 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Computation in Action: Hyperdimensional Deep Embedding Spaces of Gigapixel Pathology Images
Mar 02, 2023



One of the main obstacles of adopting digital pathology is the challenge of efficient processing of hyperdimensional digitized biopsy samples, called whole slide images (WSIs). Exploiting deep learning and introducing compact WSI representations are urgently needed to accelerate image analysis and facilitate the visualization and interpretability of pathology results in a postpandemic world. In this paper, we introduce a new evolutionary approach for WSI representation based on large-scale multi-objective optimization (LSMOP) of deep embeddings. We start with patch-based sampling to feed KimiaNet , a histopathology-specialized deep network, and to extract a multitude of feature vectors. Coarse multi-objective feature selection uses the reduced search space strategy guided by the classification accuracy and the number of features. In the second stage, the frequent features histogram (FFH), a novel WSI representation, is constructed by multiple runs of coarse LSMOP. Fine evolutionary feature selection is then applied to find a compact (short-length) feature vector based on the FFH and contributes to a more robust deep-learning approach to digital pathology supported by the stochastic power of evolutionary algorithms. We validate the proposed schemes using The Cancer Genome Atlas (TCGA) images in terms of WSI representation, classification accuracy, and feature quality. Furthermore, a novel decision space for multicriteria decision making in the LSMOP field is introduced. Finally, a patch-level visualization approach is proposed to increase the interpretability of deep features. The proposed evolutionary algorithm finds a very compact feature vector to represent a WSI (almost 14,000 times smaller than the original feature vectors) with 8% higher accuracy compared to the codes provided by the state-of-the-art methods.
Variable Functioning and Its Application to Large Scale Steel Frame Design Optimization
May 15, 2022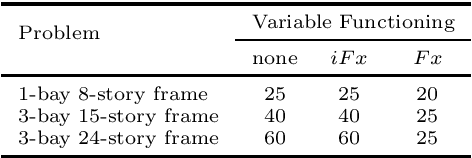
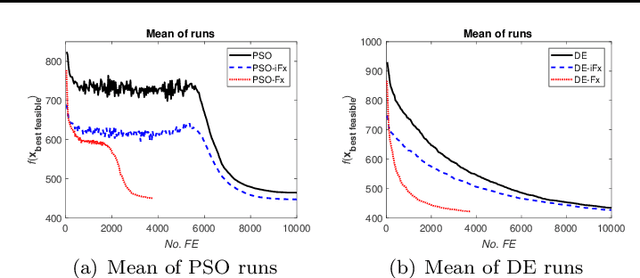
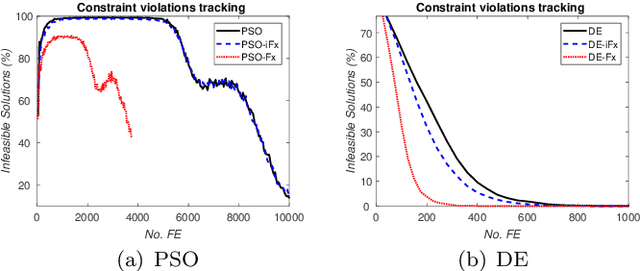
To solve complex real-world problems, heuristics and concept-based approaches can be used in order to incorporate information into the problem. In this study, a concept-based approach called variable functioning Fx is introduced to reduce the optimization variables and narrow down the search space. In this method, the relationships among one or more subset of variables are defined with functions using information prior to optimization; thus, instead of modifying the variables in the search process, the function variables are optimized. By using problem structure analysis technique and engineering expert knowledge, the $Fx$ method is used to enhance the steel frame design optimization process as a complex real-world problem. The proposed approach is coupled with particle swarm optimization and differential evolution algorithms and used for three case studies. The algorithms are applied to optimize the case studies by considering the relationships among column cross-section areas. The results show that $Fx$ can significantly improve both the convergence rate and the final design of a frame structure, even if it is only used for seeding.
