 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Layers for Deepfake Detection
Oct 11, 2022

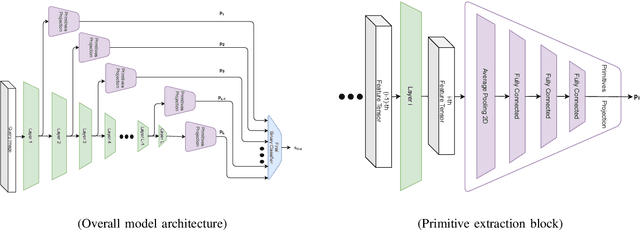
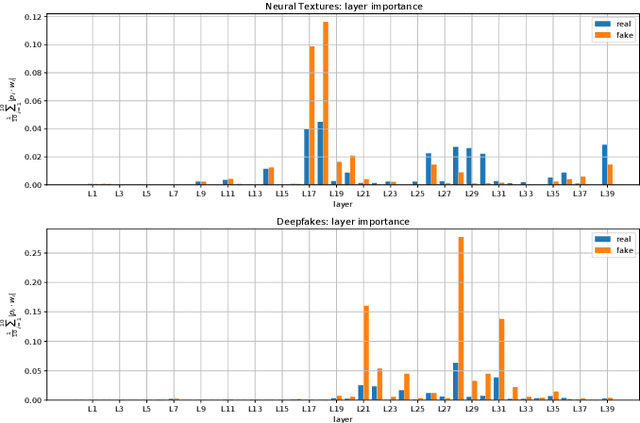
The increasing popularity of facial manipulation (Deepfakes) and synthetic face creation raises the need to develop robust forgery detection solutions. Crucially, most work in this domain assume that the Deepfakes in the test set come from the same Deepfake algorithms that were used for training the network. This is not how things work in practice. Instead, we consider the case where the network is trained on one Deepfake algorithm, and tested on Deepfakes generated by another algorithm. Typically, supervised techniques follow a pipeline of visual feature extraction from a deep backbone, followed by a binary classification head. Instead, our algorithm aggregates features extracted across all layers of one backbone network to detect a fake. We evaluate our approach on two domains of interest - Deepfake detection and Synthetic image detection, and find that we achieve SOTA results.
Stress-Testing LiDAR Registration
Apr 16, 2022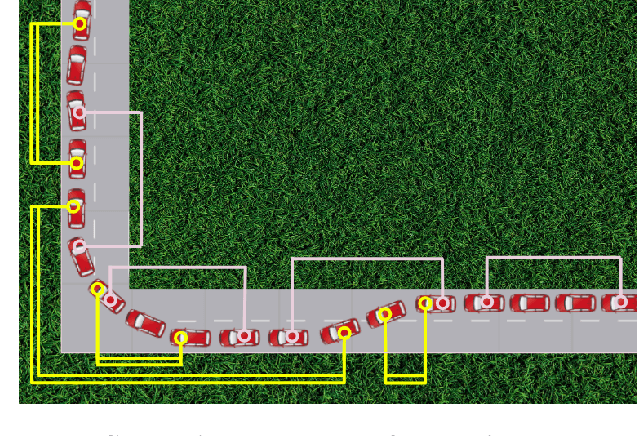
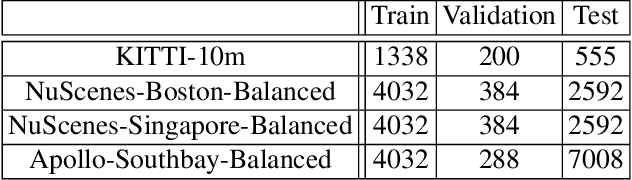
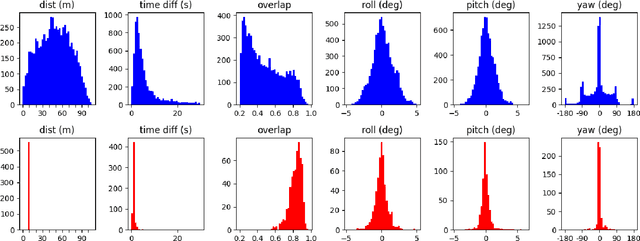
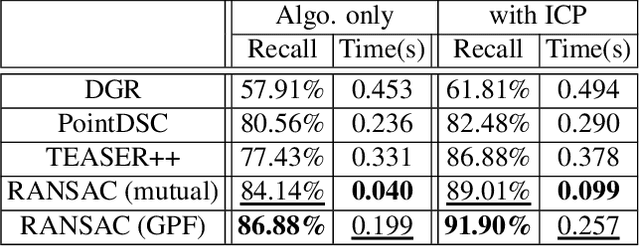
Point cloud registration (PCR) is an important task in many fields including autonomous driving with LiDAR sensors. PCR algorithms have improved significantly in recent years, by combining deep-learned features with robust estimation methods. These algorithms succeed in scenarios such as indoor scenes and object models registration. However, testing in the automotive LiDAR setting, which presents its own challenges, has been limited. The standard benchmark for this setting, KITTI-10m, has essentially been saturated by recent algorithms: many of them achieve near-perfect recall. In this work, we stress-test recent PCR techniques with LiDAR data. We propose a method for selecting balanced registration sets, which are challenging sets of frame-pairs from LiDAR datasets. They contain a balanced representation of the different relative motions that appear in a dataset, i.e. small and large rotations, small and large offsets in space and time, and various combinations of these. We perform a thorough comparison of accuracy and run-time on these benchmarks. Perhaps unexpectedly, we find that the fastest and simultaneously most accurate approach is a version of advanced RANSAC. We further improve results with a novel pre-filtering method.
