 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWristMIR: Coarse-to-Fine Region-Aware Retrieval of Pediatric Wrist Radiographs with Radiology Report-Driven Learning
Feb 08, 2026Retrieving wrist radiographs with analogous fracture patterns is challenging because clinically important cues are subtle, highly localized and often obscured by overlapping anatomy or variable imaging views. Progress is further limited by the scarcity of large, well-annotated datasets for case-based medical image retrieval. We introduce WristMIR, a region-aware pediatric wrist radiograph retrieval framework that leverages dense radiology reports and bone-specific localization to learn fine-grained, clinically meaningful image representations without any manual image-level annotations. Using MedGemma-based structured report mining to generate both global and region-level captions, together with pre-processed wrist images and bone-specific crops of the distal radius, distal ulna, and ulnar styloid, WristMIR jointly trains global and local contrastive encoders and performs a two-stage retrieval process: (1) coarse global matching to identify candidate exams, followed by (2) region-conditioned reranking aligned to a predefined anatomical bone region. WristMIR improves retrieval performance over strong vision-language baselines, raising image-to-text Recall@5 from 0.82% to 9.35%. Its embeddings also yield stronger fracture classification (AUROC 0.949, AUPRC 0.953). In region-aware evaluation, the two-stage design markedly improves retrieval-based fracture diagnosis, increasing mean $F_1$ from 0.568 to 0.753, and radiologists rate its retrieved cases as more clinically relevant, with mean scores rising from 3.36 to 4.35. These findings highlight the potential of anatomically guided retrieval to enhance diagnostic reasoning and support clinical decision-making in pediatric musculoskeletal imaging. The source code is publicly available at https://github.com/quin-med-harvard-edu/WristMIR.
CANet: ChronoAdaptive Network for Enhanced Long-Term Time Series Forecasting under Non-Stationarity
Apr 24, 2025Long-term time series forecasting plays a pivotal role in various real-world applications. Despite recent advancements and the success of different architectures, forecasting is often challenging due to non-stationary nature of the real-world data, which frequently exhibit distribution shifts and temporal changes in statistical properties like mean and variance over time. Previous studies suggest that this inherent variability complicates forecasting, limiting the performance of many models by leading to loss of non-stationarity and resulting in over-stationarization (Liu, Wu, Wang and Long, 2022). To address this challenge, we introduce a novel architecture, ChoronoAdaptive Network (CANet), inspired by style-transfer techniques. The core of CANet is the Non-stationary Adaptive Normalization module, seamlessly integrating the Style Blending Gate and Adaptive Instance Normalization (AdaIN) (Huang and Belongie, 2017). The Style Blending Gate preserves and reintegrates non-stationary characteristics, such as mean and standard deviation, by blending internal and external statistics, preventing over-stationarization while maintaining essential temporal dependencies. Coupled with AdaIN, which dynamically adapts the model to statistical changes, this approach enhances predictive accuracy under non-stationary conditions. CANet also employs multi-resolution patching to handle short-term fluctuations and long-term trends, along with Fourier analysis-based adaptive thresholding to reduce noise. A Stacked Kronecker Product Layer further optimizes the model's efficiency while maintaining high performance. Extensive experiments on real-world datasets validate CANet's superiority over state-of-the-art methods, achieving a 42% reduction in MSE and a 22% reduction in MAE. The source code is publicly available at https://github.com/mertsonmezer/CANet.
Learning to Predict the Wisdom of Crowds
Apr 16, 2012

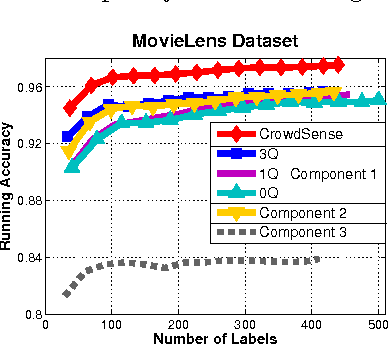
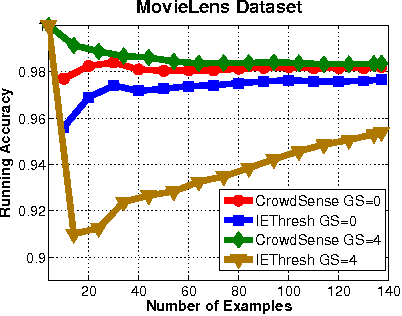
The problem of "approximating the crowd" is that of estimating the crowd's majority opinion by querying only a subset of it. Algorithms that approximate the crowd can intelligently stretch a limited budget for a crowdsourcing task. We present an algorithm, "CrowdSense," that works in an online fashion to dynamically sample subsets of labelers based on an exploration/exploitation criterion. The algorithm produces a weighted combination of a subset of the labelers' votes that approximates the crowd's opinion.