 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Regression Meets Manifold Learning for Object Recognition and Pose Estimation
May 16, 2018
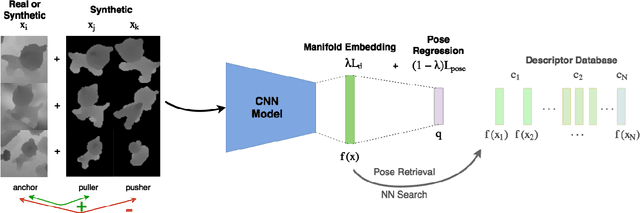
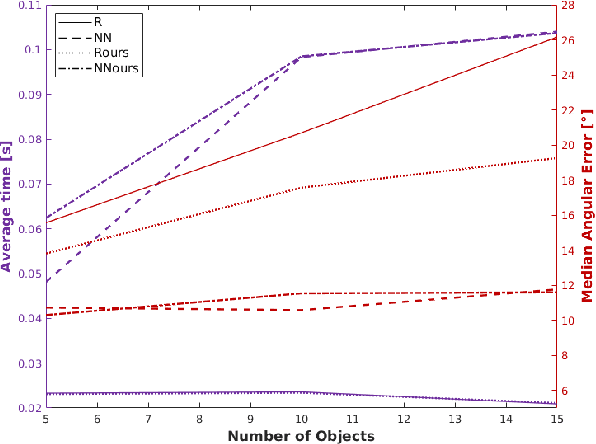
In this work, we propose a method for object recognition and pose estimation from depth images using convolutional neural networks. Previous methods addressing this problem rely on manifold learning to learn low dimensional viewpoint descriptors and employ them in a nearest neighbor search on an estimated descriptor space. In comparison we create an efficient multi-task learning framework combining manifold descriptor learning and pose regression. By combining the strengths of manifold learning using triplet loss and pose regression, we could either estimate the pose directly reducing the complexity compared to NN search, or use learned descriptor for the NN descriptor matching. By in depth experimental evaluation of the novel loss function we observed that the view descriptors learned by the network are much more discriminative resulting in almost 30% increase regarding relative pose accuracy compared to related works. On the other hand, regarding directly regressed poses we obtained important improvement compared to simple pose regression. By leveraging the advantages of both manifold learning and regression tasks, we are able to improve the current state-of-the-art for object recognition and pose retrieval that we demonstrate through in depth experimental evaluation.
Multi Layered-Parallel Graph Convolutional Network (ML-PGCN) for Disease Prediction
Apr 28, 2018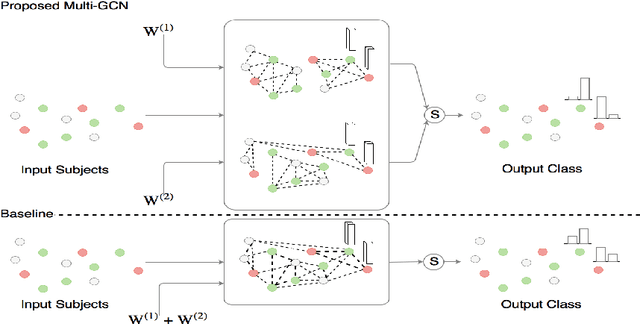
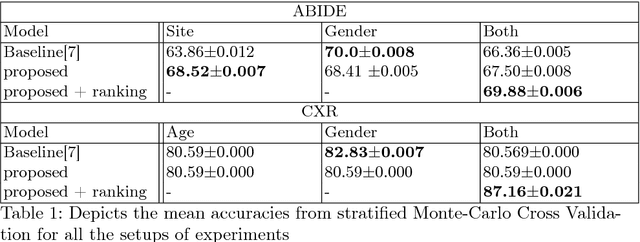
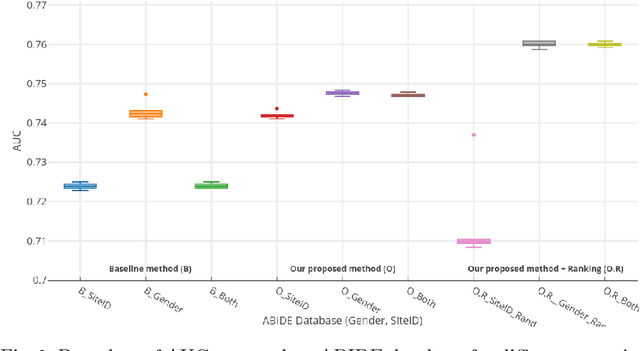
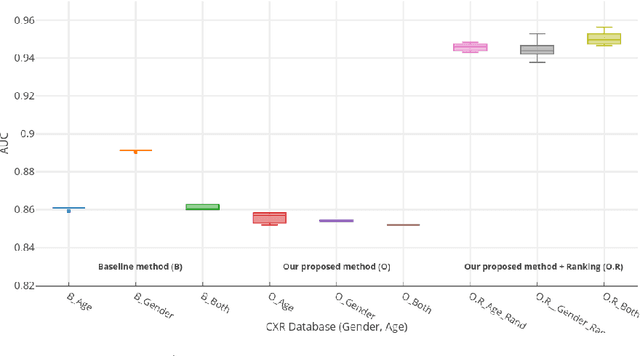
