 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntercepting the Future: Latent-Space Predictive World Model for Dynamic VLA Manipulation
Jun 01, 2026Vision-Language-Action (VLA) models generalize across static manipulation but fail when objects move during task execution. They map the current observation to an action and assume the scene is stationary between observation and execution, so at any non-trivial object speed the resulting latency exceeds the time available to grasp. We close this gap with AHEAD (Anticipatory Horizon Extrapolation with Adaptive Dynamics), a predict-then-act wrapper that augments a frozen VLA with a motion-aware latent world model. A small world model trained on manipulation video forecasts future patch tokens in the VLA's feature space, conditioned on per-token velocity and acceleration from optical flow. A language-and-motion saliency mask concentrates prediction on task-relevant patches, and the model rolls forward for an adaptive horizon, halting when prediction uncertainty crosses a threshold. The frozen action decoder then receives the predicted future tokens in place of the current ones. AHEAD adds 4.9M parameters to a frozen 7B OpenVLA and reaches 79 to 97% success across 20 dynamic simulation scenarios where the strongest baseline reaches 31 to 58%. On a physical UFactory xArm 7, AHEAD succeeds on 29/30 to 30/30 on three conveyor and rolling-ball tasks, 23/30 on paddle interception, and 19/30 on projectile catching where every baseline scores 0/30.
Joint Learning of Depth, Pose, and Local Radiance Field for Large Scale Monocular 3D Reconstruction
Dec 20, 2025Photorealistic 3-D reconstruction from monocular video collapses in large-scale scenes when depth, pose, and radiance are solved in isolation: scale-ambiguous depth yields ghost geometry, long-horizon pose drift corrupts alignment, and a single global NeRF cannot model hundreds of metres of content. We introduce a joint learning framework that couples all three factors and demonstrably overcomes each failure case. Our system begins with a Vision-Transformer (ViT) depth network trained with metric-scale supervision, giving globally consistent depths despite wide field-of-view variations. A multi-scale feature bundle-adjustment (BA) layer refines camera poses directly in feature space--leveraging learned pyramidal descriptors instead of brittle keypoints--to suppress drift on unconstrained trajectories. For scene representation, we deploy an incremental local-radiance-field hierarchy: new hash-grid NeRFs are allocated and frozen on-the-fly when view overlap falls below a threshold, enabling city-block-scale coverage on a single GPU. Evaluated on the Tanks and Temples benchmark, our method reduces Absolute Trajectory Error to 0.001-0.021 m across eight indoor-outdoor sequences--up to 18x lower than BARF and 2x lower than NoPe-NeRF--while maintaining sub-pixel Relative Pose Error. These results demonstrate that metric-scale, drift-free 3-D reconstruction and high-fidelity novel-view synthesis are achievable from a single uncalibrated RGB camera.
ExpReS-VLA: Specializing Vision-Language-Action Models Through Experience Replay and Retrieval
Nov 09, 2025



Vision-Language-Action models such as OpenVLA show impressive zero-shot generalization across robotic manipulation tasks but often fail to adapt efficiently to new deployment environments. In many real-world applications, consistent high performance on a limited set of tasks is more important than broad generalization. We propose ExpReS-VLA, a method for specializing pre-trained VLA models through experience replay and retrieval while preventing catastrophic forgetting. ExpReS-VLA stores compact feature representations from the frozen vision backbone instead of raw image-action pairs, reducing memory usage by approximately 97 percent. During deployment, relevant past experiences are retrieved using cosine similarity and used to guide adaptation, while prioritized experience replay emphasizes successful trajectories. We also introduce Thresholded Hybrid Contrastive Loss, which enables learning from both successful and failed attempts. On the LIBERO simulation benchmark, ExpReS-VLA improves success rates from 82.6 to 93.1 percent on spatial reasoning tasks and from 61 to 72.3 percent on long-horizon tasks. On physical robot experiments with five manipulation tasks, it reaches 98 percent success on both seen and unseen settings, compared to 84.7 and 32 percent for naive fine-tuning. Adaptation takes 31 seconds using 12 demonstrations on a single RTX 5090 GPU, making the approach practical for real robot deployment.
