 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Here, Go There: Analyzing Redirection Patterns on the Web
Jul 29, 2025URI redirections are integral to web management, supporting structural changes, SEO optimization, and security. However, their complexities affect usability, SEO performance, and digital preservation. This study analyzed 11 million unique redirecting URIs, following redirections up to 10 hops per URI, to uncover patterns and implications of redirection practices. Our findings revealed that 50% of the URIs terminated successfully, while 50% resulted in errors, including 0.06% exceeding 10 hops. Canonical redirects, such as HTTP to HTTPS transitions, were prevalent, reflecting adherence to SEO best practices. Non-canonical redirects, often involving domain or path changes, highlighted significant web migrations, rebranding, and security risks. Notable patterns included "sink" URIs, where multiple redirects converged, ranging from traffic consolidation by global websites to deliberate "Rickrolling." The study also identified 62,000 custom 404 URIs, almost half being soft 404s, which could compromise SEO and user experience. These findings underscore the critical role of URI redirects in shaping the web while exposing challenges such as outdated URIs, server instability, and improper error handling. This research offers a detailed analysis of URI redirection practices, providing insights into their prevalence, types, and outcomes. By examining a large dataset, we highlight inefficiencies in redirection chains and examine patterns such as the use of "sink" URIs and custom error pages. This information can help webmasters, researchers, and digital archivists improve web usability, optimize resource allocation, and safeguard valuable online content.
Profiling Web Archival Voids for Memento Routing
Aug 06, 2021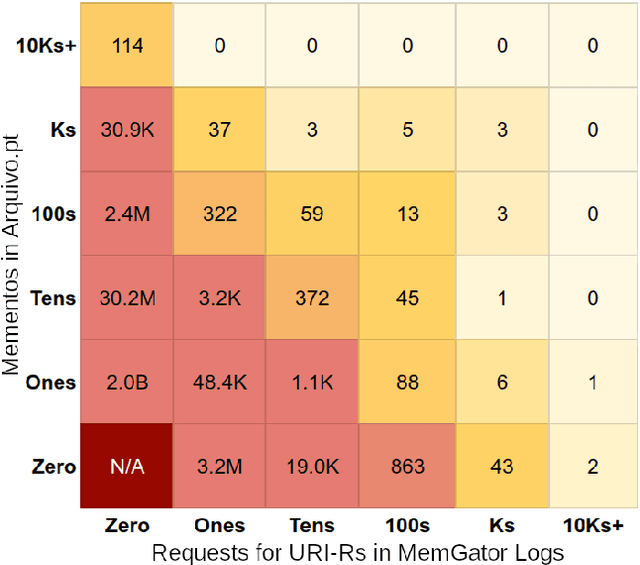
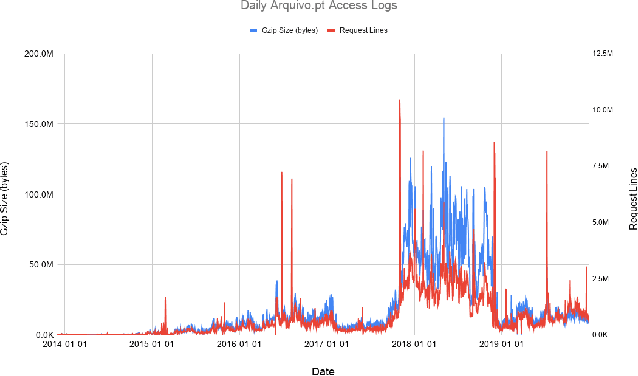
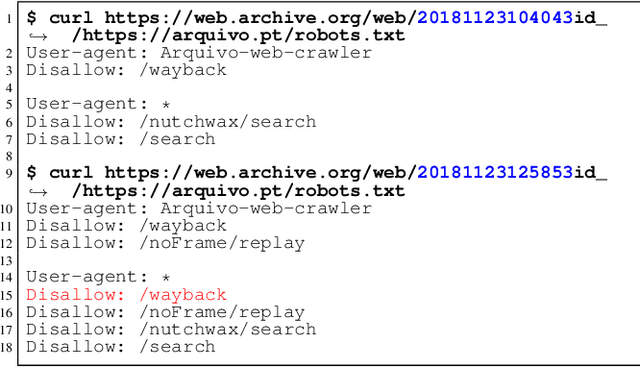
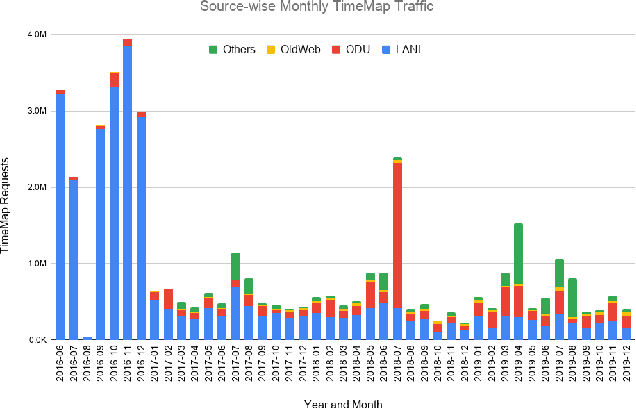
Prior work on web archive profiling were focused on Archival Holdings to describe what is present in an archive. This work defines and explores Archival Voids to establish a means to represent portions of URI spaces that are not present in a web archive. Archival Holdings and Archival Voids profiles can work independently or as complements to each other to maximize the Accuracy of Memento Aggregators. We discuss various sources of truth that can be used to create Archival Voids profiles. We use access logs from Arquivo.pt to create various Archival Voids profiles and analyze them against our MemGator access logs for evaluation. We find that we could have avoided more than 8% of additional False Positives on top of the 60% Accuracy we got from profiling Archival Holdings in our prior work, if Arquivo.pt were to provide an Archival Voids profile based on URIs that were requested hundreds of times and never returned any success responses.