How Low Can We Go? Pixel Annotation for Semantic Segmentation
Jan 25, 2022How many labeled pixels are needed to segment an image, without any prior knowledge? We conduct an experiment to answer this question. In our experiment, an Oracle is using Active Learning to train a network from scratch. The Oracle has access to the entire label map of the image, but the goal is to reveal as little pixel labels to the network as possible. We find that, on average, the Oracle needs to reveal (i.e., annotate) less than $0.1\%$ of the pixels in order to train a network. The network can then label all pixels in the image at an accuracy of more than $98\%$. Based on this single-image-annotation experiment, we design an experiment to quickly annotate an entire data set. In the data set level experiment the Oracle trains a new network for each image from scratch. The network can then be used to create pseudo-labels, which are the network predicted labels of the unlabeled pixels, for the entire image. Only then, a data set level network is trained from scratch on all the pseudo-labeled images at once. We repeat both image level and data set level experiments on two, very different, real-world data sets, and find that it is possible to reach the performance of a fully annotated data set using a fraction of the annotation cost.
Transformaly -- Two (Feature Spaces) Are Better Than One
Dec 08, 2021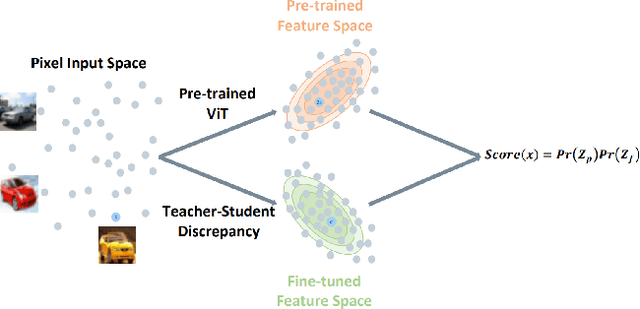
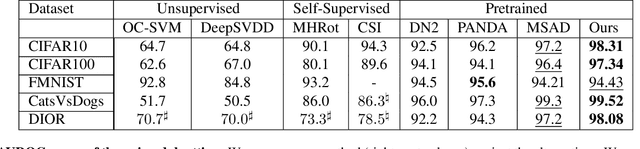
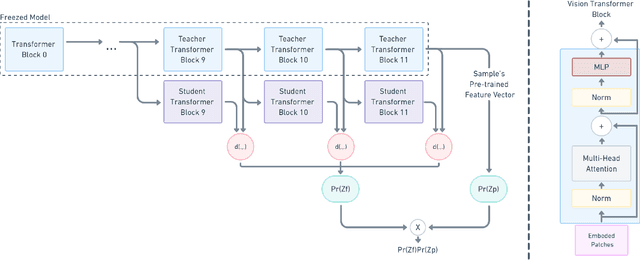
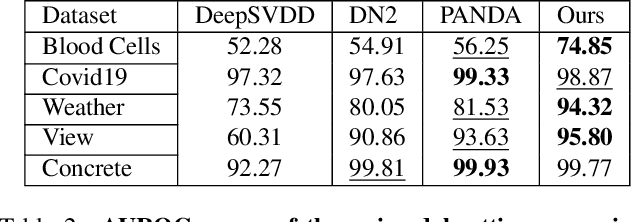
Anomaly detection is a well-established research area that seeks to identify samples outside of a predetermined distribution. An anomaly detection pipeline is comprised of two main stages: (1) feature extraction and (2) normality score assignment. Recent papers used pre-trained networks for feature extraction achieving state-of-the-art results. However, the use of pre-trained networks does not fully-utilize the normal samples that are available at train time. This paper suggests taking advantage of this information by using teacher-student training. In our setting, a pretrained teacher network is used to train a student network