 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Random Wavelet Features: Efficient Non-Stationary Kernel Approximation with Convergence Guarantees
Feb 01, 2026Modeling non-stationary processes, where statistical properties vary across the input domain, is a critical challenge in machine learning; yet most scalable methods rely on a simplifying assumption of stationarity. This forces a difficult trade-off: use expressive but computationally demanding models like Deep Gaussian Processes, or scalable but limited methods like Random Fourier Features (RFF). We close this gap by introducing Random Wavelet Features (RWF), a framework that constructs scalable, non-stationary kernel approximations by sampling from wavelet families. By harnessing the inherent localization and multi-resolution structure of wavelets, RWF generates an explicit feature map that captures complex, input-dependent patterns. Our framework provides a principled way to generalize RFF to the non-stationary setting and comes with a comprehensive theoretical analysis, including positive definiteness, unbiasedness, and uniform convergence guarantees. We demonstrate empirically on a range of challenging synthetic and real-world datasets that RWF outperforms stationary random features and offers a compelling accuracy-efficiency trade-off against more complex models, unlocking scalable and expressive kernel methods for a broad class of real-world non-stationary problems.
Towards Gaussian Process for operator learning: an uncertainty aware resolution independent operator learning algorithm for computational mechanics
Sep 17, 2024



The growing demand for accurate, efficient, and scalable solutions in computational mechanics highlights the need for advanced operator learning algorithms that can efficiently handle large datasets while providing reliable uncertainty quantification. This paper introduces a novel Gaussian Process (GP) based neural operator for solving parametric differential equations. The approach proposed leverages the expressive capability of deterministic neural operators and the uncertainty awareness of conventional GP. In particular, we propose a ``neural operator-embedded kernel'' wherein the GP kernel is formulated in the latent space learned using a neural operator. Further, we exploit a stochastic dual descent (SDD) algorithm for simultaneously training the neural operator parameters and the GP hyperparameters. Our approach addresses the (a) resolution dependence and (b) cubic complexity of traditional GP models, allowing for input-resolution independence and scalability in high-dimensional and non-linear parametric systems, such as those encountered in computational mechanics. We apply our method to a range of non-linear parametric partial differential equations (PDEs) and demonstrate its superiority in both computational efficiency and accuracy compared to standard GP models and wavelet neural operators. Our experimental results highlight the efficacy of this framework in solving complex PDEs while maintaining robustness in uncertainty estimation, positioning it as a scalable and reliable operator-learning algorithm for computational mechanics.
Neural Operator induced Gaussian Process framework for probabilistic solution of parametric partial differential equations
Apr 24, 2024



The study of neural operators has paved the way for the development of efficient approaches for solving partial differential equations (PDEs) compared with traditional methods. However, most of the existing neural operators lack the capability to provide uncertainty measures for their predictions, a crucial aspect, especially in data-driven scenarios with limited available data. In this work, we propose a novel Neural Operator-induced Gaussian Process (NOGaP), which exploits the probabilistic characteristics of Gaussian Processes (GPs) while leveraging the learning prowess of operator learning. The proposed framework leads to improved prediction accuracy and offers a quantifiable measure of uncertainty. The proposed framework is extensively evaluated through experiments on various PDE examples, including Burger's equation, Darcy flow, non-homogeneous Poisson, and wave-advection equations. Furthermore, a comparative study with state-of-the-art operator learning algorithms is presented to highlight the advantages of NOGaP. The results demonstrate superior accuracy and expected uncertainty characteristics, suggesting the promising potential of the proposed framework.
Reordering Examples Helps during Priming-based Few-Shot Learning
Jun 03, 2021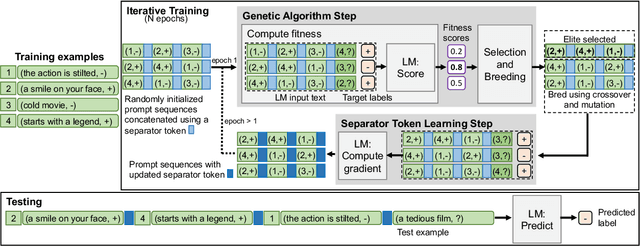


