 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Content Classification Approach for GitHub Repositories by the README Files
Jul 29, 2025
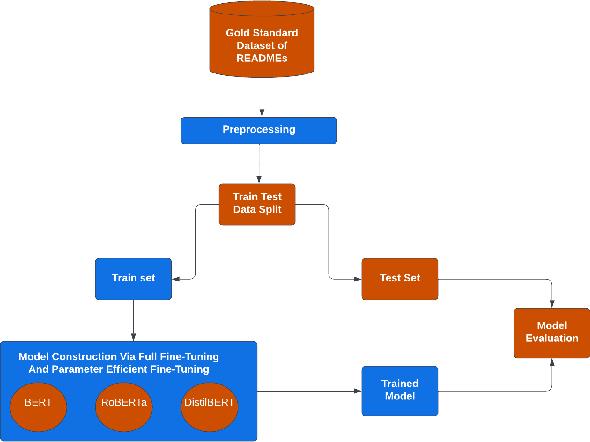
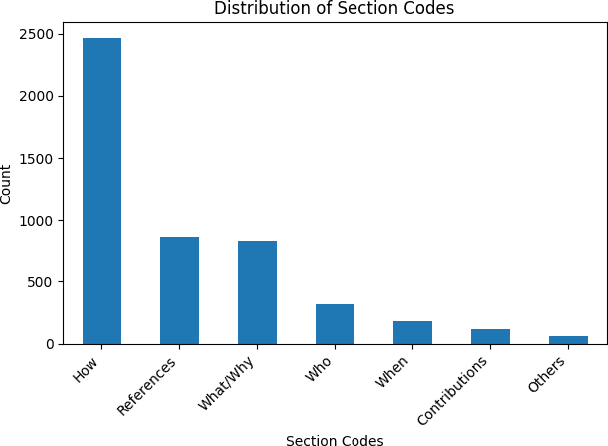

GitHub is the world's most popular platform for storing, sharing, and managing code. Every GitHub repository has a README file associated with it. The README files should contain project-related information as per the recommendations of GitHub to support the usage and improvement of repositories. However, GitHub repository owners sometimes neglected these recommendations. This prevents a GitHub repository from reaching its full potential. This research posits that the comprehensiveness of a GitHub repository's README file significantly influences its adoption and utilization, with a lack of detail potentially hindering its full potential for widespread engagement and impact within the research community. Large Language Models (LLMs) have shown great performance in many text-based tasks including text classification, text generation, text summarization and text translation. In this study, an approach is developed to fine-tune LLMs for automatically classifying different sections of GitHub README files. Three encoder-only LLMs are utilized, including BERT, DistilBERT and RoBERTa. These pre-trained models are then fine-tuned based on a gold-standard dataset consisting of 4226 README file sections. This approach outperforms current state-of-the-art methods and has achieved an overall F1 score of 0.98. Moreover, we have also investigated the use of Parameter-Efficient Fine-Tuning (PEFT) techniques like Low-Rank Adaptation (LoRA) and shown an economical alternative to full fine-tuning without compromising much performance. The results demonstrate the potential of using LLMs in designing an automatic classifier for categorizing the content of GitHub README files. Consequently, this study contributes to the development of automated tools for GitHub repositories to improve their identifications and potential usages.
Reducibility among NP-Hard graph problems and boundary classes
Nov 21, 2024Many NP-hard graph problems become easy for some classes of graphs, such as coloring is easy for bipartite graphs, but NP-hard in general. So we can ask question like when does a hard problem become easy? What is the minimum substructure for which the problem remains hard? We use the notion of boundary classes to study such questions. In this paper, we introduce a method for transforming the boundary class of one NP-hard graph problem into a boundary class for another problem. If $\Pi$ and $\Gamma$ are two NP-hard graph problems where $\Pi$ is reducible to $\Gamma$, we transform a boundary class of $\Pi$ into a boundary class of $\Gamma$. More formally if $\Pi$ is reducible to $\Gamma$, where the reduction is bijective and it maps hereditary classes of graphs to hereditary classes of graphs, then $X$ is a boundary class of $\Pi$ if and only if the image of $X$ under the reduction is a boundary class of $\Gamma$. This gives us a relationship between boundary classes and reducibility among several NP-hard problems. To show the strength of our main result, we apply our theorem to obtain some previously unknown boundary classes for a few graph problems namely; vertex-cover, clique, traveling-salesperson, bounded-degree-spanning-tree, subgraph-isomorphism and clique-cover.
Automatic Vehicle Checking Agent (VCA)
Dec 03, 2011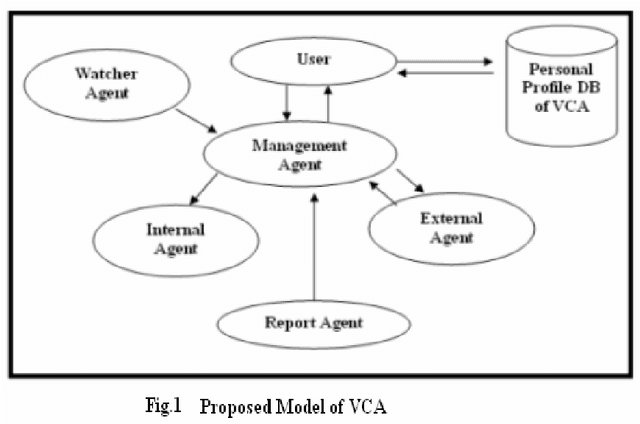
A definition of intelligence is given in terms of performance that can be quantitatively measured. In this study, we have presented a conceptual model of Intelligent Agent System for Automatic Vehicle Checking Agent (VCA). To achieve this goal, we have introduced several kinds of agents that exhibit intelligent features. These are the Management agent, internal agent, External Agent, Watcher agent and Report agent. Metrics and measurements are suggested for evaluating the performance of Automatic Vehicle Checking Agent (VCA). Calibrate data and test facilities are suggested to facilitate the development of intelligent systems.
* 5 pages, 2 figures