on the normal training samples. Since the student network is trained only on normal samples, it is expected to deviate from the teacher network in abnormal cases. This difference can serve as a complementary representation to the pre-trained feature vector. Our method -- Transformaly -- exploits a pre-trained Vision Transformer (ViT) to extract both feature vectors: the pre-trained (agnostic) features and the teacher-student (fine-tuned) features. We report state-of-the-art AUROC results in both the common unimodal setting, where one class is considered normal and the rest are considered abnormal, and the multimodal setting, where all classes but one are considered normal, and just one class is considered abnormal. The code is available at https://github.com/MatanCohen1/Transformaly.
Adversarial Mask: Real-World Adversarial Attack Against Face Recognition Models
Nov 21, 2021
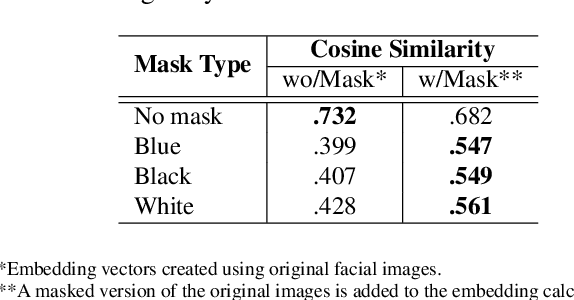
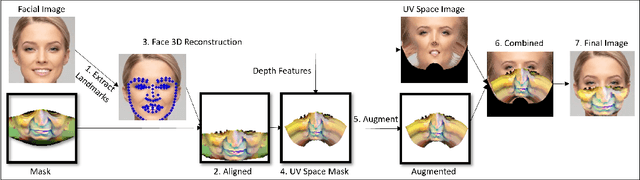
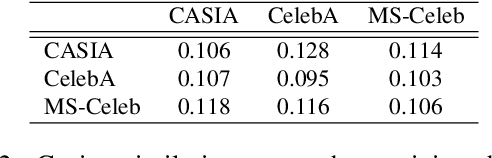
Deep learning-based facial recognition (FR) models have demonstrated state-of-the-art performance in the past few years, even when wearing protective medical face masks became commonplace during the COVID-19 pandemic. Given the outstanding performance of these models, the machine learning research community has shown increasing interest in challenging their robustness. Initially, researchers presented adversarial attacks in the digital domain, and later the attacks were transferred to the physical domain. However, in many cases, attacks in the physical domain are conspicuous, requiring, for example, the placement of a sticker on the face, and thus may raise suspicion in real-world environments (e.g., airports). In this paper, we propose Adversarial Mask, a physical adversarial universal perturbation (UAP) against state-of-the-art FR models that is applied on face masks in the form of a carefully crafted pattern. In our experiments, we examined the transferability of our adversarial mask to a wide range of FR model architectures and datasets. In addition, we validated our adversarial mask effectiveness in real-world experiments by printing the adversarial pattern on a fabric medical face mask, causing the FR system to identify only 3.34% of the participants wearing the mask (compared to a minimum of 83.34% with other evaluated masks).