Hospital-Agnostic Image Representation Learning in Digital Pathology
Apr 05, 2022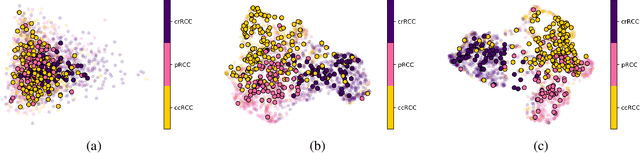

Whole Slide Images (WSIs) in digital pathology are used to diagnose cancer subtypes. The difference in procedures to acquire WSIs at various trial sites gives rise to variability in the histopathology images, thus making consistent diagnosis challenging. These differences may stem from variability in image acquisition through multi-vendor scanners, variable acquisition parameters, and differences in staining procedure; as well, patient demographics may bias the glass slide batches before image acquisition. These variabilities are assumed to cause a domain shift in the images of different hospitals. It is crucial to overcome this domain shift because an ideal machine-learning model must be able to work on the diverse sources of images, independent of the acquisition center. A domain generalization technique is leveraged in this study to improve the generalization capability of a Deep Neural Network (DNN), to an unseen histopathology image set (i.e., from an unseen hospital/trial site) in the presence of domain shift. According to experimental results, the conventional supervised-learning regime generalizes poorly to data collected from different hospitals. However, the proposed hospital-agnostic learning can improve the generalization considering the low-dimensional latent space representation visualization, and classification accuracy results.
Pay Attention with Focus: A Novel Learning Scheme for Classification of Whole Slide Images
Jun 11, 2021

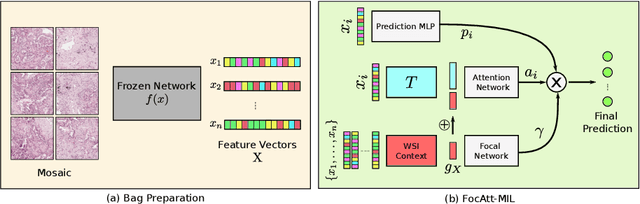
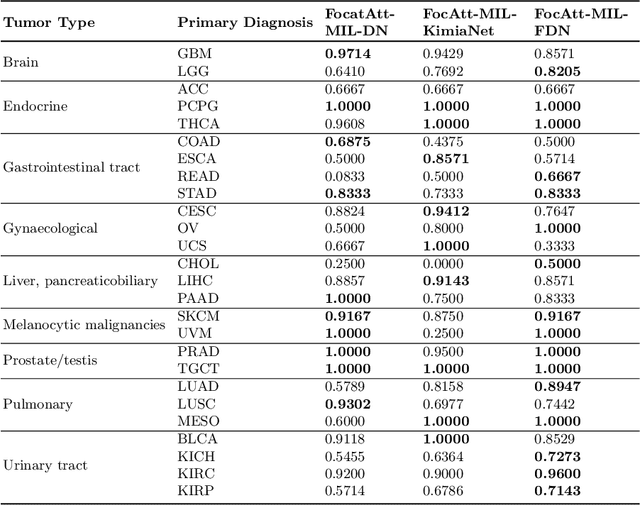
Deep learning methods such as convolutional neural networks (CNNs) are difficult to directly utilize to analyze whole slide images (WSIs) due to the large image dimensions. We overcome this limitation by proposing a novel two-stage approach. First, we extract a set of representative patches (called mosaic) from a WSI. Each patch of a mosaic is encoded to a feature vector using a deep network. The feature extractor model is fine-tuned using hierarchical target labels of WSIs, i.e., anatomic site and primary diagnosis. In the second stage, a set of encoded patch-level features from a WSI is used to compute the primary diagnosis probability through the proposed Pay Attention with Focus scheme, an attention-weighted averaging of predicted probabilities for all patches of a mosaic modulated by a trainable focal factor. Experimental results show that the proposed model can be robust, and effective for the classification of WSIs.
