 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA simple but tough-to-beat baseline for the Fake News Challenge stance detection task
May 21, 2018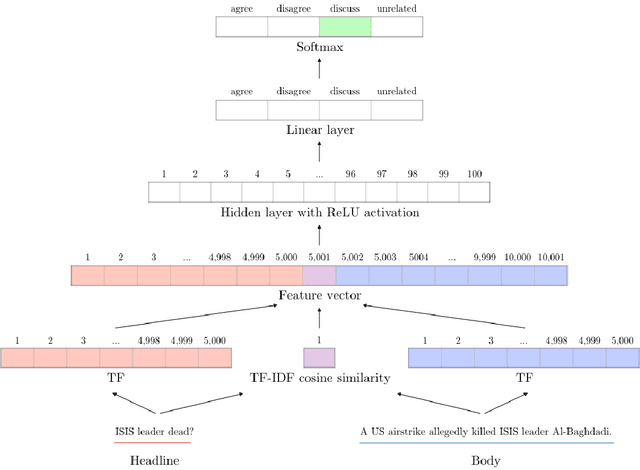
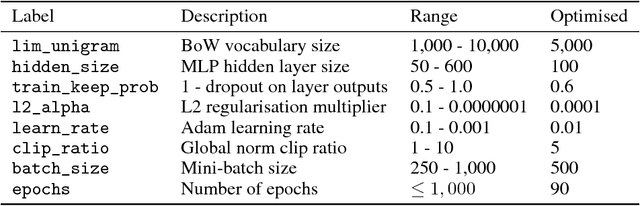
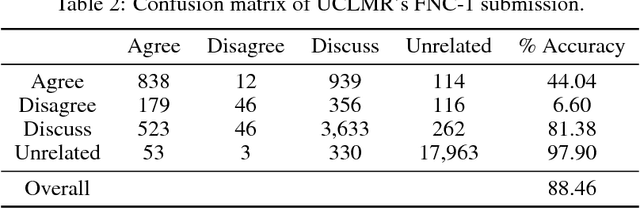
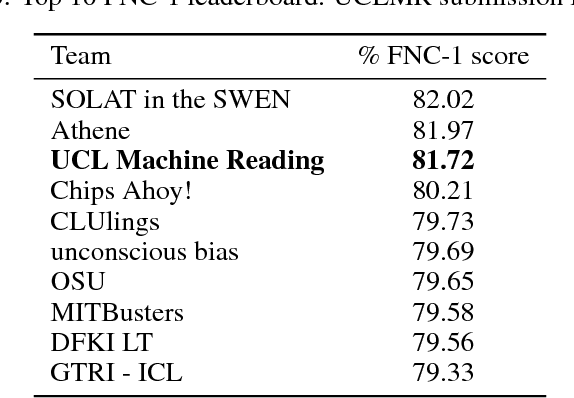
Identifying public misinformation is a complicated and challenging task. An important part of checking the veracity of a specific claim is to evaluate the stance different news sources take towards the assertion. Automatic stance evaluation, i.e. stance detection, would arguably facilitate the process of fact checking. In this paper, we present our stance detection system which claimed third place in Stage 1 of the Fake News Challenge. Despite our straightforward approach, our system performs at a competitive level with the complex ensembles of the top two winning teams. We therefore propose our system as the 'simple but tough-to-beat baseline' for the Fake News Challenge stance detection task.