DPC: Unsupervised Deep Point Correspondence via Cross and Self Construction
Oct 16, 2021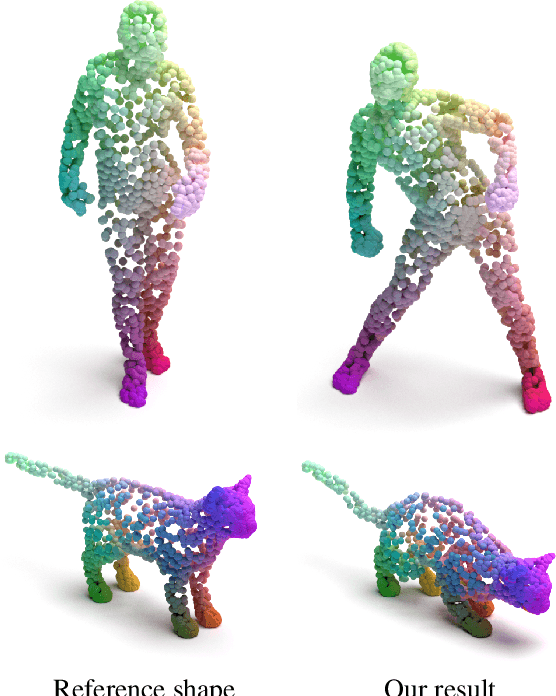
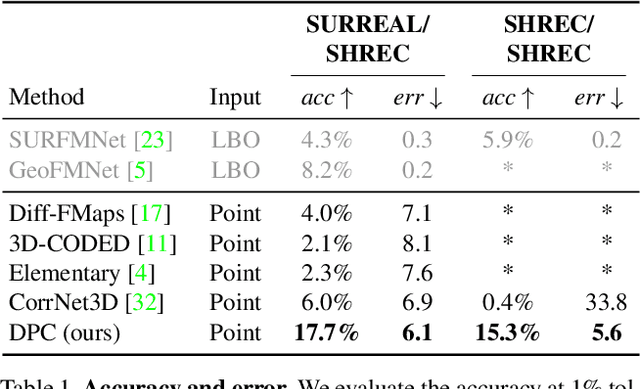
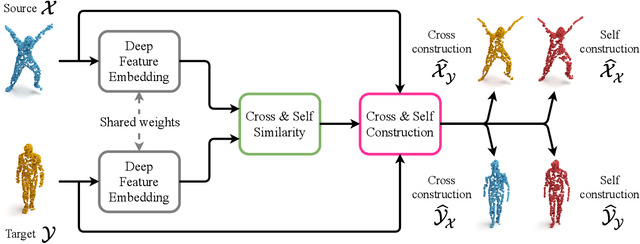
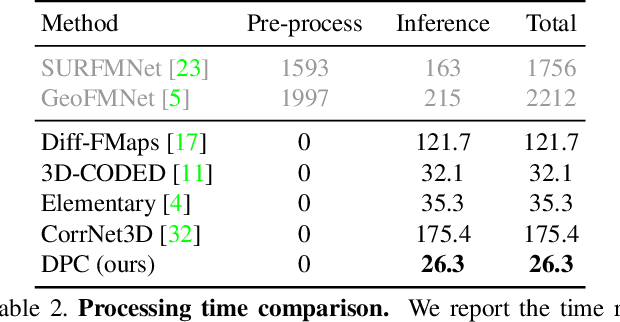
We present a new method for real-time non-rigid dense correspondence between point clouds based on structured shape construction. Our method, termed Deep Point Correspondence (DPC), requires a fraction of the training data compared to previous techniques and presents better generalization capabilities. Until now, two main approaches have been suggested for the dense correspondence problem. The first is a spectral-based approach that obtains great results on synthetic datasets but requires mesh connectivity of the shapes and long inference processing time while being unstable in real-world scenarios. The second is a spatial approach that uses an encoder-decoder framework to regress an ordered point cloud for the matching alignment from an irregular input. Unfortunately, the decoder brings considerable disadvantages, as it requires a large amount of training data and struggles to generalize well in cross-dataset evaluations. DPC's novelty lies in its lack of a decoder component. Instead, we use latent similarity and the input coordinates themselves to construct the point cloud and determine correspondence, replacing the coordinate regression done by the decoder. Extensive experiments show that our construction scheme leads to a performance boost in comparison to recent state-of-the-art correspondence methods. Our code is publicly available at https://github.com/dvirginz/DPC.