Forming Local Intersections of Projections for Classifying and Searching Histopathology Images
Aug 08, 2020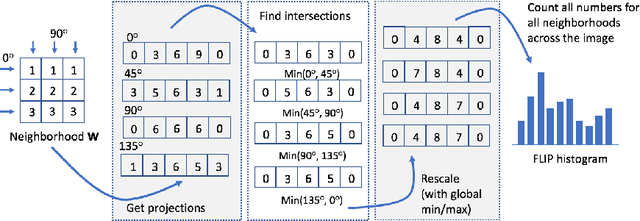
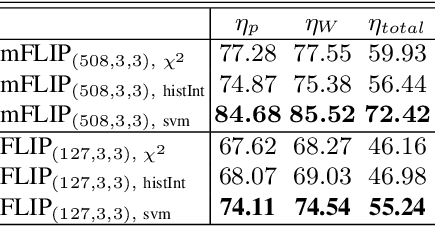


In this paper, we propose a novel image descriptor called Forming Local Intersections of Projections (FLIP) and its multi-resolution version (mFLIP) for representing histopathology images. The descriptor is based on the Radon transform wherein we apply parallel projections in small local neighborhoods of gray-level images. Using equidistant projection directions in each window, we extract unique and invariant characteristics of the neighborhood by taking the intersection of adjacent projections. Thereafter, we construct a histogram for each image, which we call the FLIP histogram. Various resolutions provide different FLIP histograms which are then concatenated to form the mFLIP descriptor. Our experiments included training common networks from scratch and fine-tuning pre-trained networks to benchmark our proposed descriptor. Experiments are conducted on the publicly available dataset KIMIA Path24 and KIMIA Path960. For both of these datasets, FLIP and mFLIP descriptors show promising results in all experiments.Using KIMIA Path24 data, FLIP outperformed non-fine-tuned Inception-v3 and fine-tuned VGG16 and mFLIP outperformed fine-tuned Inception-v3 in feature extracting.
Image-Based Benchmarking and Visualization for Large-Scale Global Optimization
Jul 24, 2020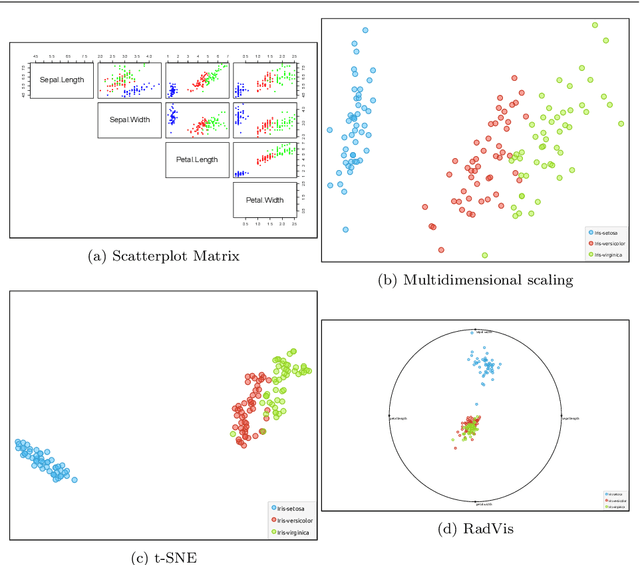
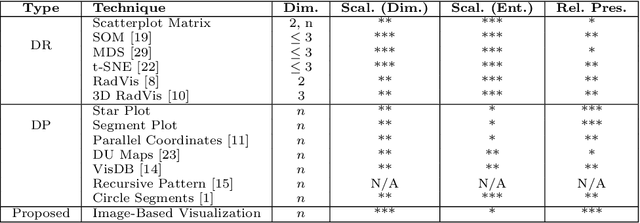
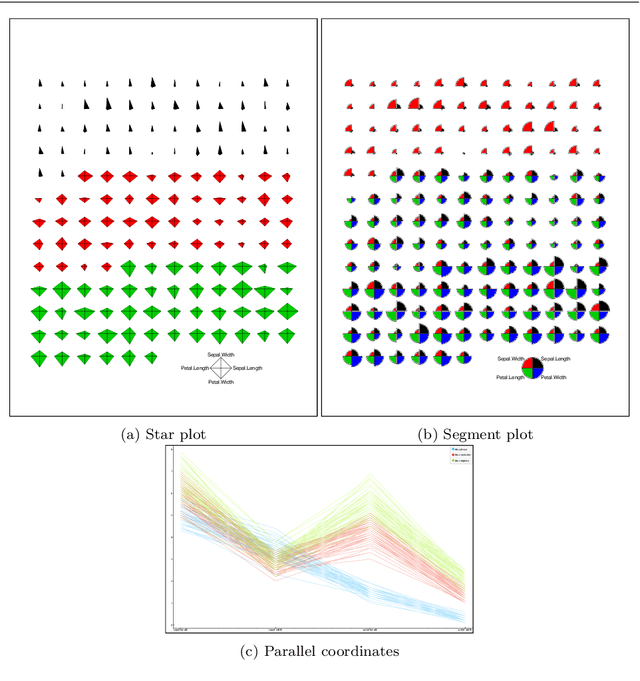