Extrapolation in NLP
May 17, 2018
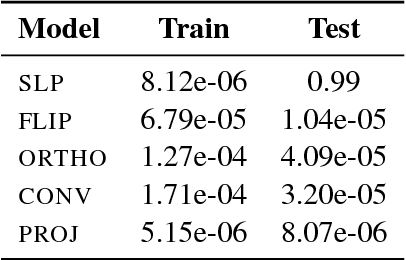
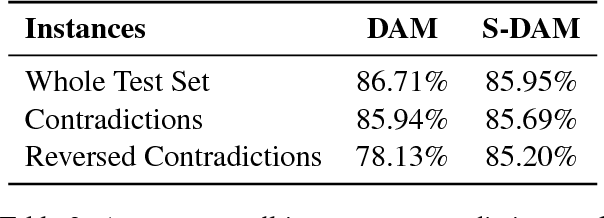
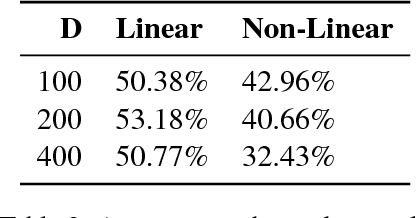
We argue that extrapolation to examples outside the training space will often be easier for models that capture global structures, rather than just maximise their local fit to the training data. We show that this is true for two popular models: the Decomposable Attention Model and word2vec.
Behavior Analysis of NLI Models: Uncovering the Influence of Three Factors on Robustness
May 11, 2018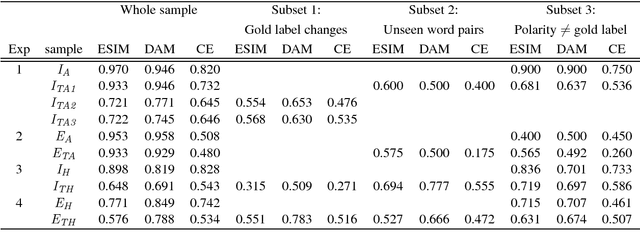

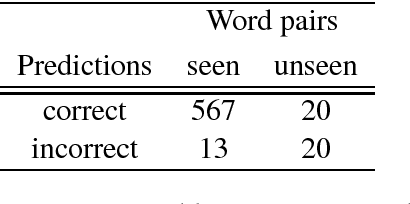
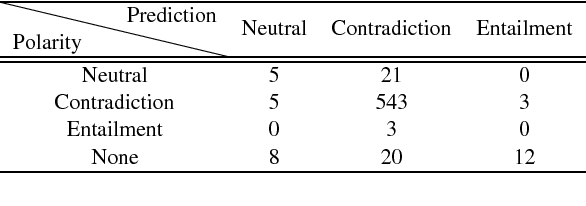
Natural Language Inference is a challenging task that has received substantial attention, and state-of-the-art models now achieve impressive test set performance in the form of accuracy scores. Here, we go beyond this single evaluation metric to examine robustness to semantically-valid alterations to the input data. We identify three factors - insensitivity, polarity and unseen pairs - and compare their impact on three SNLI models under a variety of conditions. Our results demonstrate a number of strengths and weaknesses in the models' ability to generalise to new in-domain instances. In particular, while strong performance is possible on unseen hypernyms, unseen antonyms are more challenging for all the models. More generally, the models suffer from an insensitivity to certain small but semantically significant alterations, and are also often influenced by simple statistical correlations between words and training labels. Overall, we show that evaluations of NLI models can benefit from studying the influence of factors intrinsic to the models or found in the dataset used.
