 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of On-Device Streaming ASR: A Compact, High-Accuracy English Model for Low-Latency Inference
Apr 16, 2026Deploying high-quality automatic speech recognition (ASR) on edge devices requires models that jointly optimize accuracy, latency, and memory footprint while operating entirely on CPU without GPU acceleration. We conduct a systematic empirical study of state-of-the-art ASR architectures, encompassing encoder-decoder, transducer, and LLM-based paradigms, evaluated across batch, chunked, and streaming inference modes. Through a comprehensive benchmark of over 50 configurations spanning OpenAI Whisper, NVIDIA Nemotron, Parakeet TDT, Canary, Conformer Transducer, and Qwen3-ASR, we identify NVIDIA's Nemotron Speech Streaming as the strongest candidate for real-time English streaming on resource-constrained hardware. We then re-implement the complete streaming inference pipeline in ONNX Runtime and conduct a controlled evaluation of multiple post-training quantization strategies, including importance-weighted k-quant, mixed-precision schemes, and round-to-nearest quantization, combined with graph-level operator fusion. These optimizations reduce the model from 2.47 GB to as little as 0.67 GB while maintaining word error rate (WER) within 1% absolute of the full-precision PyTorch baseline. Our recommended configuration, the int4 k-quant variant, achieves 8.20% average streaming WER across eight standard benchmarks, running comfortably faster than real-time on CPU with 0.56 s algorithmic latency, establishing a new quality-efficiency Pareto point for on-device streaming ASR.
Neighbor-Based Optimized Logistic Regression Machine Learning Model For Electric Vehicle Occupancy Detection
Apr 28, 2022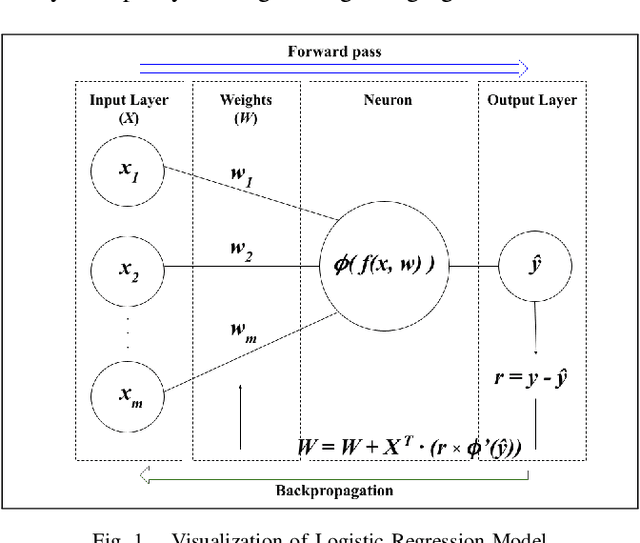
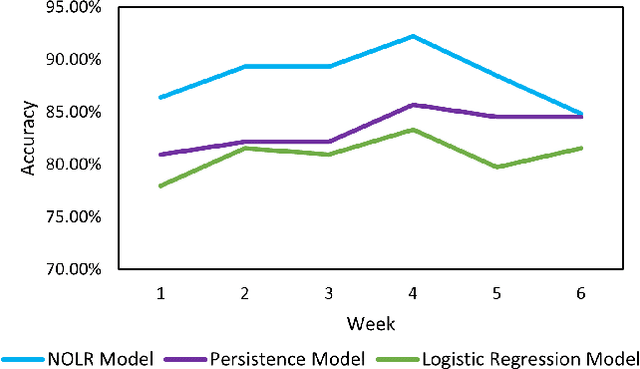
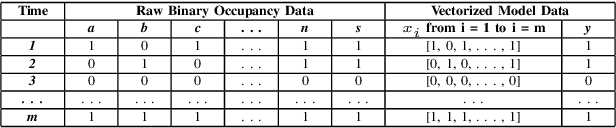
This paper presents an optimized logistic regression machine learning model that predicts the occupancy of an Electric Vehicle (EV) charging station given the occupancy of neighboring stations. The model was optimized for the time of day. Trained on data from 57 EV charging stations around the University of California San Diego campus, the model achieved an 88.43% average accuracy and 92.23% maximum accuracy in predicting occupancy, outperforming a persistence model benchmark.