DeepBBS: Deep Best Buddies for Point Cloud Registration
Oct 16, 2021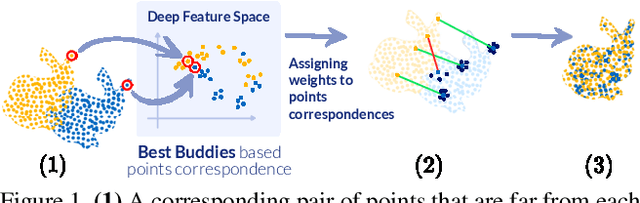
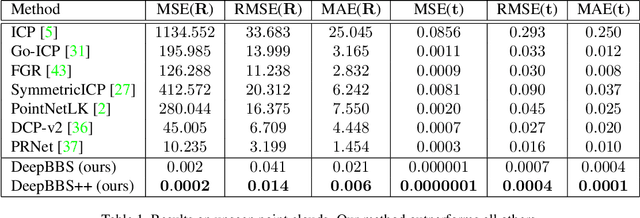
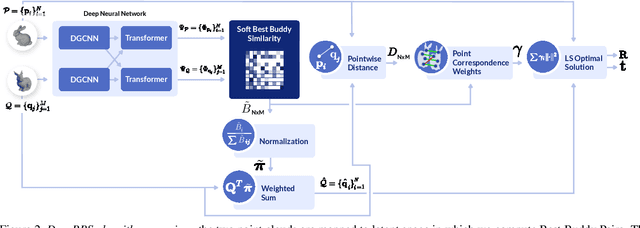
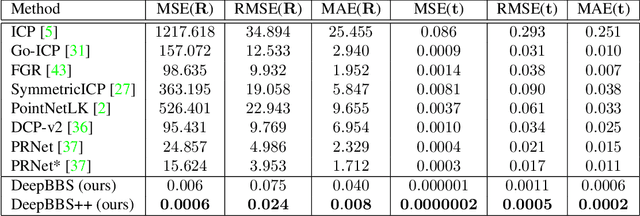
Recently, several deep learning approaches have been proposed for point cloud registration. These methods train a network to generate a representation that helps finding matching points in two 3D point clouds. Finding good matches allows them to calculate the transformation between the point clouds accurately. Two challenges of these techniques are dealing with occlusions and generalizing to objects of classes unseen during training. This work proposes DeepBBS, a novel method for learning a representation that takes into account the best buddy distance between points during training. Best Buddies (i.e., mutual nearest neighbors) are pairs of points nearest to each other. The Best Buddies criterion is a strong indication for correct matches that, in turn, leads to accurate registration. Our experiments show improved performance compared to previous methods. In particular, our learned representation leads to an accurate registration for partial shapes and in unseen categories.