Question Answering Resources Applied to Slot-Filling
Apr 22, 2018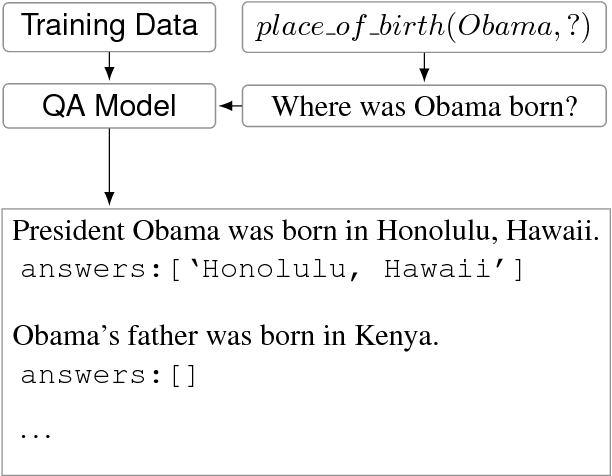
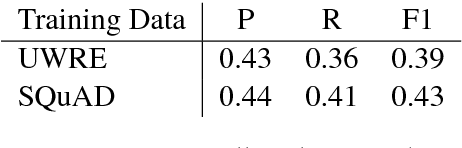
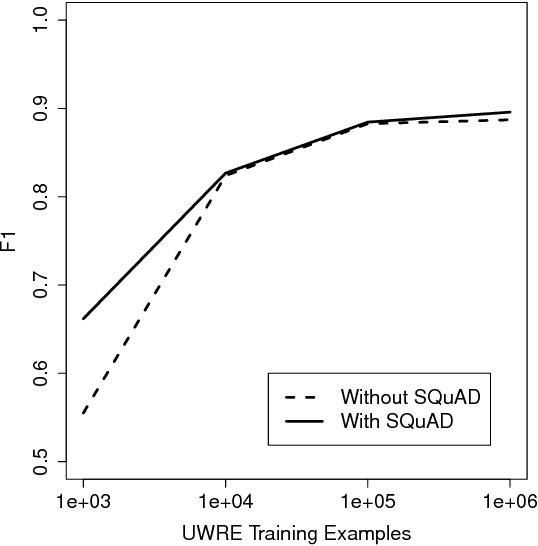
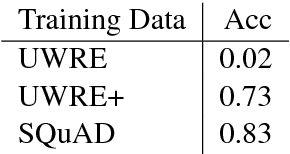
We investigate the utility of pre-existing question answering models and data for a recently proposed relation extraction task. We find that in the low-resource and zero-shot cases, such resources are surprisingly useful. Moreover, the resulting models show robust performance on a new test set we create from the task's original datasets.
End-to-End Differentiable Proving
Dec 04, 2017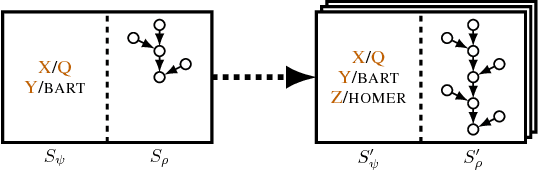
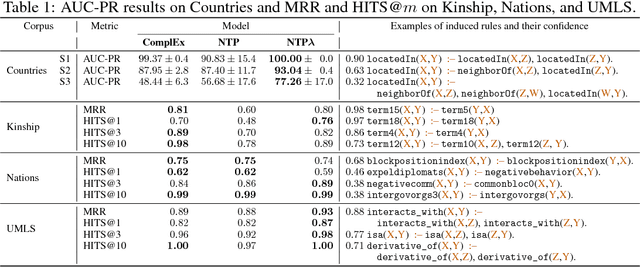
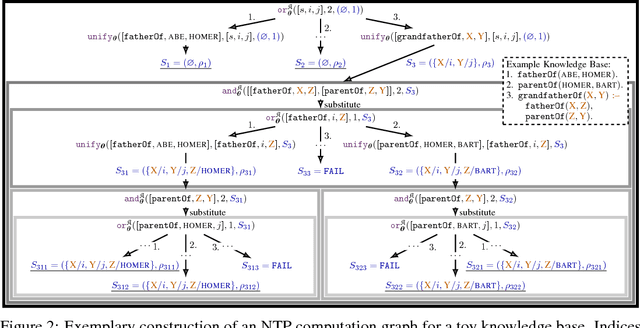
We introduce neural networks for end-to-end differentiable proving of queries to knowledge bases by operating on dense vector representations of symbols. These neural networks are constructed recursively by taking inspiration from the backward chaining algorithm as used in Prolog. Specifically, we replace symbolic unification with a differentiable computation on vector representations of symbols using a radial basis function kernel, thereby combining symbolic reasoning with learning subsymbolic vector representations. By using gradient descent, the resulting neural network can be trained to infer facts from a given incomplete knowledge base. It learns to (i) place representations of similar symbols in close proximity in a vector space, (ii) make use of such similarities to prove queries, (iii) induce logical rules, and (iv) use provided and induced logical rules for multi-hop reasoning. We demonstrate that this architecture outperforms ComplEx, a state-of-the-art neural link prediction model, on three out of four benchmark knowledge bases while at the same time inducing interpretable function-free first-order logic rules.
