 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent Moderation in TV Search: Balancing Policy Compliance, Relevance, and User Experience
May 22, 2025Millions of people rely on search functionality to find and explore content on entertainment platforms. Modern search systems use a combination of candidate generation and ranking approaches, with advanced methods leveraging deep learning and LLM-based techniques to retrieve, generate, and categorize search results. Despite these advancements, search algorithms can still surface inappropriate or irrelevant content due to factors like model unpredictability, metadata errors, or overlooked design flaws. Such issues can misalign with product goals and user expectations, potentially harming user trust and business outcomes. In this work, we introduce an additional monitoring layer using Large Language Models (LLMs) to enhance content moderation. This additional layer flags content if the user did not intend to search for it. This approach serves as a baseline for product quality assurance, with collected feedback used to refine the initial retrieval mechanisms of the search model, ensuring a safer and more reliable user experience.
Predicting Movie Hits Before They Happen with LLMs
May 05, 2025Addressing the cold-start issue in content recommendation remains a critical ongoing challenge. In this work, we focus on tackling the cold-start problem for movies on a large entertainment platform. Our primary goal is to forecast the popularity of cold-start movies using Large Language Models (LLMs) leveraging movie metadata. This method could be integrated into retrieval systems within the personalization pipeline or could be adopted as a tool for editorial teams to ensure fair promotion of potentially overlooked movies that may be missed by traditional or algorithmic solutions. Our study validates the effectiveness of this approach compared to established baselines and those we developed.
Improving Content Recommendation: Knowledge Graph-Based Semantic Contrastive Learning for Diversity and Cold-Start Users
Mar 27, 2024Addressing the challenges related to data sparsity, cold-start problems, and diversity in recommendation systems is both crucial and demanding. Many current solutions leverage knowledge graphs to tackle these issues by combining both item-based and user-item collaborative signals. A common trend in these approaches focuses on improving ranking performance at the cost of escalating model complexity, reducing diversity, and complicating the task. It is essential to provide recommendations that are both personalized and diverse, rather than solely relying on achieving high rank-based performance, such as Click-through Rate, Recall, etc. In this paper, we propose a hybrid multi-task learning approach, training on user-item and item-item interactions. We apply item-based contrastive learning on descriptive text, sampling positive and negative pairs based on item metadata. Our approach allows the model to better understand the relationships between entities within the knowledge graph by utilizing semantic information from text. It leads to more accurate, relevant, and diverse user recommendations and a benefit that extends even to cold-start users who have few interactions with items. We perform extensive experiments on two widely used datasets to validate the effectiveness of our approach. Our findings demonstrate that jointly training user-item interactions and item-based signals using synopsis text is highly effective. Furthermore, our results provide evidence that item-based contrastive learning enhances the quality of entity embeddings, as indicated by metrics such as uniformity and alignment.
A Quantitative and Qualitative Analysis of Schizophrenia Language
Jan 25, 2022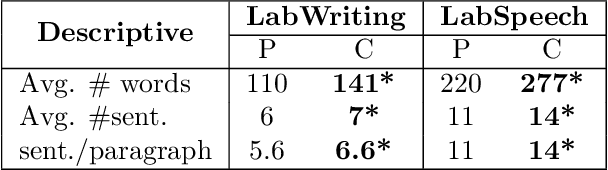
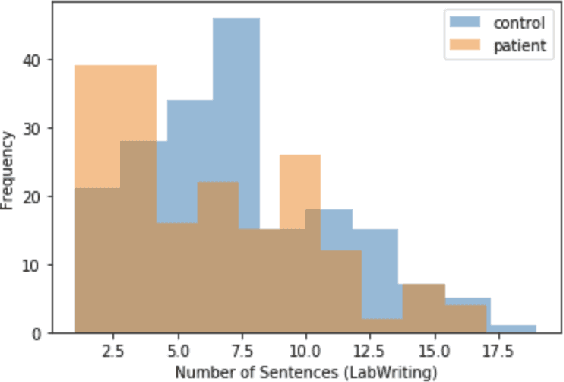
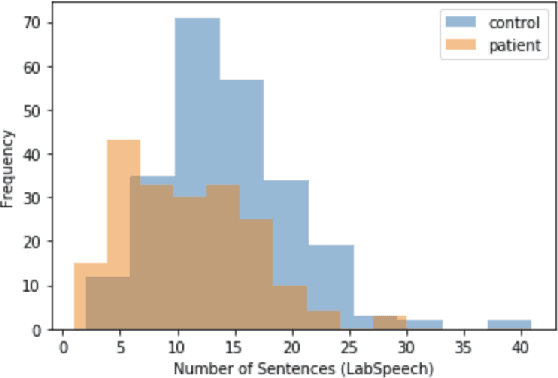
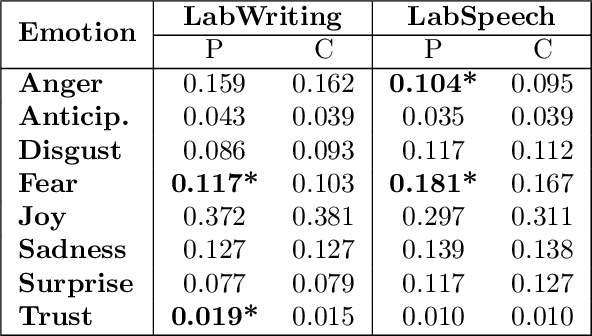
Schizophrenia is one of the most disabling mental health conditions to live with. Approximately one percent of the population has schizophrenia which makes it fairly common, and it affects many people and their families. Patients with schizophrenia suffer different symptoms: formal thought disorder (FTD), delusions, and emotional flatness. In this paper, we quantitatively and qualitatively analyze the language of patients with schizophrenia measuring various linguistic features in two modalities: speech and written text. We examine the following features: coherence and cohesion of thoughts, emotions, specificity, level of committed belief (LCB), and personality traits. Our results show that patients with schizophrenia score high in fear and neuroticism compared to healthy controls. In addition, they are more committed to their beliefs, and their writing lacks details. They score lower in most of the linguistic features of cohesion with significant p-values.
Rumor Detection and Classification for Twitter Data
Nov 25, 2019

With the pervasiveness of online media data as a source of information verifying the validity of this information is becoming even more important yet quite challenging. Rumors spread a large quantity of misinformation on microblogs. In this study we address two common issues within the context of microblog social media. First we detect rumors as a type of misinformation propagation and next we go beyond detection to perform the task of rumor classification. WE explore the problem using a standard data set. We devise novel features and study their impact on the task. We experiment with various levels of preprocessing as a precursor of the classification as well as grouping of features. We achieve and f-measure of over 0.82 in RDC task in mixed rumors data set and 84 percent in a single rumor data set using a two-step classification approach.