 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThresholded Local Hyper-Flow Diffusion
Jun 08, 2026Local Hyper-Flow Diffusion (HFD) gives an edge-size-independent Cheeger-type guarantee for seeded clustering in general submodular hypergraphs, but existing HFD solvers do not keep intermediate computation local at every iteration. We introduce Thresholded Local HFD (TL-HFD), a first-order method that maintains an active region around the seeds, performs projected subgradient updates on that region and its immediate boundary, and expands via thresholded (top-k) boundary activation. We prove that the local update is exact: the degree-preconditioned projected subgradient step restricted to the active region and its boundary coincides with the unrestricted global update. We establish finite-time dual suboptimality for both exact and thresholded updates, treating the latter as inexact projected subgradient steps with explicit skipped-boundary error. We further derive an additive activated-volume bound controlled by realized local subgradient norms and the minimum boundary-push among newly activated vertices, and translate approximate dual optimality with localized support into a robust sweep-cut guarantee for early-stopped iterates. For general submodular cut-costs, each iteration is local in the scanned region and oracle-sensitive in the hyperedge primitive. Empirically, TL-HFD often matches or improves over HFD while activating less volume, with the largest gains on noisy instances where diffusion tends to absorb non-target vertices.
Federated Binary Matrix Factorization using Proximal Optimization
Jul 01, 2024Identifying informative components in binary data is an essential task in many research areas, including life sciences, social sciences, and recommendation systems. Boolean matrix factorization (BMF) is a family of methods that performs this task by efficiently factorizing the data. In real-world settings, the data is often distributed across stakeholders and required to stay private, prohibiting the straightforward application of BMF. To adapt BMF to this context, we approach the problem from a federated-learning perspective, while building on a state-of-the-art continuous binary matrix factorization relaxation to BMF that enables efficient gradient-based optimization. We propose to only share the relaxed component matrices, which are aggregated centrally using a proximal operator that regularizes for binary outcomes. We show the convergence of our federated proximal gradient descent algorithm and provide differential privacy guarantees. Our extensive empirical evaluation demonstrates that our algorithm outperforms, in terms of quality and efficacy, federation schemes of state-of-the-art BMF methods on a diverse set of real-world and synthetic data.
Efficiently Factorizing Boolean Matrices using Proximal Gradient Descent
Jul 14, 2023



Addressing the interpretability problem of NMF on Boolean data, Boolean Matrix Factorization (BMF) uses Boolean algebra to decompose the input into low-rank Boolean factor matrices. These matrices are highly interpretable and very useful in practice, but they come at the high computational cost of solving an NP-hard combinatorial optimization problem. To reduce the computational burden, we propose to relax BMF continuously using a novel elastic-binary regularizer, from which we derive a proximal gradient algorithm. Through an extensive set of experiments, we demonstrate that our method works well in practice: On synthetic data, we show that it converges quickly, recovers the ground truth precisely, and estimates the simulated rank exactly. On real-world data, we improve upon the state of the art in recall, loss, and runtime, and a case study from the medical domain confirms that our results are easily interpretable and semantically meaningful.
Differentially Describing Groups of Graphs
Dec 16, 2021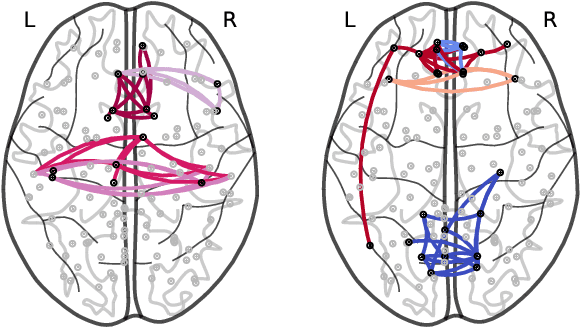
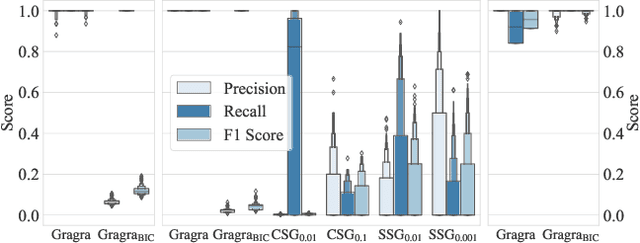
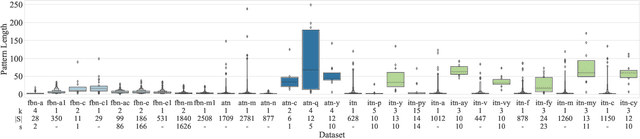
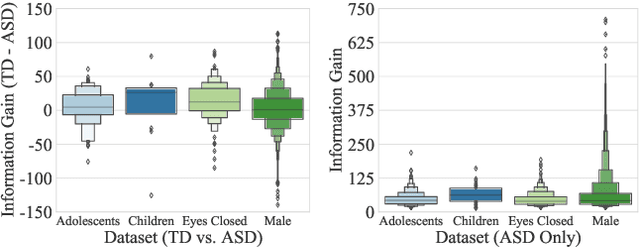
How does neural connectivity in autistic children differ from neural connectivity in healthy children or autistic youths? What patterns in global trade networks are shared across classes of goods, and how do these patterns change over time? Answering questions like these requires us to differentially describe groups of graphs: Given a set of graphs and a partition of these graphs into groups, discover what graphs in one group have in common, how they systematically differ from graphs in other groups, and how multiple groups of graphs are related. We refer to this task as graph group analysis, which seeks to describe similarities and differences between graph groups by means of statistically significant subgraphs. To perform graph group analysis, we introduce Gragra, which uses maximum entropy modeling to identify a non-redundant set of subgraphs with statistically significant associations to one or more graph groups. Through an extensive set of experiments on a wide range of synthetic and real-world graph groups, we confirm that Gragra works well in practice.