Knowledge Graph Completion via Complex Tensor Factorization
Nov 26, 2017
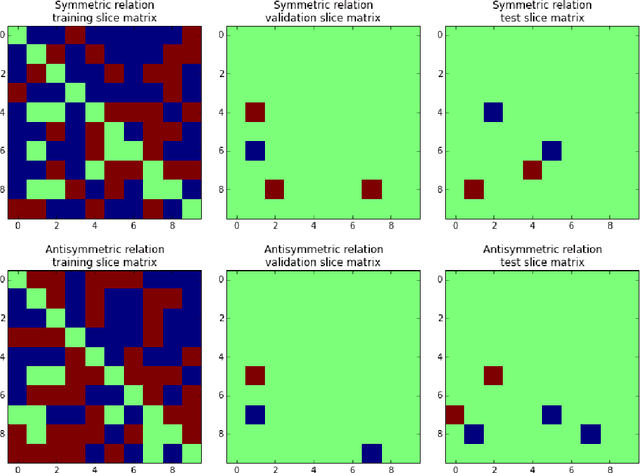
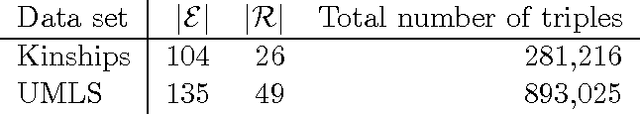
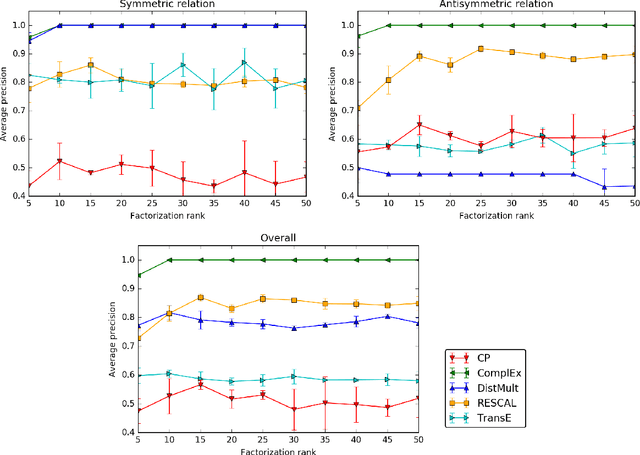
In statistical relational learning, knowledge graph completion deals with automatically understanding the structure of large knowledge graphs---labeled directed graphs---and predicting missing relationships---labeled edges. State-of-the-art embedding models propose different trade-offs between modeling expressiveness, and time and space complexity. We reconcile both expressiveness and complexity through the use of complex-valued embeddings and explore the link between such complex-valued embeddings and unitary diagonalization. We corroborate our approach theoretically and show that all real square matrices---thus all possible relation/adjacency matrices---are the real part of some unitarily diagonalizable matrix. This results opens the door to a lot of other applications of square matrices factorization. Our approach based on complex embeddings is arguably simple, as it only involves a Hermitian dot product, the complex counterpart of the standard dot product between real vectors, whereas other methods resort to more and more complicated composition functions to increase their expressiveness. The proposed complex embeddings are scalable to large data sets as it remains linear in both space and time, while consistently outperforming alternative approaches on standard link prediction benchmarks.