In the context of optimization, visualization techniques can be useful for understanding the behaviour of optimization algorithms and can even provide a means to facilitate human interaction with an optimizer. Towards this goal, an image-based visualization framework, without dimension reduction, that visualizes the solutions to large-scale global optimization problems as images is proposed. In the proposed framework, the pixels visualize decision variables while the entire image represents the overall solution quality. This framework affords a number of benefits over existing visualization techniques including enhanced scalability (in terms of the number of decision variables), facilitation of standard image processing techniques, providing nearly infinite benchmark cases, and explicit alignment with human perception. Furthermore, image-based visualization can be used to visualize the optimization process in real-time, thereby allowing the user to ascertain characteristics of the search process as it is progressing. To the best of the authors' knowledge, this is the first realization of a dimension-preserving, scalable visualization framework that embeds the inherent relationship between decision space and objective space. The proposed framework is utilized with 10 different mapping schemes on an image-reconstruction problem that encompass continuous, discrete, binary, combinatorial, constrained, dynamic, and multi-objective optimization. The proposed framework is then demonstrated on arbitrary benchmark problems with known optima. Experimental results elucidate the flexibility and demonstrate how valuable information about the search process can be gathered via the proposed visualization framework.
Multi-objective Optimal Control of Dynamic Integrated Model of Climate and Economy: Evolution in Action
Jun 29, 2020
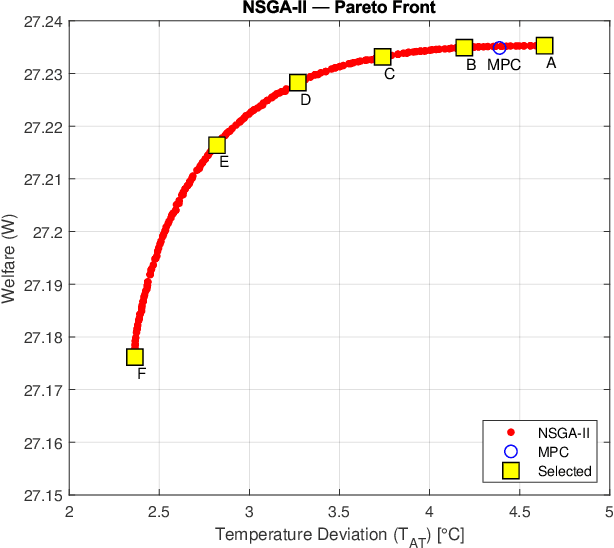
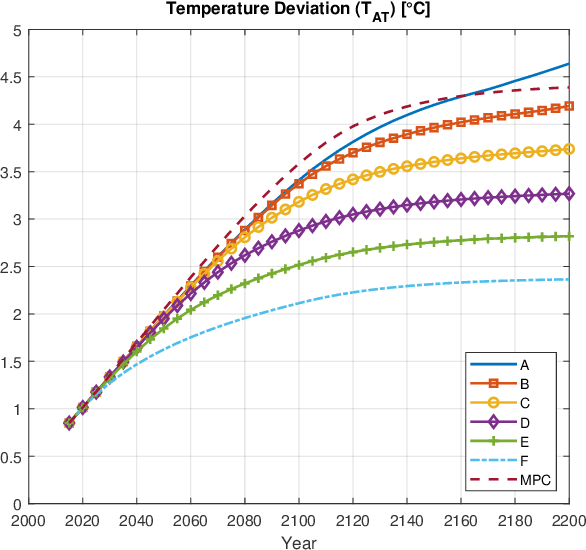
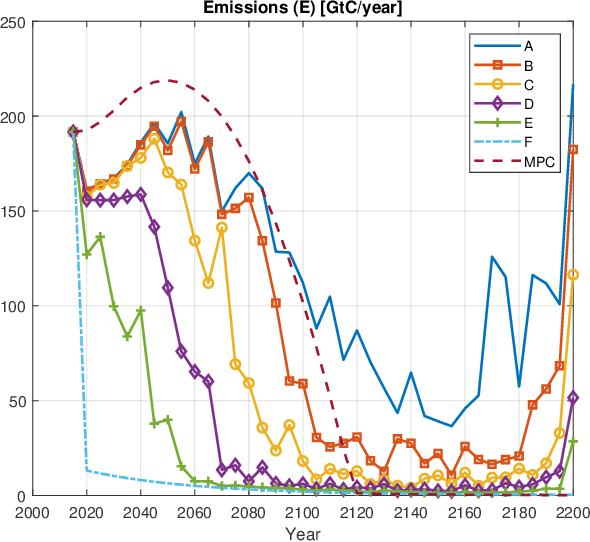