kNet: A Deep kNN Network To Handle Label Noise
Jul 20, 2021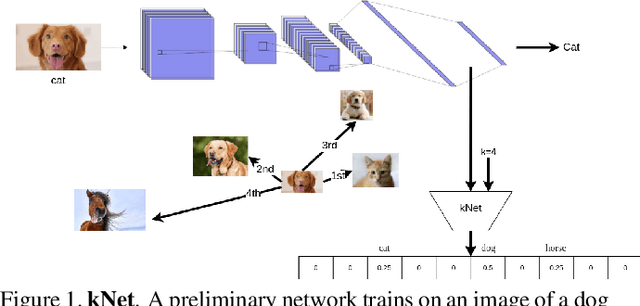

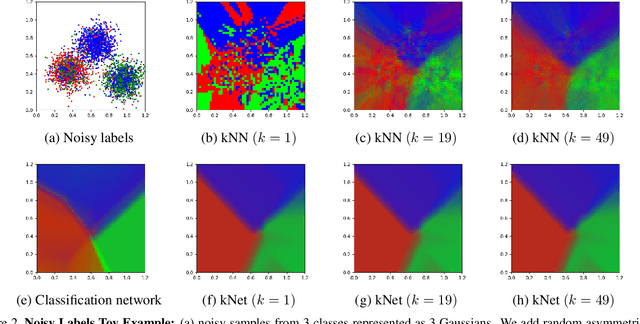
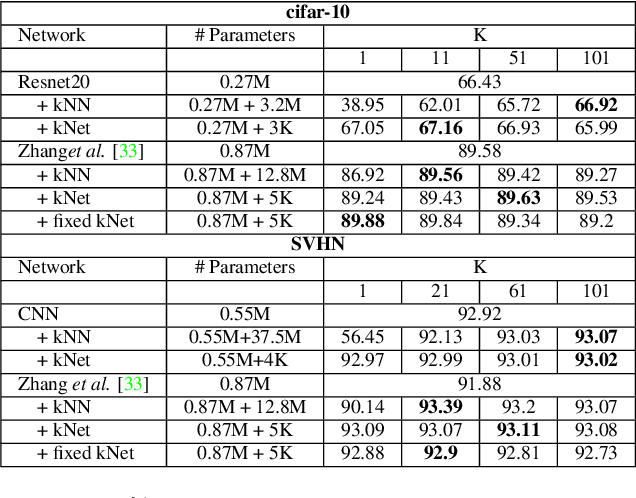
Deep Neural Networks require large amounts of labeled data for their training. Collecting this data at scale inevitably causes label noise.Hence,the need to develop learning algorithms that are robust to label noise. In recent years, k Nearest Neighbors (kNN) emerged as a viable solution to this problem. Despite its success, kNN is not without its problems. Mainly, it requires a huge memory footprint to store all the training samples and it needs an advanced data structure to allow for fast retrieval of the relevant examples, given a query sample. We propose a neural network, termed kNet, that learns to perform kNN. Once trained, we no longer need to store the training data, and processing a query sample is a simple matter of inference. To use kNet, we first train a preliminary network on the data set, and then train kNet on the penultimate layer of the preliminary network.We find that kNet gives a smooth approximation of kNN,and cannot handle the sharp label changes between samples that kNN can exhibit. This indicates that currently kNet is best suited to approximate kNN with a fairly large k. Experiments on two data sets show that this is the regime in which kNN works best,and can therefore be replaced by kNet.In practice, kNet consistently improve the results of all preliminary networks, in all label noise regimes, by up to 3%.