Adversarial Sets for Regularising Neural Link Predictors
Jul 24, 2017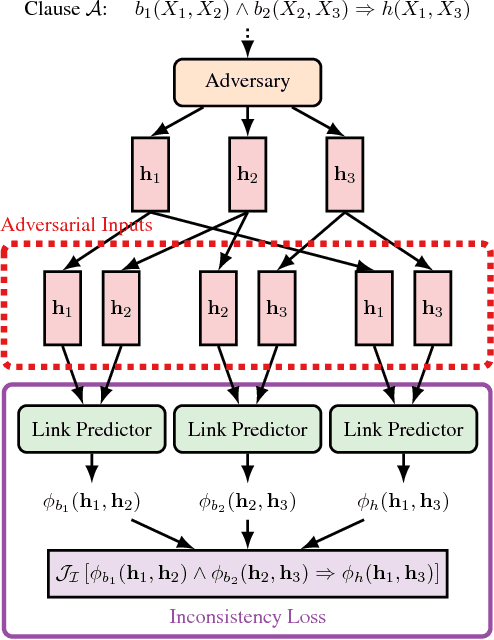


In adversarial training, a set of models learn together by pursuing competing goals, usually defined on single data instances. However, in relational learning and other non-i.i.d domains, goals can also be defined over sets of instances. For example, a link predictor for the is-a relation needs to be consistent with the transitivity property: if is-a(x_1, x_2) and is-a(x_2, x_3) hold, is-a(x_1, x_3) needs to hold as well. Here we use such assumptions for deriving an inconsistency loss, measuring the degree to which the model violates the assumptions on an adversarially-generated set of examples. The training objective is defined as a minimax problem, where an adversary finds the most offending adversarial examples by maximising the inconsistency loss, and the model is trained by jointly minimising a supervised loss and the inconsistency loss on the adversarial examples. This yields the first method that can use function-free Horn clauses (as in Datalog) to regularise any neural link predictor, with complexity independent of the domain size. We show that for several link prediction models, the optimisation problem faced by the adversary has efficient closed-form solutions. Experiments on link prediction benchmarks indicate that given suitable prior knowledge, our method can significantly improve neural link predictors on all relevant metrics.
Programming with a Differentiable Forth Interpreter
Jul 23, 2017