One of the widely used models for studying economics of climate change is the Dynamic Integrated model of Climate and Economy (DICE), which has been developed by Professor William Nordhaus, one of the laureates of the 2018 Nobel Memorial Prize in Economic Sciences. Originally a single-objective optimal control problem has been defined on DICE dynamics, which is aimed to maximize the social welfare. In this paper, a bi-objective optimal control problem defined on DICE model, objectives of which are maximizing social welfare and minimizing the temperature deviation of atmosphere. This multi-objective optimal control problem solved using Non-Dominated Sorting Genetic Algorithm II (NSGA-II) also it is compared to previous works on single-objective version of the problem. The resulting Pareto front rediscovers the previous results and generalizes to a wide range of non-dominant solutions to minimize the global temperature deviation while optimizing the economic welfare. The previously used single-objective approach is unable to create such a variety of possibilities, hence, its offered solution is limited in vision and reachable performance. Beside this, resulting Pareto-optimal set reveals the fact that temperature deviation cannot go below a certain lower limit, unless we have significant technology advancement or positive change in global conditions.
Shahryar Origami Optimization (SOO): A Novel Approach for Solving Large-scale Expensive Optimization Problems Efficiently
Mar 07, 2020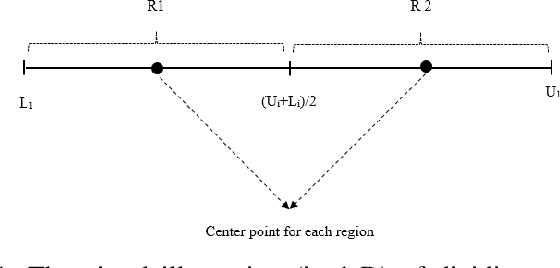
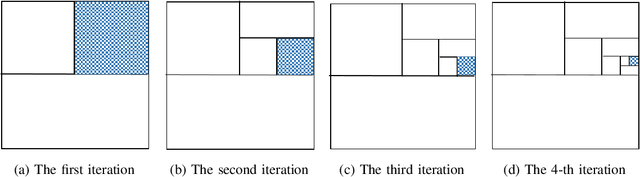
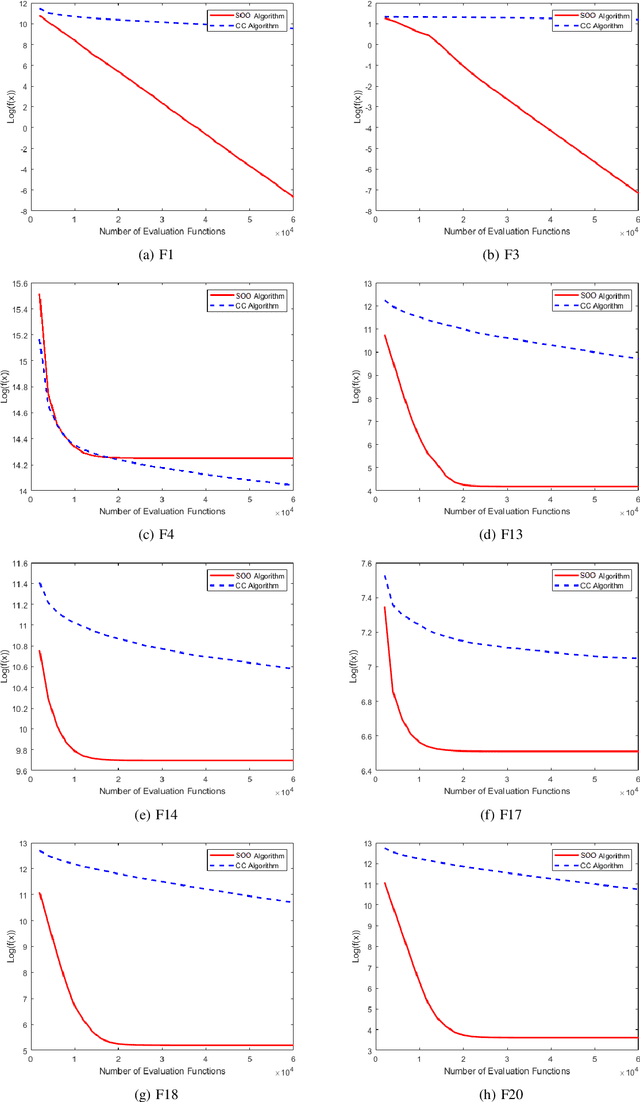
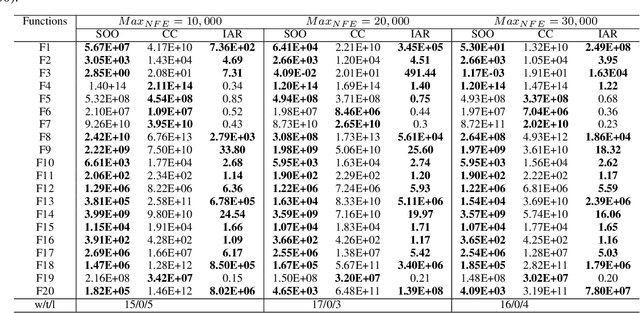
Many real-world problems are categorized as large-scale problems, and metaheuristic algorithms as an alternative method to solve large-scale problem; they need the evaluation of many candidate solutions to tackle them prior to their convergence, which is not affordable for practical applications since the most of them are computationally expensive. In other words, these problems are not only