Structural data from Electronic Health Records as complementary information to imaging data for disease prediction. We incorporate novel weighting layer into the Graph Convolutional Networks, which weights every element of structural data by exploring its relation to the underlying disease. We demonstrate the superiority of our developed technique in terms of computational speed and obtained encouraging results where our method outperforms the state-of-the-art methods when applied to two publicly available datasets ABIDE and Chest X-ray in terms of relative performance for the accuracy of prediction by 5.31 % and 8.15 % and for the area under the ROC curve by 4.96 % and 10.36 % respectively. Additionally, the model is lightweight, fast and easily trainable.
Domain and Geometry Agnostic CNNs for Left Atrium Segmentation in 3D Ultrasound
Apr 20, 2018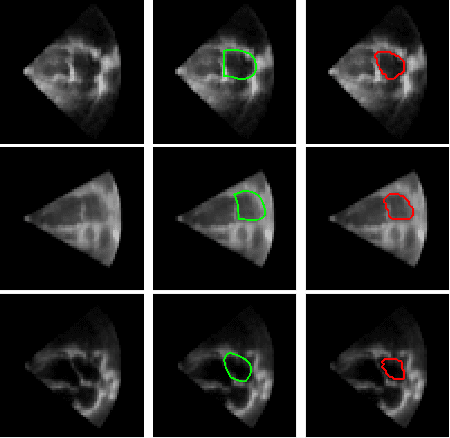

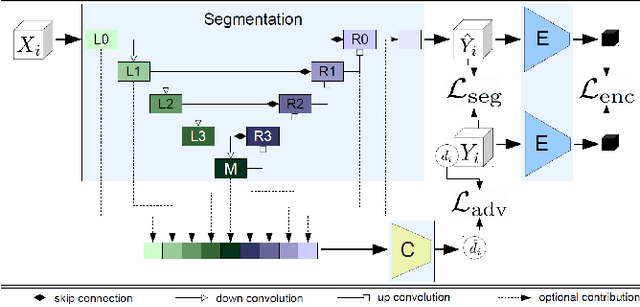
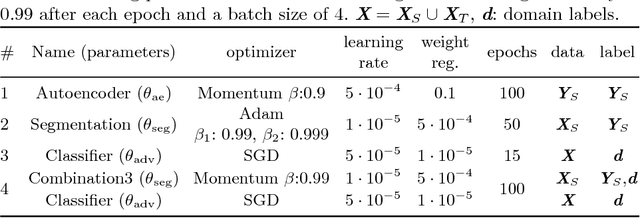
Segmentation of the left atrium and deriving its size can help to predict and detect various cardiovascular conditions. Automation of this process in 3D Ultrasound image data is desirable, since manual delineations are time-consuming, challenging and observer-dependent. Convolutional neural networks have made improvements in computer vision and in medical image analysis. They have successfully been applied to segmentation tasks and were extended to work on volumetric data. In this paper we introduce a combined deep-learning based approach on volumetric segmentation in Ultrasound acquisitions with incorporation of prior knowledge about left atrial shape and imaging device. The results show, that including a shape prior helps the domain adaptation and the accuracy of segmentation is further increased with adversarial learning.