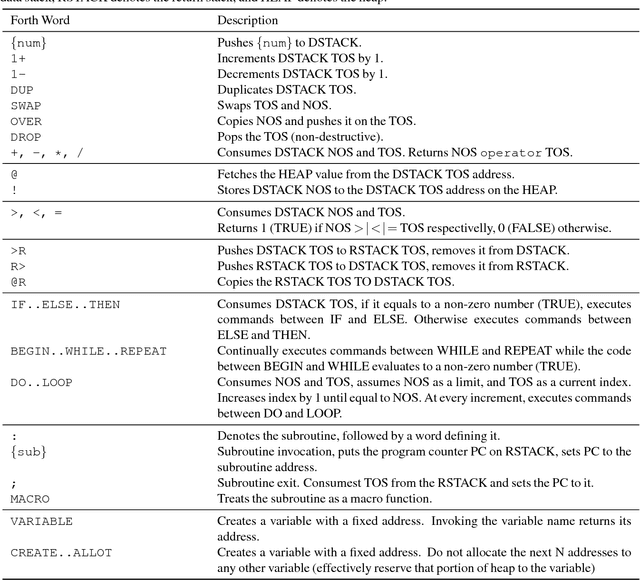
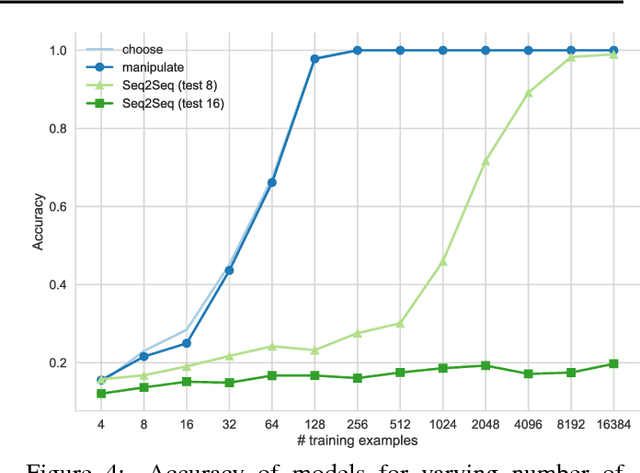
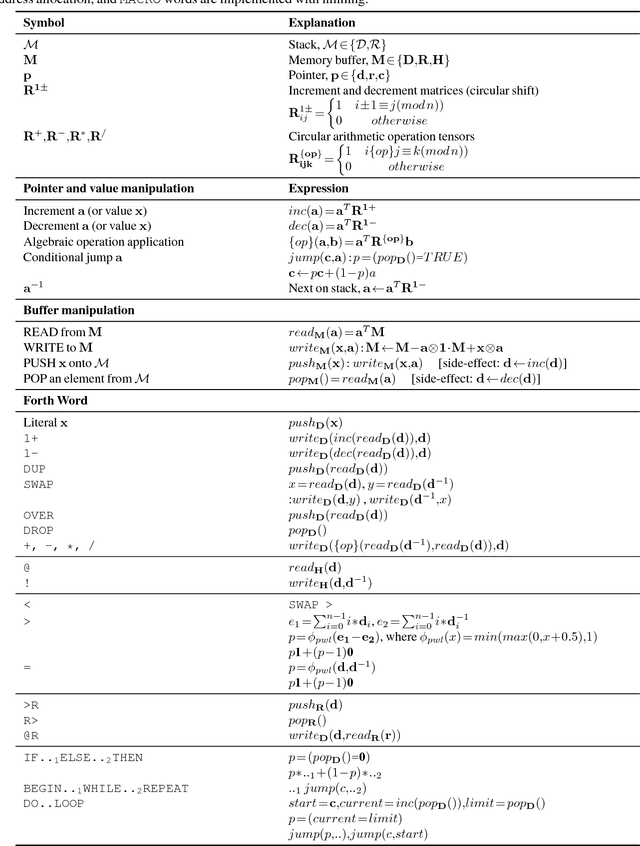
Given that in practice training data is scarce for all but a small set of problems, a core question is how to incorporate prior knowledge into a model. In this paper, we consider the case of prior procedural knowledge for neural networks, such as knowing how a program should traverse a sequence, but not what local actions should be performed at each step. To this end, we present an end-to-end differentiable interpreter for the programming language Forth which enables programmers to write program sketches with slots that can be filled with behaviour trained from program input-output data. We can optimise this behaviour directly through gradient descent techniques on user-specified objectives, and also integrate the program into any larger neural computation graph. We show empirically that our interpreter is able to effectively leverage different levels of prior program structure and learn complex behaviours such as sequence sorting and addition. When connected to outputs of an LSTM and trained jointly, our interpreter achieves state-of-the-art accuracy for end-to-end reasoning about quantities expressed in natural language stories.
A Supervised Approach to Extractive Summarisation of Scientific Papers
Jun 13, 2017
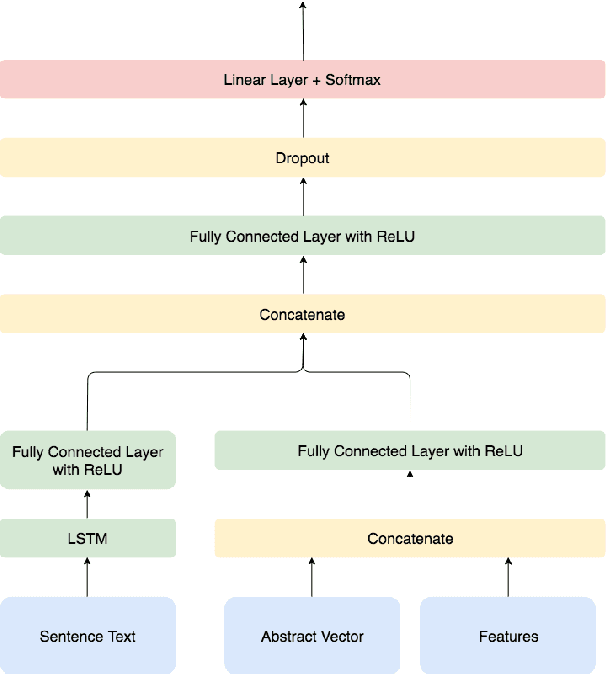
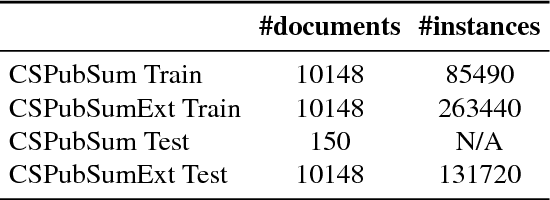
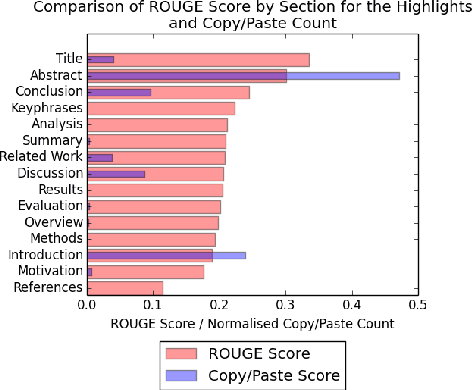
