 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Topical Similarity: Contrastive Evidence Retrieval with Interpretable Attention Alignment in RAG
May 31, 2026Ensuring factuality and interpretability in RAG remains an open and urgent problem. We introduce Contrastive Evidence Rationale Attention (CERA), the first retrieval framework to employ subjectivity-based hard negative selection and inject an evidential inductive bias into contrastive learning through an auxiliary attention alignment loss. CERA fine-tunes a dense retriever using two training objectives: triplet-based contrastive learning and interpretable attention alignment, which supervises CLS-to-token attention using a part-of-speech-weighted masking distribution over human-annotated factual rationales as evidence signals. Experiments on a large corpus of clinical trial reports demonstrate that the subjectivity-based hard negative selection substantially improves retrieval effectiveness compared to both Contriever and hard negative selection baselines. Furthermore, rationale alignment improves faithfulness while maintaining competitive retrieval performance, supporting the hypothesis that attention can serve as a more faithful explanation of model behavior when guided by human rationales. Moving beyond topical similarity, CERA enables the retriever to identify the specific tokens that constitute supporting evidence, promoting more interpretable evidence selection in RAG systems.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020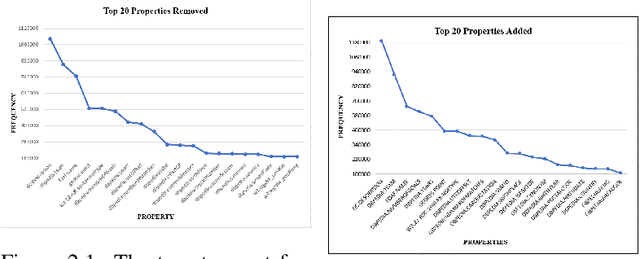
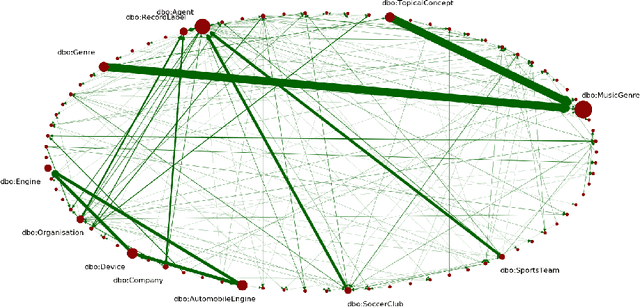

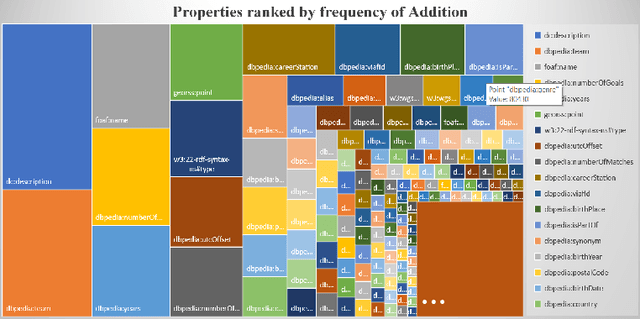
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.