 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualLVLM-Agent: A Holistic Framework for Multi-Turn Visually-Grounded Dialogue and Complex Instruction Following
Aug 21, 2025Despite significant advancements in Large Language Models (LLMs) and Large Vision-Language Models (LVLMs), current models still face substantial challenges in handling complex, multi-turn, and visually-grounded tasks that demand deep reasoning, sustained contextual understanding, entity tracking, and multi-step instruction following. Existing benchmarks often fall short in capturing the dynamism and intricacies of real-world multi-modal interactions, leading to issues such as context loss and visual hallucinations. To address these limitations, we introduce MMDR-Bench (Multi-Modal Dialogue Reasoning Benchmark), a novel dataset comprising 300 meticulously designed complex multi-turn dialogue scenarios, each averaging 5-7 turns and evaluated across six core dimensions including visual entity tracking and reasoning depth. Furthermore, we propose CoLVLM Agent (Contextual LVLM Agent), a holistic framework that enhances existing LVLMs with advanced reasoning and instruction following capabilities through an iterative "memory-perception-planning-execution" cycle, requiring no extensive re-training of the underlying models. Our extensive experiments on MMDR-Bench demonstrate that CoLVLM Agent consistently achieves superior performance, attaining an average human evaluation score of 4.03, notably surpassing state-of-the-art commercial models like GPT-4o (3.92) and Gemini 1.5 Pro (3.85). The framework exhibits significant advantages in reasoning depth, instruction adherence, and error suppression, and maintains robust performance over extended dialogue turns, validating the effectiveness of its modular design and iterative approach for complex multi-modal interactions.
Robust Full-FoV Depth Estimation in Tele-wide Camera System
Oct 18, 2019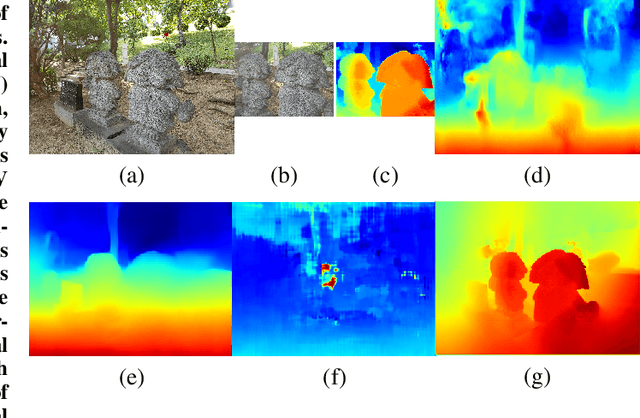
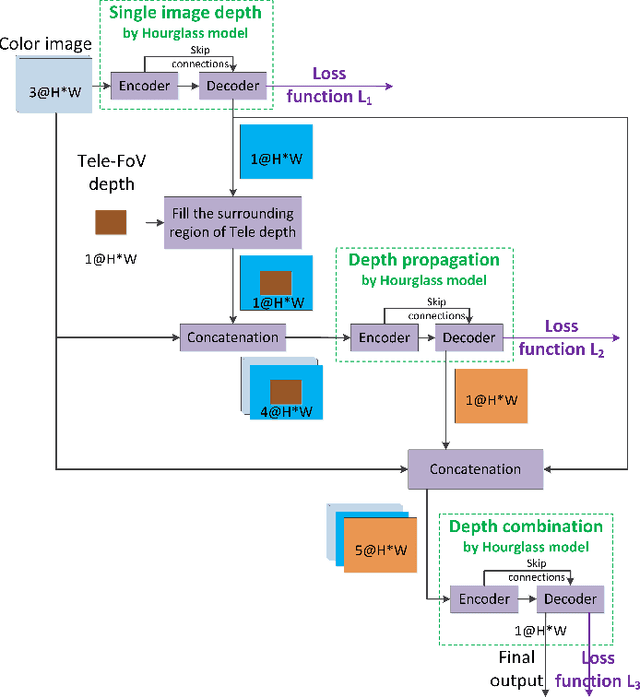
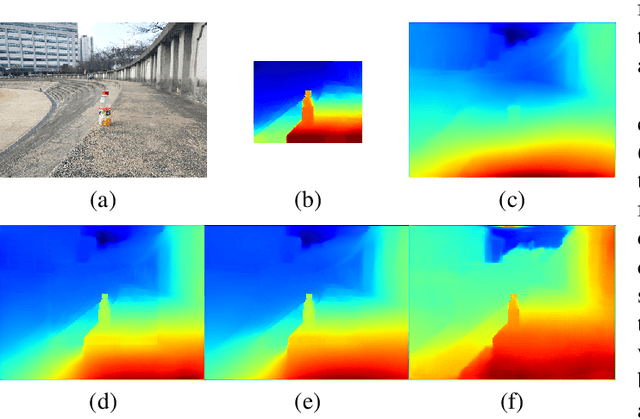
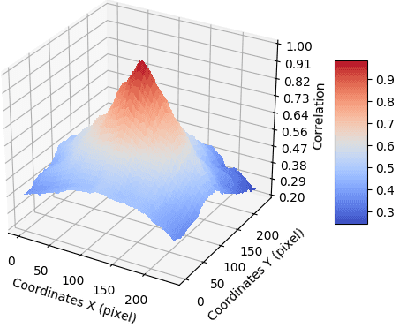
Tele-wide camera system with different Field of View (FoV) lenses becomes very popular in recent mobile devices. Usually it is difficult to obtain full-FoV depth based on traditional stereo-matching methods. Pure Deep Neural Network (DNN) based depth estimation methods can obtain full-FoV depth, but have low robustness for scenarios which are not covered by training dataset. In this paper, to address the above problems we propose a hierarchical hourglass network for robust full-FoV depth estimation in tele-wide camera system, which combines the robustness of traditional stereo-matching methods with the accuracy of DNN. More specifically, the proposed network comprises three major modules: single image depth prediction module infers initial depth from input color image, depth propagation module propagates traditional stereo-matching tele-FoV depth to surrounding regions, and depth combination module fuses the initial depth with the propagated depth to generate final output. Each of these modules employs an hourglass model, which is a kind of encoder-decoder structure with skip connections. Experimental results compared with state-of-the-art depth estimation methods demonstrate that our method not only produces robust and better subjective depth quality on wild test images, but also obtains better quantitative results on standard datasets.