 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat hackers talk about when they talk about AI: Early-stage diffusion of a cybercrime innovation
Feb 16, 2026The rapid expansion of artificial intelligence (AI) is raising concerns about its potential to transform cybercrime. Beyond empowering novice offenders, AI stands to intensify the scale and sophistication of attacks by seasoned cybercriminals. This paper examines the evolving relationship between cybercriminals and AI using a unique dataset from a cyber threat intelligence platform. Analyzing more than 160 cybercrime forum conversations collected over seven months, our research reveals how cybercriminals understand AI and discuss how they can exploit its capabilities. Their exchanges reflect growing curiosity about AI's criminal applications through legal tools and dedicated criminal tools, but also doubts and anxieties about AI's effectiveness and its effects on their business models and operational security. The study documents attempts to misuse legitimate AI tools and develop bespoke models tailored for illicit purposes. Combining the diffusion of innovation framework with thematic analysis, the paper provides an in-depth view of emerging AI-enabled cybercrime and offers practical insights for law enforcement and policymakers.
Automated Alert Classification and Triage (AACT): An Intelligent System for the Prioritisation of Cybersecurity Alerts
May 14, 2025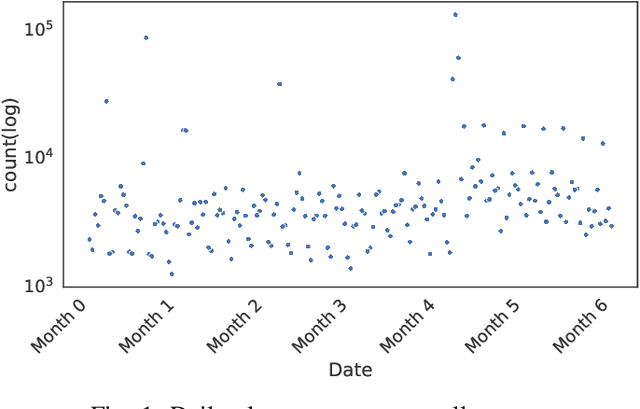
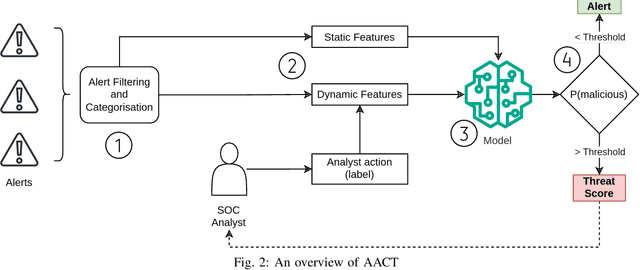
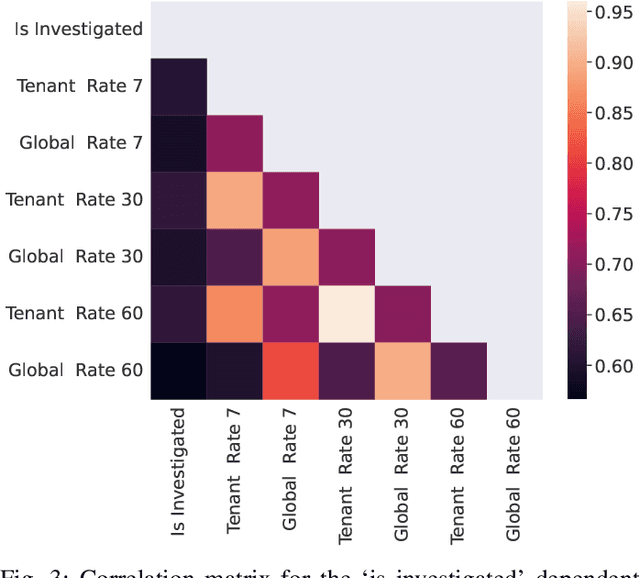
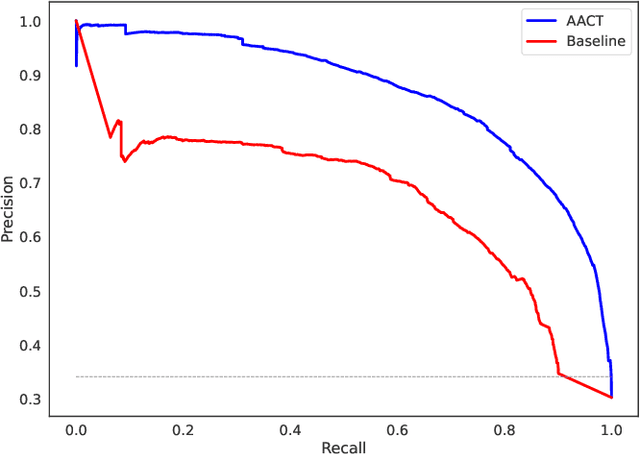
Enterprise networks are growing ever larger with a rapidly expanding attack surface, increasing the volume of security alerts generated from security controls. Security Operations Centre (SOC) analysts triage these alerts to identify malicious activity, but they struggle with alert fatigue due to the overwhelming number of benign alerts. Organisations are turning to managed SOC providers, where the problem is amplified by context switching and limited visibility into business processes. A novel system, named AACT, is introduced that automates SOC workflows by learning from analysts' triage actions on cybersecurity alerts. It accurately predicts triage decisions in real time, allowing benign alerts to be closed automatically and critical ones prioritised. This reduces the SOC queue allowing analysts to focus on the most severe, relevant or ambiguous threats. The system has been trained and evaluated on both real SOC data and an open dataset, obtaining high performance in identifying malicious alerts from benign alerts. Additionally, the system has demonstrated high accuracy in a real SOC environment, reducing alerts shown to analysts by 61% over six months, with a low false negative rate of 1.36% over millions of alerts.
The Use of Large Language Models (LLM) for Cyber Threat Intelligence (CTI) in Cybercrime Forums
Aug 06, 2024Large language models (LLMs) can be used to analyze cyber threat intelligence (CTI) data from cybercrime forums, which contain extensive information and key discussions about emerging cyber threats. However, to date, the level of accuracy and efficiency of LLMs for such critical tasks has yet to be thoroughly evaluated. Hence, this study assesses the accuracy of an LLM system built on the OpenAI GPT-3.5-turbo model [7] to extract CTI information. To do so, a random sample of 500 daily conversations from three cybercrime forums, XSS, Exploit.in, and RAMP, was extracted, and the LLM system was instructed to summarize the conversations and code 10 key CTI variables, such as whether a large organization and/or a critical infrastructure is being targeted. Then, two coders reviewed each conversation and evaluated whether the information extracted by the LLM was accurate. The LLM system performed strikingly well, with an average accuracy score of 98%. Various ways to enhance the model were uncovered, such as the need to help the LLM distinguish between stories and past events, as well as being careful with verb tenses in prompts. Nevertheless, the results of this study highlight the efficiency and relevance of using LLMs for cyber threat intelligence.