Deep Autoencoding Models for Unsupervised Anomaly Segmentation in Brain MR Images
Apr 12, 2018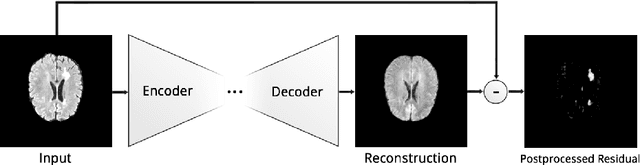
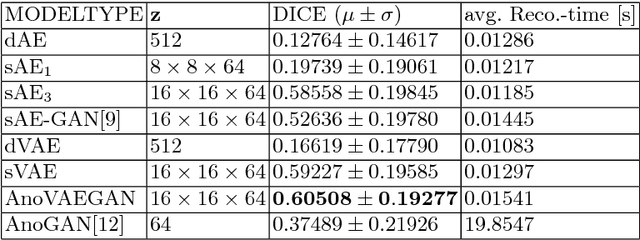

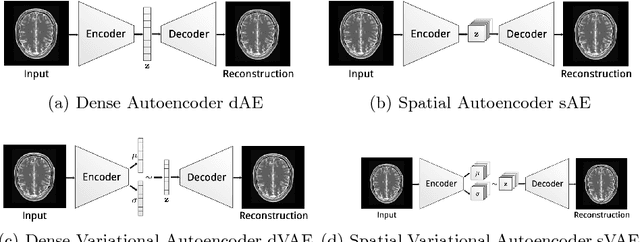
Reliably modeling normality and differentiating abnormal appearances from normal cases is a very appealing approach for detecting pathologies in medical images. A plethora of such unsupervised anomaly detection approaches has been made in the medical domain, based on statistical methods, content-based retrieval, clustering and recently also deep learning. Previous approaches towards deep unsupervised anomaly detection model patches of normal anatomy with variants of Autoencoders or GANs, and detect anomalies either as outliers in the learned feature space or from large reconstruction errors. In contrast to these patch-based approaches, we show that deep spatial autoencoding models can be efficiently used to capture normal anatomical variability of entire 2D brain MR images. A variety of experiments on real MR data containing MS lesions corroborates our hypothesis that we can detect and even delineate anomalies in brain MR images by simply comparing input images to their reconstruction. Results show that constraints on the latent space and adversarial training can further improve the segmentation performance over standard deep representation learning.
MelanoGANs: High Resolution Skin Lesion Synthesis with GANs
Apr 12, 2018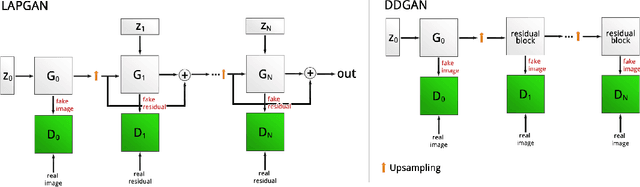
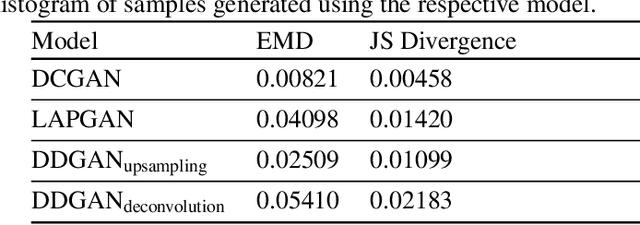
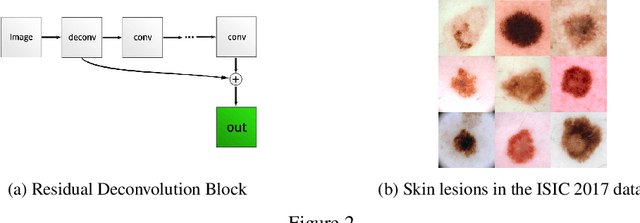

Generative Adversarial Networks (GANs) have been successfully used to synthesize realistically looking images of faces, scenery and even medical images. Unfortunately, they usually require large training datasets, which are often scarce in the medical field, and to the best of our knowledge GANs have been only applied for medical image synthesis at fairly low resolution. However, many state-of-the-art machine learning models operate on high resolution data as such data carries indispensable, valuable information. In this work, we try to generate realistically looking high resolution images of skin lesions with GANs, using only a small training dataset of 2000 samples. The nature of the data allows us to do a direct comparison between the image statistics of the generated samples and the real dataset. We both quantitatively and qualitatively compare state-of-the-art GAN architectures such as DCGAN and LAPGAN against a modification of the latter for the task of image generation at a resolution of 256x256px. Our investigation shows that we can approximate the real data distribution with all of the models, but we notice major differences when visually rating sample realism, diversity and artifacts. In a set of use-case experiments on skin lesion classification, we further show that we can successfully tackle the problem of heavy class imbalance with the help of synthesized high resolution melanoma samples.
