 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Matters: Vision-Based Depression Detection Comparing Classical and Deep Approaches
Apr 11, 2026The classical approach to detecting depression from vision emphasizes interpretable features, such as facial expression, and classifiers such as the Support Vector Machine (SVM). With the advent of deep learning, there has been a shift in feature representations and classification approaches. Contemporary approaches use learnt features from general-purpose vision models such as VGGNet to train machine learning models. Little is known about how classical and deep approaches compare in depression detection with respect to accuracy, fairness, and generalizability, especially across contexts. To address these questions, we compared classical and deep approaches to the detection of depression in the visual modality in two different contexts: Mother-child interactions in the TPOT database and patient-clinician interviews in the Pitt database. In the former, depression was operationalized as a history of depression per the DSM and current or recent clinically significant symptoms. In the latter, all participants met initial criteria for depression per DSM, and depression was reassessed over the course of treatment. The classical approach included handcrafted features with SVM classifiers. Learnt features were turn-level embeddings from the FMAE-IAT that were combined with Multi-Layer Perceptron classifiers. The classical approach achieved higher accuracy in both contexts. It was also significantly fairer than the deep approach in the patient-clinician context. Cross-context generalizability was modest at best for both approaches, which suggests that depression may be context-specific.
Beyond the Fold: Quantifying Split-Level Noise and the Case for Leave-One-Dataset-Out AU Evaluation
Apr 02, 2026Subject-exclusive cross-validation is the standard evaluation protocol for facial Action Unit (AU) detection, yet reported improvements are often small. We show that cross-validation itself introduces measurable stochastic variance. On BP4D+, repeated 3-fold subject-exclusive splits produce an empirical noise floor of $\pm 0.065$ in average F1, with substantially larger variation for low-prevalence AUs. Operating-point metrics such as F1 fluctuate more than threshold-independent measures such as AUC, and model ranking can change under different fold assignments. We further evaluate cross-dataset robustness using a Leave-One-Dataset-Out (LODO) protocol across five AU datasets. LODO removes partition randomness and exposes domain-level instability that is not visible under single-dataset cross-validation. Together, these results suggest that gains often reported in cross-fold validation may fall within protocol variance. Leave-one-dataset-out cross-validation yields more stable and interpretable findings
Random Forest Regression for continuous affect using Facial Action Units
Mar 29, 2022
In this paper we describe our approach to the arousal and valence track of the 3rd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). We extracted facial features using OpenFace and used them to train a multiple output random forest regressor. Our approach performed comparable to the baseline approach.
Impact of Action Unit Occurrence Patterns on Detection
Oct 15, 2020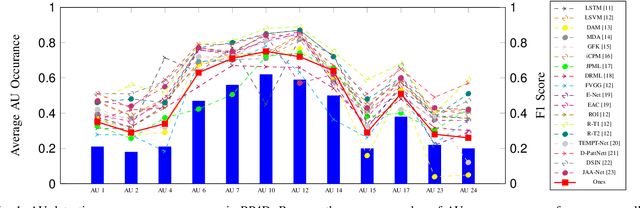
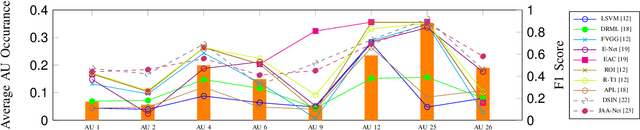
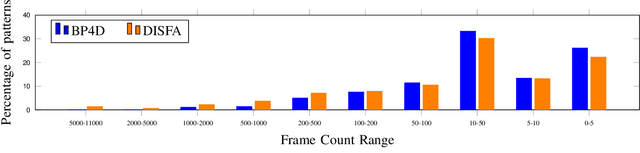
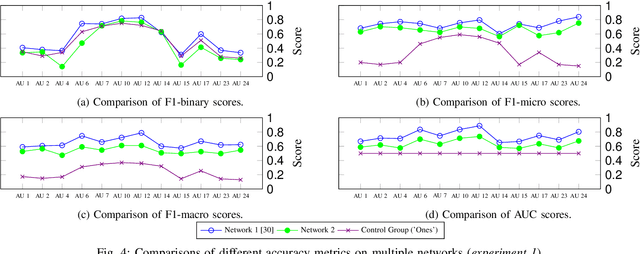
Detecting action units is an important task in face analysis, especially in facial expression recognition. This is due, in part, to the idea that expressions can be decomposed into multiple action units. In this paper we investigate the impact of action unit occurrence patterns on detection of action units. To facilitate this investigation, we review state of the art literature, for AU detection, on 2 state-of-the-art face databases that are commonly used for this task, namely DISFA, and BP4D. Our findings, from this literature review, suggest that action unit occurrence patterns strongly impact evaluation metrics (e.g. F1-binary). Along with the literature review, we also conduct multi and single action unit detection, as well as propose a new approach to explicitly train deep neural networks using the occurrence patterns to boost the accuracy of action unit detection. These experiments validate that action unit patterns directly impact the evaluation metrics.