large-scale but also computationally expensive, that makes them very difficult to solve. There is no efficient surrogate model to support large-scale expensive global optimization (LSEGO) problems. As a result, the algorithms should address LSEGO problems using a limited computational budget to be applicable in real-world applications. In this paper, we propose a simple novel algorithm called Shahryar Origami Optimization (SOO) algorithm to tackle LSEGO problems with a limited computational budget. Our proposed algorithm benefits from two leading steps, namely, finding the region of interest and then shrinkage of the search space by folding it into the half with exponential speed. One of the main advantages of the proposed algorithm is being free of any control parameters, which makes it far from the intricacies of the tuning process. The proposed algorithm is compared with cooperative co-evolution with delta grouping on 20 benchmark functions with dimension 1000. Also, we conducted some experiments on CEC-2017, D=10, 30, 50, and 100 to investigate the behavior of SOO algorithm in lower dimensions. The results show that SOO is beneficial not only in large-scale problems, but also in low-scale optimization problems.
Learning Autoencoded Radon Projections
Sep 27, 2017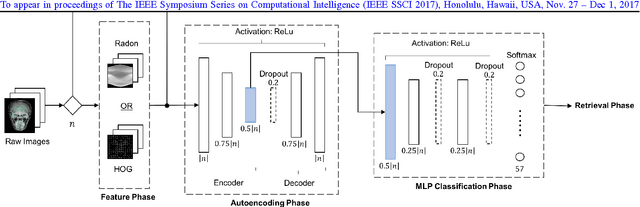
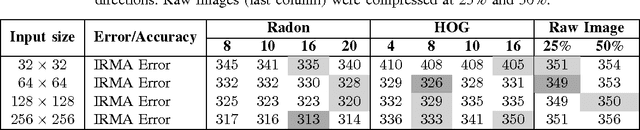
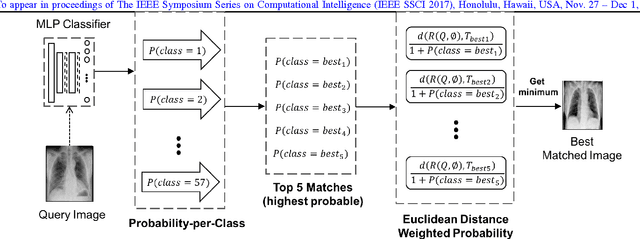
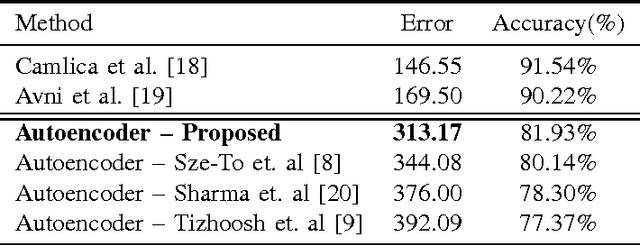
Autoencoders have been recently used for encoding medical images. In this study, we design and validate a new framework for retrieving medical images by classifying Radon projections, compressed in the deepest layer of an autoencoder. As the autoencoder reduces the dimensionality, a multilayer perceptron (MLP) can be employed to classify the images. The integration of MLP promotes a rather shallow learning architecture