Automatic summarisation is a popular approach to reduce a document to its main arguments. Recent research in the area has focused on neural approaches to summarisation, which can be very data-hungry. However, few large datasets exist and none for the traditionally popular domain of scientific publications, which opens up challenging research avenues centered on encoding large, complex documents. In this paper, we introduce a new dataset for summarisation of computer science publications by exploiting a large resource of author provided summaries and show straightforward ways of extending it further. We develop models on the dataset making use of both neural sentence encoding and traditionally used summarisation features and show that models which encode sentences as well as their local and global context perform best, significantly outperforming well-established baseline methods.
SemEval 2017 Task 10: ScienceIE - Extracting Keyphrases and Relations from Scientific Publications
May 02, 2017

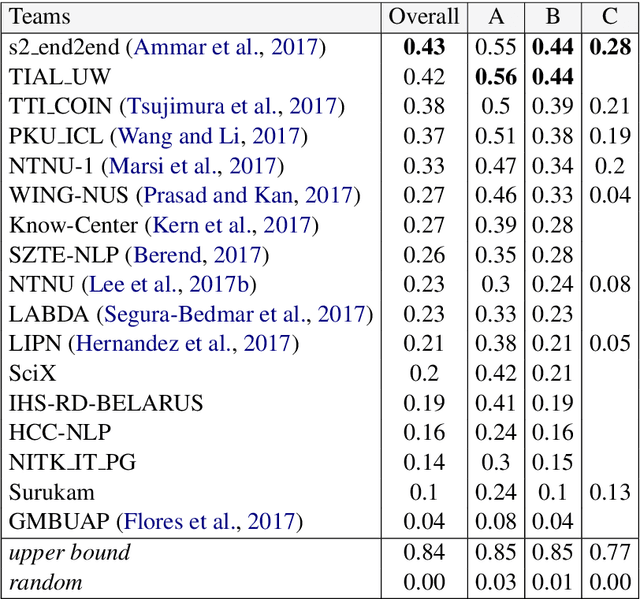
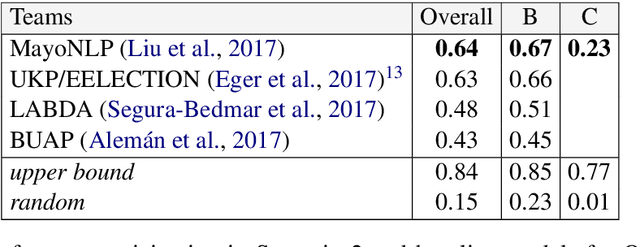
We describe the SemEval task of extracting keyphrases and relations between them from scientific documents, which is crucial for understanding which publications describe which processes, tasks and materials. Although this was a new task, we had a total of 26 submissions across 3 evaluation scenarios. We expect the task and the findings reported in this paper to be relevant for researchers working on understanding scientific content, as well as the broader knowledge base population and information extraction communities.