Facial Action Unit Detection using 3D Facial Landmarks
May 17, 2020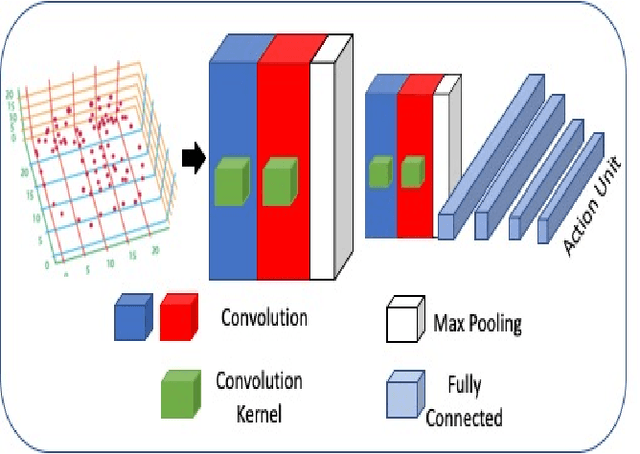
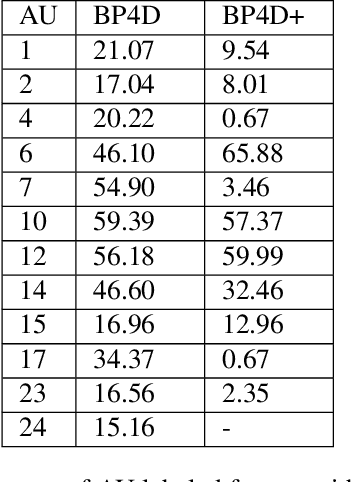
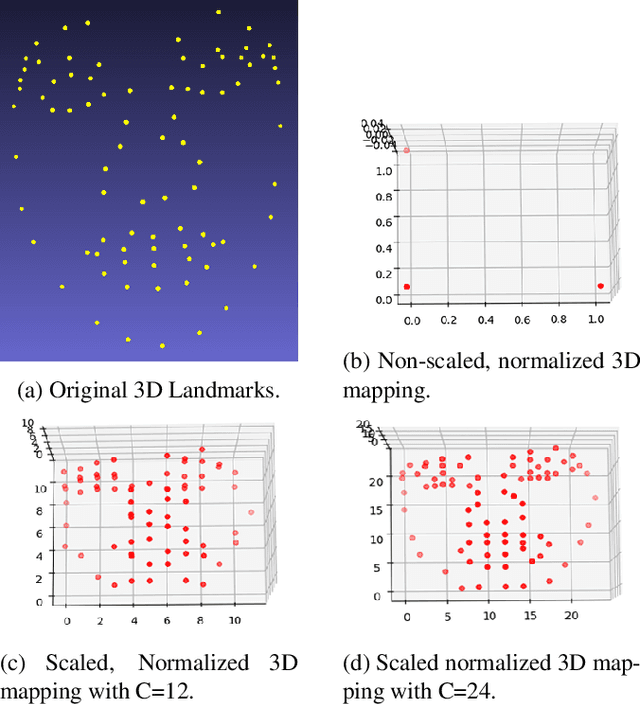
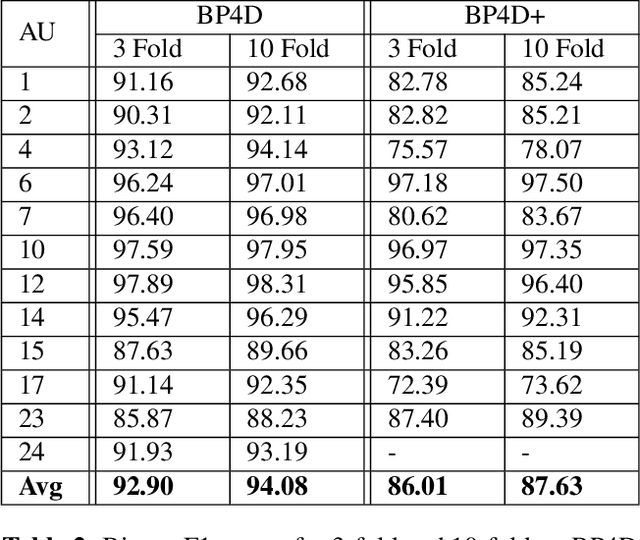
In this paper, we propose to detect facial action units (AU) using 3D facial landmarks. Specifically, we train a 2D convolutional neural network (CNN) on 3D facial landmarks, tracked using a shape index-based statistical shape model, for binary and multi-class AU detection. We show that the proposed approach is able to accurately model AU occurrences, as the movement of the facial landmarks corresponds directly to the movement of the AUs. By training a CNN on 3D landmarks, we can achieve accurate AU detection on two state-of-the-art emotion datasets, namely BP4D and BP4D+. Using the proposed method, we detect multiple AUs on over 330,000 frames, reporting improved results over state-of-the-art methods.