StainGAN: Stain Style Transfer for Digital Histological Images
Apr 04, 2018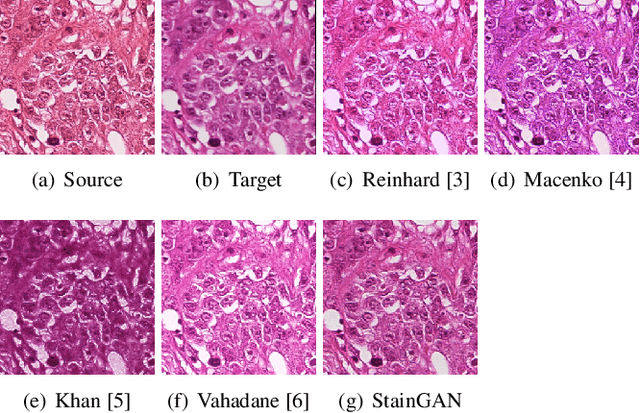

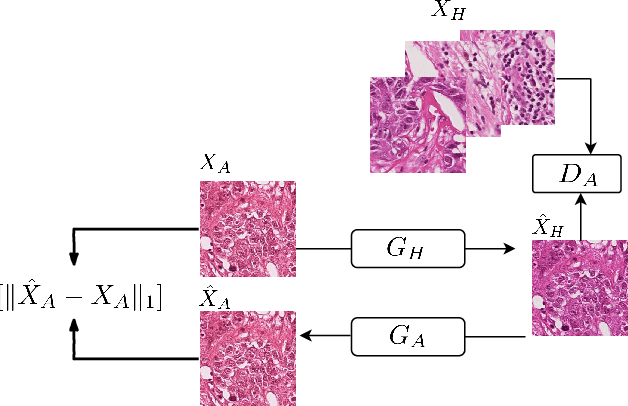
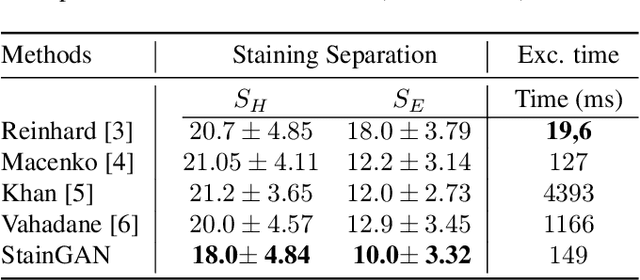
Digitized Histological diagnosis is in increasing demand. However, color variations due to various factors are imposing obstacles to the diagnosis process. The problem of stain color variations is a well-defined problem with many proposed solutions. Most of these solutions are highly dependent on a reference template slide. We propose a deep-learning solution inspired by CycleGANs that is trained end-to-end, eliminating the need for an expert to pick a representative reference slide. Our approach showed superior results quantitatively and qualitatively against the state of the art methods (10% improvement visually using SSIM). We further validated our method on a clinical use-case, namely Breast Cancer tumor classification, showing 12% increase in AUC. The code will be made publicly available.