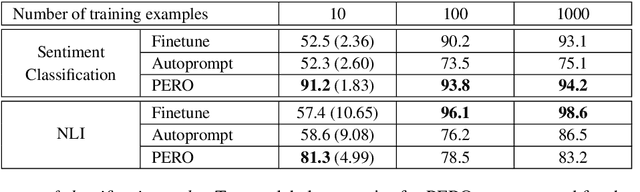
The ability to learn from limited data, or few-shot learning, is a desirable and often critical requirement for NLP systems. While many existing methods do poorly at learning from a handful of examples, large pretrained language models have recently been shown to be efficient few-shot learners. One approach to few-shot learning, which does not require finetuning of model parameters, is to augment the language model's input with priming text which is typically constructed using task specific descriptions and examples. In this work, we further explore priming-based few-shot learning, with focus on using examples as prompts. We show that presenting examples in the right order is key for generalization. We introduce PERO (Prompting with Examples in the Right Order), where we formulate few-shot learning as search over the set of permutations of the training examples. We show that PERO can learn to generalize efficiently using as few as 10 examples, in contrast to existing approaches. While the newline token is a natural choice for separating the examples in the prompt, we show that learning a new separator token can potentially provide further gains in performance. We demonstrate the effectiveness of the proposed method on the tasks of sentiment classification, natural language inference and fact retrieval. Finally, we analyze the learned prompts to reveal novel insights, including the idea that two training examples in the right order alone can provide competitive performance for sentiment classification and natural language inference.
NILE : Natural Language Inference with Faithful Natural Language Explanations
May 25, 2020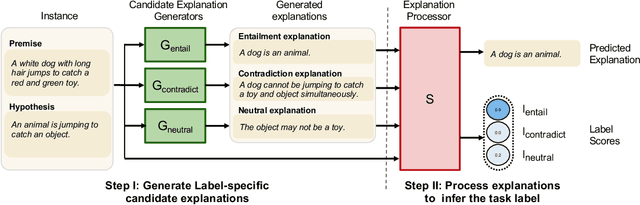
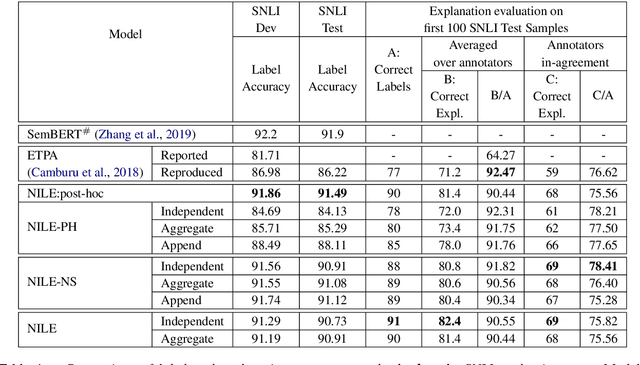
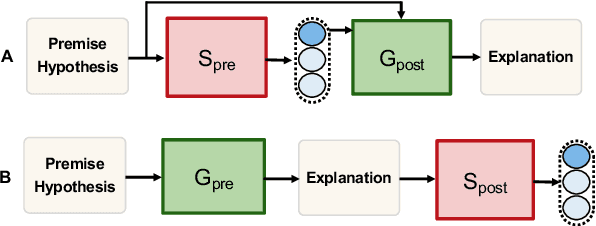
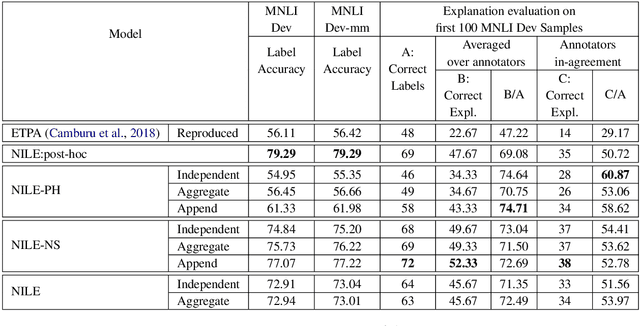
The recent growth in the popularity and success of deep learning models on NLP classification tasks has accompanied the need for generating some form of natural language explanation of the predicted labels. Such generated natural language (NL) explanations are expected to be faithful, i.e., they should correlate well with the model's internal decision making. In this work, we focus on the task of natural language inference (NLI) and address the following question: can we build NLI systems which produce labels with high accuracy, while also generating faithful explanations of its decisions? We propose Natural-language Inference over Label-specific Explanations (NILE), a novel NLI method which utilizes auto-generated label-specific NL explanations to produce labels along with its faithful explanation. We demonstrate NILE's effectiveness over previously reported methods through automated and human evaluation of the produced labels and explanations. Our evaluation of NILE also supports the claim that accurate systems capable of providing testable explanations of their decisions can be designed. We discuss the faithfulness of NILE's explanations in terms of sensitivity of the decisions to the corresponding explanations. We argue that explicit evaluation of faithfulness, in addition to label and explanation accuracy, is an important step in evaluating model's explanations. Further, we demonstrate that task-specific probes are necessary to establish such sensitivity.