SuperPoint-SLAM3: Augmenting ORB-SLAM3 with Deep Features, Adaptive NMS, and Learning-Based Loop Closure
Jun 16, 2025Visual simultaneous localization and mapping (SLAM) must remain accurate under extreme viewpoint, scale and illumination variations. The widely adopted ORB-SLAM3 falters in these regimes because it relies on hand-crafted ORB keypoints. We introduce SuperPoint-SLAM3, a drop-in upgrade that (i) replaces ORB with the self-supervised SuperPoint detector--descriptor, (ii) enforces spatially uniform keypoints via adaptive non-maximal suppression (ANMS), and (iii) integrates a lightweight NetVLAD place-recognition head for learning-based loop closure. On the KITTI Odometry benchmark SuperPoint-SLAM3 reduces mean translational error from 4.15% to 0.34% and mean rotational error from 0.0027 deg/m to 0.0010 deg/m. On the EuRoC MAV dataset it roughly halves both errors across every sequence (e.g., V2\_03: 1.58% -> 0.79%). These gains confirm that fusing modern deep features with a learned loop-closure module markedly improves ORB-SLAM3 accuracy while preserving its real-time operation. Implementation, pretrained weights and reproducibility scripts are available at https://github.com/shahram95/SuperPointSLAM3.
Learning by Aligning Videos in Time
Mar 31, 2021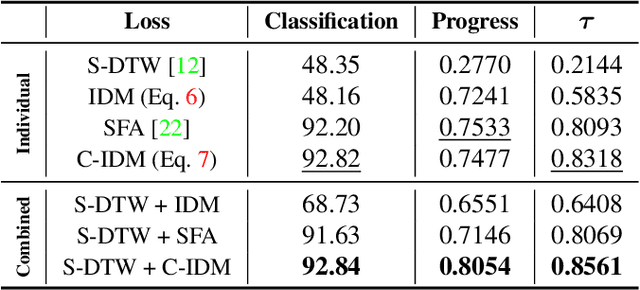
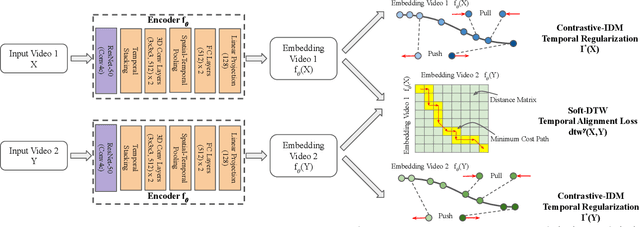
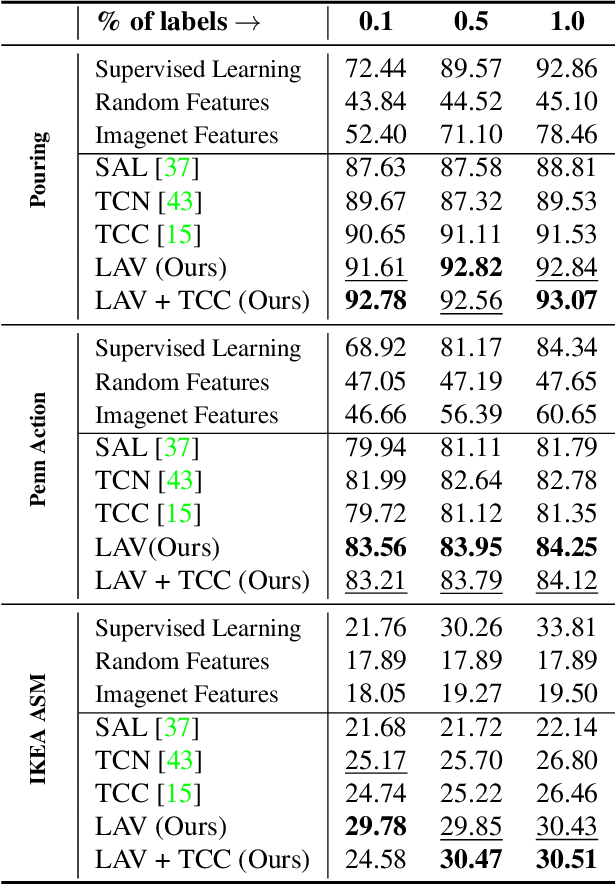
We present a self-supervised approach for learning video representations using temporal video alignment as a pretext task, while exploiting both frame-level and video-level information. We leverage a novel combination of temporal alignment loss and temporal regularization terms, which can be used as supervision signals for training an encoder network. Specifically, the temporal alignment loss (i.e., Soft-DTW) aims for the minimum cost for temporally aligning videos in the embedding space. However, optimizing solely for this term leads to trivial solutions, particularly, one where all frames get mapped to a small cluster in the embedding space. To overcome this problem, we propose a temporal regularization term (i.e., Contrastive-IDM) which encourages different frames to be mapped to different points in the embedding space. Extensive evaluations on various tasks, including action phase classification, action phase progression, and fine-grained frame retrieval, on three datasets, namely Pouring, Penn Action, and IKEA ASM, show superior performance of our approach over state-of-the-art methods for self-supervised representation learning from videos. In addition, our method provides significant performance gain where labeled data is lacking.