Reducing ReLU Count for Privacy-Preserving CNN Speedup
Jan 28, 2021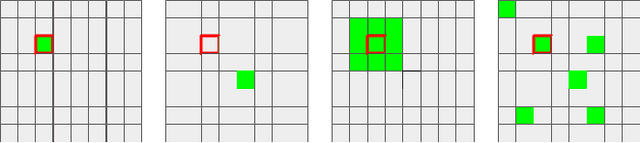
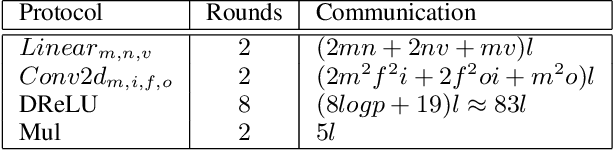
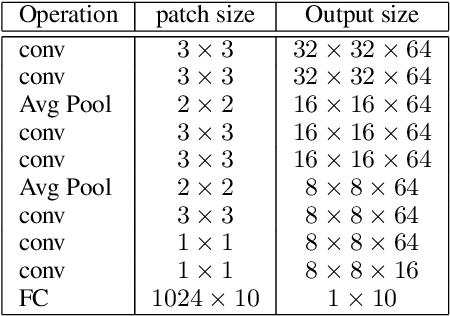
Privacy-Preserving Machine Learning algorithms must balance classification accuracy with data privacy. This can be done using a combination of cryptographic and machine learning tools such as Convolutional Neural Networks (CNN). CNNs typically consist of two types of operations: a convolutional or linear layer, followed by a non-linear function such as ReLU. Each of these types can be implemented efficiently using a different cryptographic tool. But these tools require different representations and switching between them is time-consuming and expensive. Recent research suggests that ReLU is responsible for most of the communication bandwidth. ReLU is usually applied at each pixel (or activation) location, which is quite expensive. We propose to share ReLU operations. Specifically, the ReLU decision of one activation can be used by others, and we explore different ways to group activations and different ways to determine the ReLU for such a group of activations. Experiments on several datasets reveal that we can cut the number of ReLU operations by up to three orders of magnitude and, as a result, cut the communication bandwidth by more than 50%.
Geometric Adversarial Attacks and Defenses on 3D Point Clouds
Dec 10, 2020
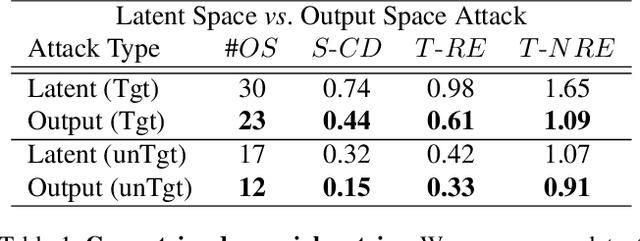
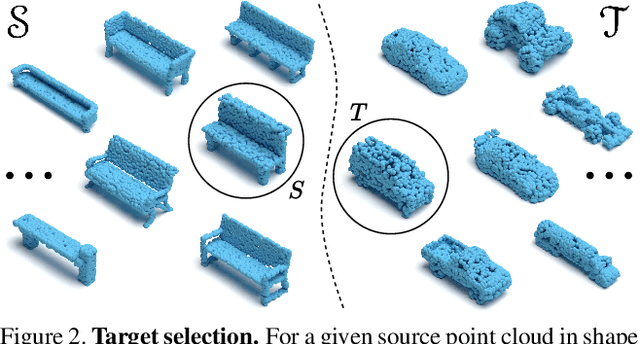
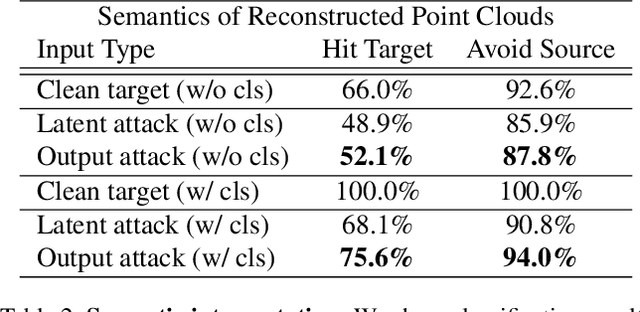
Deep neural networks are prone to adversarial examples that maliciously alter the network's outcome. Due to the increasing popularity of 3D sensors in safety-critical systems and the vast deployment of deep learning models for 3D point sets, there is a growing interest in adversarial attacks and defenses for such models. So far, the research has focused on the semantic level, namely, deep point cloud classifiers. However, point clouds are also widely used in a geometric-related form that includes encoding and reconstructing the geometry. In this work, we explore adversarial examples at a geometric level. That is, a small change to a clean source point cloud leads, after passing through an autoencoder model, to a shape from a different target class. On the defense side, we show that remnants of the attack's target shape are still present at the reconstructed output after applying the defense to the adversarial input. Our code is publicly available at https://github.com/itailang/geometric_adv.