 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Object Detection and Localization in Compressive Sensed Video on Embedded Hardware
Dec 23, 2019

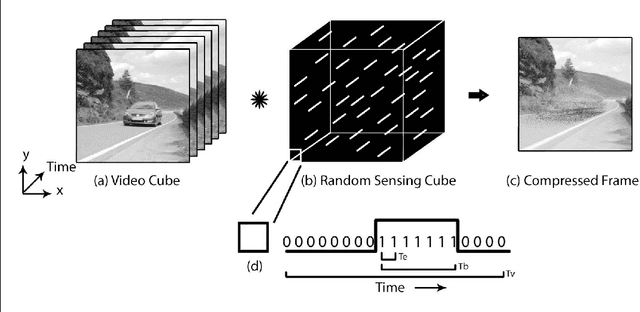

Every day around the world, interminable terabytes of data are being captured for surveillance purposes. A typical 1-2MP CCTV camera generates around 7-12GB of data per day. Frame-by-frame processing of such enormous amount of data requires hefty computational resources. In recent years, compressive sensing approaches have shown impressive results in signal processing by reducing the sampling bandwidth. Different sampling mechanisms were developed to incorporate compressive sensing in image and video acquisition. Pixel-wise coded exposure is one among the promising sensing paradigms for capturing videos in the compressed domain, which was also realized into an all-CMOS sensor \cite{Xiong2017}. Though cameras that perform compressive sensing save a lot of bandwidth at the time of sampling and minimize the memory required to store videos, we cannot do much in terms of processing until the videos are reconstructed to the original frames. But, the reconstruction of compressive-sensed (CS) videos still takes a lot of time and is also computationally expensive. In this work, we show that object detection and localization can be possible directly on the CS frames (easily upto 20x compression). To our knowledge, this is the first time that the problem of object detection and localization on CS frames has been attempted. Hence, we also created a dataset for training in the CS domain. We were able to achieve a good accuracy of 46.27\% mAP(Mean Average Precision) with the proposed model with an inference time of 23ms directly on the compressed frames(approx. 20 original domain frames), this facilitated for real-time inference which was verified on NVIDIA TX2 embedded board. Our framework will significantly reduce the communication bandwidth, and thus reduction in power as the video compression will be done at the image sensor processing core.
A Compressive Sensing Video dataset using Pixel-wise coded exposure
May 24, 2019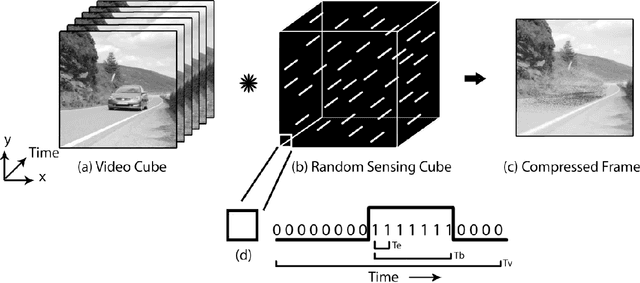



Manifold amount of video data gets generated every minute as we read this document, ranging from surveillance to broadcasting purposes. There are two roadblocks that restrain us from using this data as such, first being the storage which restricts us from only storing the information based on the hardware constraints. Secondly, the computation required to process this data is highly expensive which makes it infeasible to work on them. Compressive sensing(CS)[2] is a signal process technique[11], through optimization, the sparsity of a signal can be exploited to recover it from far fewer samples than required by the Shannon-Nyquist sampling theorem. There are two conditions under which recovery is possible. The first one is sparsity which requires the signal to be sparse in some domain. The second one is incoherence which is applied through the isometric property which is sufficient for sparse signals[9][10]. To sustain these characteristics, preserving all attributes in the uncompressed domain would help any kind of in this field. However, existing dataset fallback in terms of continuous tracking of all the object present in the scene, very few video datasets have comprehensive continuous tracking of objects. To address these problems collectively, in this work we propose a new comprehensive video dataset, where the data is compressed using pixel-wise coded exposure [3] that resolves various other impediments.