 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon Sense vs. Morality: The Curious Case of Narrative Focus Bias in LLMs
Mar 10, 2026Large Language Models (LLMs) are increasingly deployed across diverse real-world applications and user communities. As such, it is crucial that these models remain both morally grounded and knowledge-aware. In this work, we uncover a critical limitation of current LLMs -- their tendency to prioritize moral reasoning over commonsense understanding. To investigate this phenomenon, we introduce CoMoral, a novel benchmark dataset containing commonsense contradictions embedded within moral dilemmas. Through extensive evaluation of ten LLMs across different model sizes, we find that existing models consistently struggle to identify such contradictions without prior signal. Furthermore, we observe a pervasive narrative focus bias, wherein LLMs more readily detect commonsense contradictions when they are attributed to a secondary character rather than the primary (narrator) character. Our comprehensive analysis underscores the need for enhanced reasoning-aware training to improve the commonsense robustness of large language models.
A Variant of Gradient Descent Algorithm Based on Gradient Averaging
Dec 10, 2020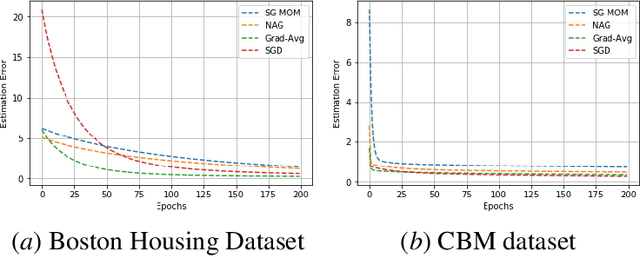

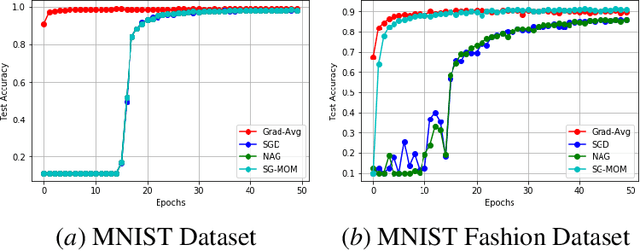

In this work, we study an optimizer, Grad-Avg to optimize error functions. We establish the convergence of the sequence of iterates of Grad-Avg mathematically to a minimizer (under boundedness assumption). We apply Grad-Avg along with some of the popular optimizers on regression as well as classification tasks. In regression tasks, it is observed that the behaviour of Grad-Avg is almost identical with Stochastic Gradient Descent (SGD). We present a mathematical justification of this fact. In case of classification tasks, it is observed that the performance of Grad-Avg can be enhanced by suitably scaling the parameters. Experimental results demonstrate that Grad-Avg converges faster than the other state-of-the-art optimizers for the classification task on two benchmark datasets.