 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemo-Pose: Depth-Monocular Modality Fusion For Object Pose Estimation
Mar 29, 2026Object pose estimation is a fundamental task in 3D vision with applications in robotics, AR/VR, and scene understanding. We address the challenge of category-level 9-DoF pose estimation (6D pose + 3Dsize) from RGB-D input, without relying on CAD models during inference. Existing depth-only methods achieve strong results but ignore semantic cues from RGB, while many RGB-D fusion models underperform due to suboptimal cross-modal fusion that fails to align semantic RGB cues with 3D geometric representations. We propose DeMo-Pose, a hybrid architecture that fuses monocular semantic features with depth-based graph convolutional representations via a novel multimodal fusion strategy. To further improve geometric reasoning, we introduce a novel Mesh-Point Loss (MPL) that leverages mesh structure during training without adding inference overhead. Our approach achieves real-time inference and significantly improves over state-of-the-art methods across object categories, outperforming the strong GPV-Pose baseline by 3.2\% on 3D IoU and 11.1\% on pose accuracy on the REAL275 benchmark. The results highlight the effectiveness of depth-RGB fusion and geometry-aware learning, enabling robust category-level 3D pose estimation for real-world applications.
Enhancing Classification with Hierarchical Scalable Query on Fusion Transformer
Feb 28, 2023Real-world vision based applications require fine-grained classification for various area of interest like e-commerce, mobile applications, warehouse management, etc. where reducing the severity of mistakes and improving the classification accuracy is of utmost importance. This paper proposes a method to boost fine-grained classification through a hierarchical approach via learnable independent query embeddings. This is achieved through a classification network that uses coarse class predictions to improve the fine class accuracy in a stage-wise sequential manner. We exploit the idea of hierarchy to learn query embeddings that are scalable across all levels, thus making this a relevant approach even for extreme classification where we have a large number of classes. The query is initialized with a weighted Eigen image calculated from training samples to best represent and capture the variance of the object. We introduce transformer blocks to fuse intermediate layers at which query attention happens to enhance the spatial representation of feature maps at different scales. This multi-scale fusion helps improve the accuracy of small-size objects. We propose a two-fold approach for the unique representation of learnable queries. First, at each hierarchical level, we leverage cluster based loss that ensures maximum separation between inter-class query embeddings and helps learn a better (query) representation in higher dimensional spaces. Second, we fuse coarse level queries with finer level queries weighted by a learned scale factor. We additionally introduce a novel block called Cross Attention on Multi-level queries with Prior (CAMP) Block that helps reduce error propagation from coarse level to finer level, which is a common problem in all hierarchical classifiers. Our method is able to outperform the existing methods with an improvement of ~11% at the fine-grained classification.
* 6 pages, 7 figures Published in IEEE ICCE 2023
Semantic Driven Energy based Out-of-Distribution Detection
Aug 23, 2022
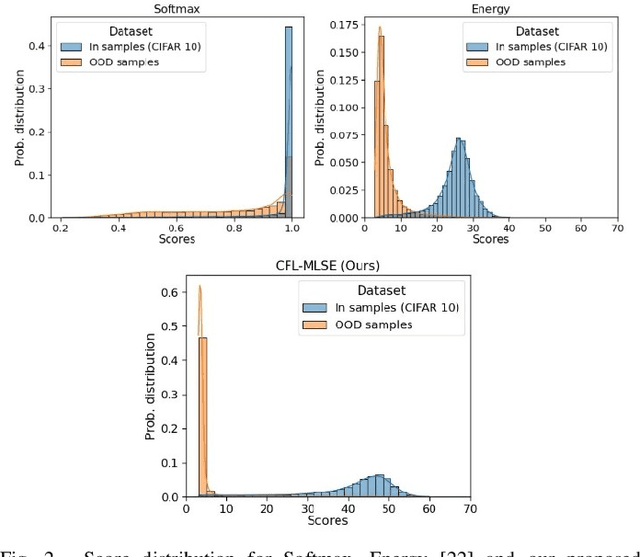
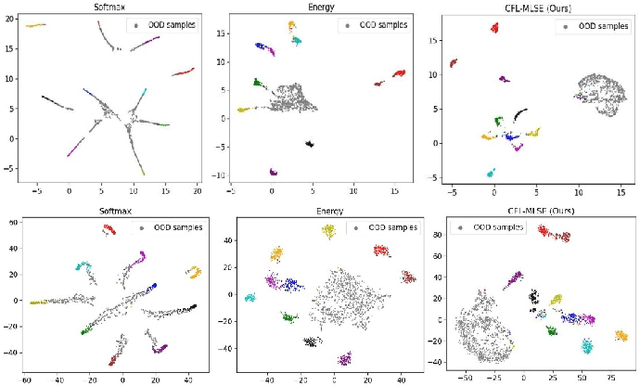

Detecting Out-of-Distribution (OOD) samples in real world visual applications like classification or object detection has become a necessary precondition in today's deployment of Deep Learning systems. Many techniques have been proposed, of which Energy based OOD methods have proved to be promising and achieved impressive performance. We propose semantic driven energy based method, which is an end-to-end trainable system and easy to optimize. We distinguish in-distribution samples from out-distribution samples with an energy score coupled with a representation score. We achieve it by minimizing the energy for in-distribution samples and simultaneously learn respective class representations that are closer and maximizing energy for out-distribution samples and pushing their representation further out from known class representation. Moreover, we propose a novel loss function which we call Cluster Focal Loss(CFL) that proved to be simple yet very effective in learning better class wise cluster center representations. We find that, our novel approach enhances outlier detection and achieve state-of-the-art as an energy-based model on common benchmarks. On CIFAR-10 and CIFAR-100 trained WideResNet, our model significantly reduces the relative average False Positive Rate(at True Positive Rate of 95%) by 67.2% and 57.4% respectively, compared to the existing energy based approaches. Further, we extend our framework for object detection and achieve improved performance.