which makes the training faster. We conducted a comparative study to examine the capabilities of autoencoders for different inputs such as raw images, Histogram of Oriented Gradients (HOG) and normalized Radon projections. Our framework is benchmarked on IRMA dataset containing $14,410$ x-ray images distributed across $57$ different classes. Experiments show an IRMA error of $313$ (equivalent to $\approx 82\%$ accuracy) outperforming state-of-the-art works on retrieval from IRMA dataset using autoencoders.
Opposition based Ensemble Micro Differential Evolution
Sep 21, 2017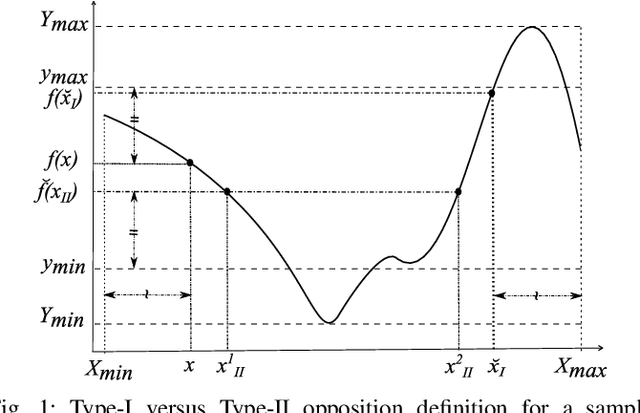
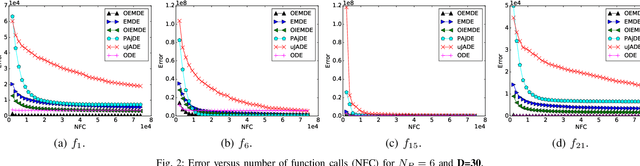
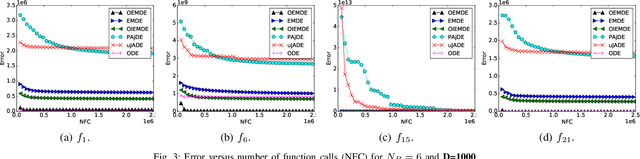
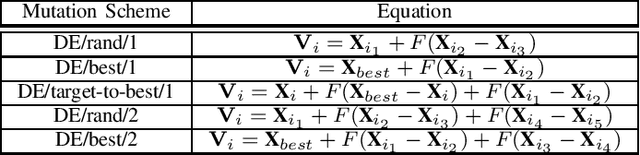
Differential evolution (DE) algorithm with a small population size is called Micro-DE (MDE). A small population size decreases the computational complexity but also reduces the exploration ability of DE by limiting the population diversity. In this paper, we propose the idea of combining ensemble mutation scheme selection and opposition-based learning concepts to enhance the diversity of population in MDE at mutation and selection stages. The proposed algorithm enhances the diversity of population by generating a random mutation scale factor per individual and per dimension, randomly assigning a mutation scheme to each individual in each generation, and diversifying individuals selection using opposition-based learning. This approach is easy to implement and does not require the setting of mutation scheme selection and mutation scale factor. Experimental results are conducted for a variety of objective functions with low and high dimensionality on the CEC Black- Box Optimization Benchmarking 2015 (CEC-BBOB 2015). The results show superior performance of the proposed algorithm compared to the other micro-DE algorithms.