Semi-Supervised Deep Learning for Fully Convolutional Networks
Jul 25, 2017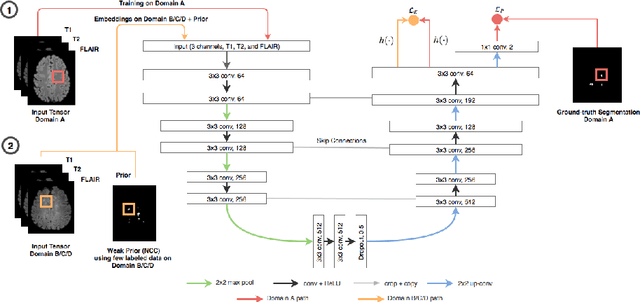

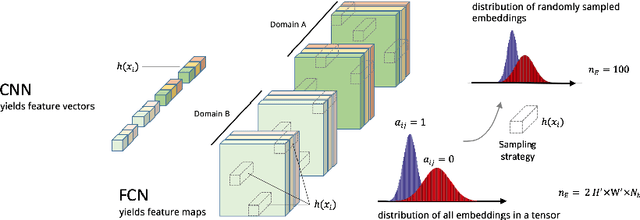
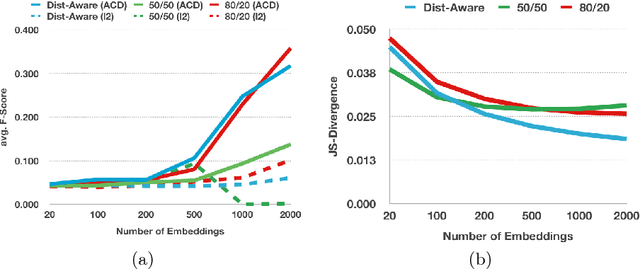
Deep learning usually requires large amounts of labeled training data, but annotating data is costly and tedious. The framework of semi-supervised learning provides the means to use both labeled data and arbitrary amounts of unlabeled data for training. Recently, semi-supervised deep learning has been intensively studied for standard CNN architectures. However, Fully Convolutional Networks (FCNs) set the state-of-the-art for many image segmentation tasks. To the best of our knowledge, there is no existing semi-supervised learning method for such FCNs yet. We lift the concept of auxiliary manifold embedding for semi-supervised learning to FCNs with the help of Random Feature Embedding. In our experiments on the challenging task of MS Lesion Segmentation, we leverage the proposed framework for the purpose of domain adaptation and report substantial improvements over the baseline model.
X-ray In-Depth Decomposition: Revealing The Latent Structures
Mar 22, 2017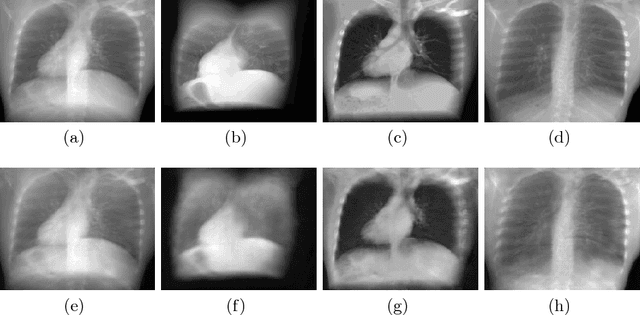
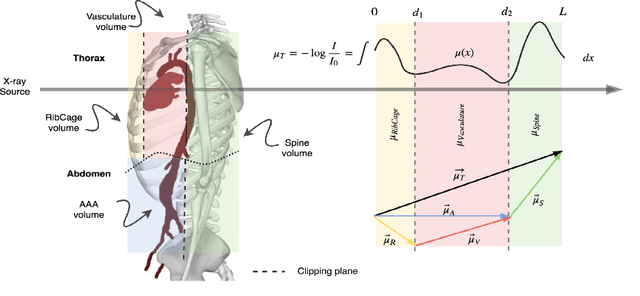
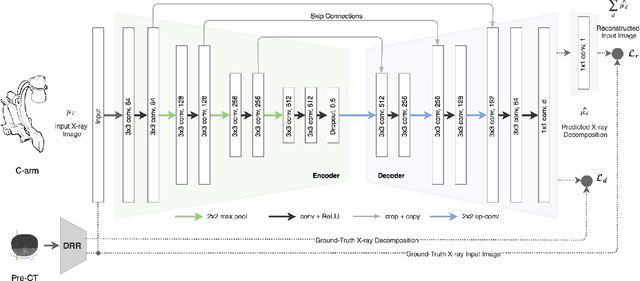
X-ray radiography is the most readily available imaging modality and has a broad range of applications that spans from diagnosis to intra-operative guidance in cardiac, orthopedics, and trauma procedures. Proper interpretation of the hidden and obscured anatomy in X-ray images remains a challenge and often requires high radiation dose and imaging from several perspectives. In this work, we aim at decomposing the conventional X-ray image into d X-ray components of independent, non-overlapped, clipped sub-volumes using deep learning approach. Despite the challenging aspects of modeling such a highly ill-posed problem, exciting and encouraging results are obtained paving the path for further contributions in this direction.