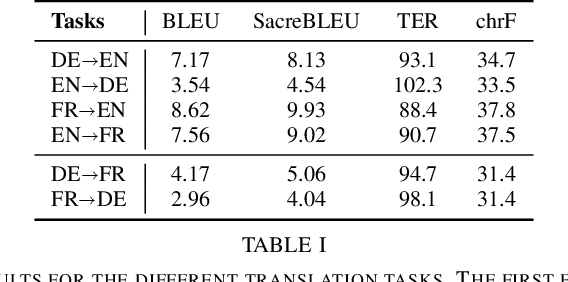
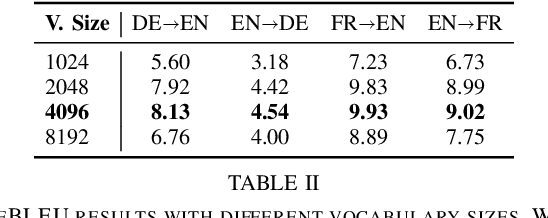
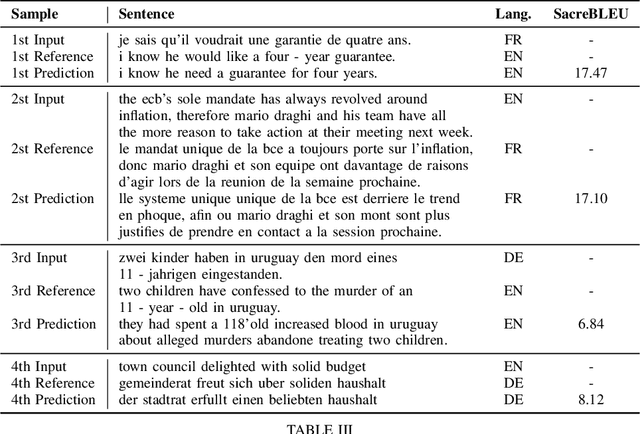
In this work, we show a novel method for neural machine translation (NMT), using a denoising diffusion probabilistic model (DDPM), adjusted for textual data, following recent advances in the field. We show that it's possible to translate sentences non-autoregressively using a diffusion model conditioned on the source sentence. We also show that our model is able to translate between pairs of languages unseen during training (zero-shot learning).
Many-Speakers Single Channel Speech Separation with Optimal Permutation Training
Apr 18, 2021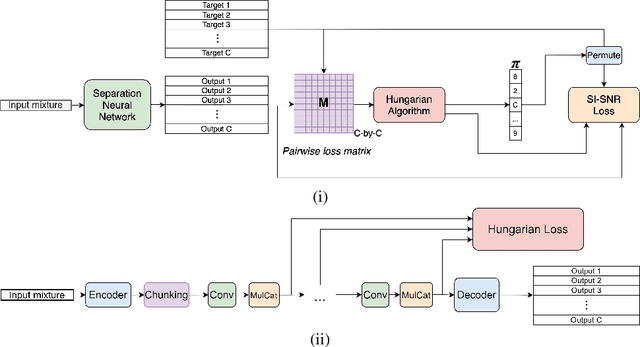
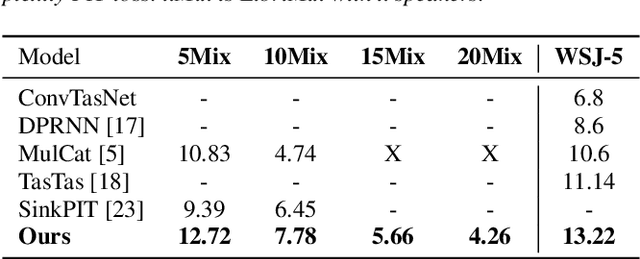
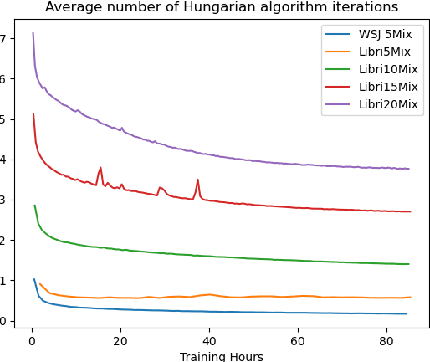
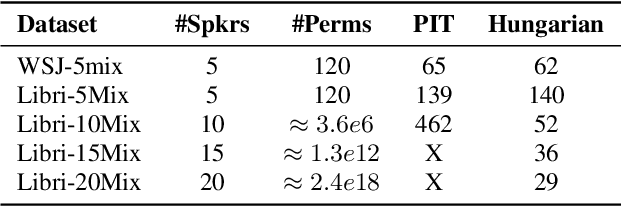
Single channel speech separation has experienced great progress in the last few years. However, training neural speech separation for a large number of speakers (e.g., more than 10 speakers) is out of reach for the current methods, which rely on the Permutation Invariant Loss (PIT). In this work, we present a permutation invariant training that employs the Hungarian algorithm in order to train with an $O(C^3)$ time complexity, where $C$ is the number of speakers, in comparison to $O(C!)$ of PIT based methods. Furthermore, we present a modified architecture that can handle the increased number of speakers. Our approach separates up to $20$ speakers and improves the previous results for large $C$ by a wide margin.