 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideWalk -- Heterogeneous Data Fusion for Enhanced Learning -- A Multiclass Document Classification Case
Apr 25, 2024



One of the prime problems of computer science and machine learning is to extract information efficiently from large-scale, heterogeneous data. Text data, with its syntax, semantics, and even hidden information content, possesses an exceptional place among the data types in concern. The processing of the text data requires embedding, a method of translating the content of the text to numeric vectors. A correct embedding algorithm is the starting point for obtaining the full information content of the text data. In this work, a new embedding method based on the graph structure of the meaningful sentences is proposed. The design of the algorithm aims to construct an embedding vector that constitutes syntactic and semantic elements as well as the hidden content of the text data. The success of the proposed embedding method is tested in classification problems. Among the wide range of application areas, text classification is the best laboratory for embedding methods; the classification power of the method can be tested using dimensional reduction without any further processing. Furthermore, the method can be compared with different embedding algorithms and machine learning methods. The proposed method is tested with real-world data sets and eight well-known and successful embedding algorithms. The proposed embedding method shows significantly better classification for binary and multiclass datasets compared to well-known algorithms.
The Influence of Network Structural Preference on Node Classification and Link Prediction
Aug 09, 2022
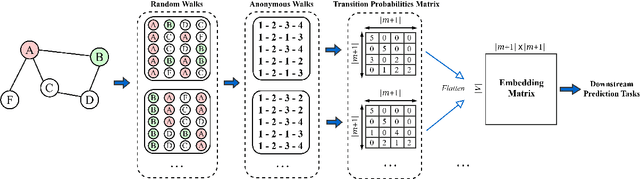

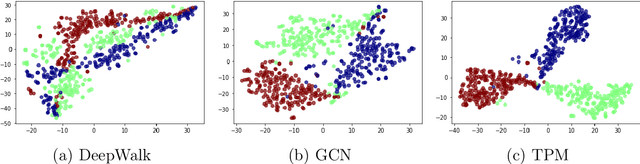
Recent advances in complex network analysis opened a wide range of possibilities for applications in diverse fields. The power of the network analysis depends on the node features. The topology-based node features are realizations of local and global spatial relations and node connectivity structure. Hence, collecting correct information on the node characteristics and the connectivity structure of the neighboring nodes plays the most prominent role in node classification and link prediction in complex network analysis. The present work introduces a new feature abstraction method, namely the Transition Probabilities Matrix (TPM), based on embedding anonymous random walks on feature vectors. The node feature vectors consist of transition probabilities obtained from sets of walks in a predefined radius. The transition probabilities are directly related to the local connectivity structure, hence correctly embedded onto feature vectors. The success of the proposed embedding method is tested on node identification/classification and link prediction on three commonly used real-world networks. In real-world networks, nodes with similar connectivity structures are common; Thus, obtaining information from similar networks for predictions on the new networks is the distinguishing characteristic that makes the proposed algorithm superior to the state-of-the-art algorithms in terms of cross-networks generalization tasks.
Degree-Based Random Walk Approach for Graph Embedding
Oct 21, 2021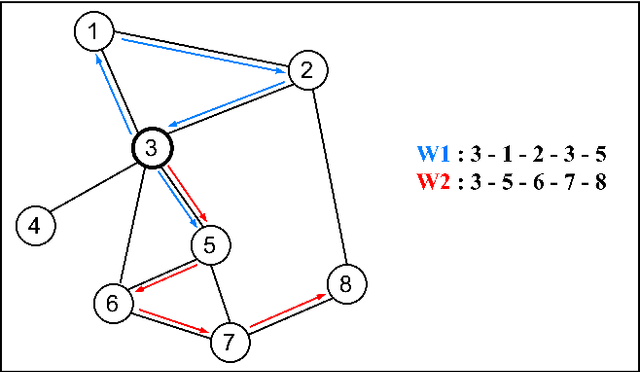
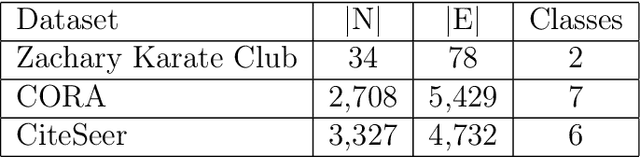
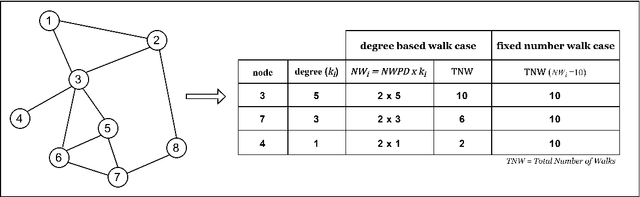
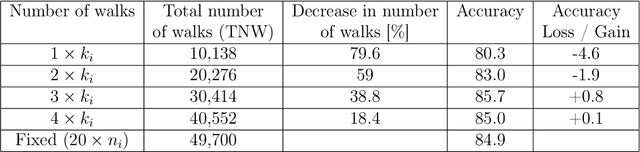
Graph embedding, representing local and global neighborhood information by numerical vectors, is a crucial part of the mathematical modeling of a wide range of real-world systems. Among the embedding algorithms, random walk-based algorithms have proven to be very successful. These algorithms collect information by creating numerous random walks with a redefined number of steps. Creating random walks is the most demanding part of the embedding process. The computation demand increases with the size of the network. Moreover, for real-world networks, considering all nodes on the same footing, the abundance of low-degree nodes creates an imbalanced data problem. In this work, a computationally less intensive and node connectivity aware uniform sampling method is proposed. In the proposed method, the number of random walks is created proportionally with the degree of the node. The advantages of the proposed algorithm become more enhanced when the algorithm is applied to large graphs. A comparative study by using two networks namely CORA and CiteSeer is presented. Comparing with the fixed number of walks case, the proposed method requires 50% less computational effort to reach the same accuracy for node classification and link prediction calculations.